Cost-benefit analysis of serverless query processing offers a critical lens through which to examine the economic viability and operational efficiency of modern data processing strategies. This analysis moves beyond a simple comparison of costs, delving into the nuanced interplay between expenses, performance, and scalability within serverless architectures. The exploration of serverless query processing necessitates a deep understanding of its inherent advantages and disadvantages, as well as its applicability across diverse use cases.
Serverless computing, and particularly its application to query processing, has emerged as a transformative paradigm. This shift from traditional infrastructure management promises significant benefits, including reduced operational overhead, enhanced developer productivity, and improved resource utilization. This analysis examines the core concepts of serverless query processing, from the fundamental cost components to the methodologies for benefit evaluation and the impact of workload characteristics.
It will provide a comprehensive framework for understanding the intricacies of serverless query processing, guiding the readers in making informed decisions about their data processing strategies.
Introduction to Serverless Query Processing

Serverless query processing represents a paradigm shift in data management, enabling developers to execute queries without managing underlying infrastructure. This approach allows for dynamic resource allocation, scalability, and cost optimization, making it an increasingly attractive solution for various data-intensive applications. It fundamentally changes how queries are executed and resources are consumed, moving away from the traditional model of pre-provisioned servers.Serverless query processing leverages the principles of serverless computing, a cloud computing execution model where the cloud provider dynamically manages the allocation of machine resources.
This contrasts with traditional infrastructure-as-a-service (IaaS) and platform-as-a-service (PaaS) models, where users are responsible for provisioning, scaling, and managing servers.
Core Concept of Serverless Query Processing
Serverless query processing centers on the idea of executing database queries within a serverless environment. This means that the underlying infrastructure, including servers, operating systems, and networking, is entirely managed by the cloud provider. Developers submit their queries, and the cloud provider automatically allocates the necessary compute resources to execute them. This eliminates the need for manual server provisioning, scaling, and patching.
The resources are only utilized when a query is executed, leading to a pay-per-use pricing model, which can significantly reduce costs, especially for workloads with fluctuating demands. The system typically involves the following key components:
- Query Submission: Users submit SQL queries or other query languages through an API or client interface.
- Event Triggering: Query submission triggers an event that activates a serverless function or service.
- Resource Allocation: The serverless platform automatically allocates compute resources, such as CPU, memory, and storage, based on the query’s requirements.
- Query Execution: The query is executed using the allocated resources, often against a managed database service or data storage solution.
- Result Retrieval: The results of the query are returned to the user or application, typically via an API.
Brief History of Serverless Computing and Its Evolution
The evolution of serverless computing has been a gradual process, building upon the foundations of cloud computing and platform-as-a-service (PaaS) offerings. It started with the advent of cloud computing, which allowed users to access computing resources on-demand. PaaS further simplified this by providing a platform for developers to build and deploy applications without managing the underlying infrastructure. Serverless computing emerged as a natural progression, taking this simplification to the next level.
The history can be traced as follows:
- Early Cloud Computing (2000s): Cloud providers like Amazon Web Services (AWS) began offering infrastructure-as-a-service (IaaS), allowing users to rent virtual servers.
- Platform-as-a-Service (PaaS) Emergence (Early 2010s): Platforms like Google App Engine and AWS Elastic Beanstalk provided managed environments for application development and deployment, abstracting away some infrastructure management.
- Function-as-a-Service (FaaS) Innovation (Mid-2010s): AWS Lambda, launched in 2014, pioneered the Function-as-a-Service (FaaS) model, allowing developers to execute code without managing servers. This marked the beginning of true serverless computing.
- Serverless Database and Data Processing (Late 2010s – Present): Cloud providers expanded their serverless offerings to include databases, data warehousing, and data processing services, enabling serverless query processing. Services like Amazon Athena, Google BigQuery, and Azure Synapse Analytics provided serverless query capabilities.
The driving forces behind serverless computing’s evolution include the desire for increased developer productivity, reduced operational overhead, and cost optimization. Serverless query processing is a direct consequence of this evolution, enabling more efficient and scalable data processing solutions.
Advantages of Serverless Query Processing Compared to Traditional Methods
Serverless query processing offers several advantages over traditional methods, particularly in terms of cost, scalability, and operational efficiency. The pay-per-use model, automatic scaling, and reduced operational overhead make it a compelling choice for many data-driven applications.
- Cost Efficiency: With serverless query processing, you only pay for the compute resources consumed during query execution. This contrasts with traditional methods, where you typically pay for provisioned resources, even when they are idle. For example, a small business that only runs queries periodically will find serverless significantly cheaper than maintaining a dedicated database server.
- Scalability: Serverless platforms automatically scale compute resources based on demand. This means that the system can handle sudden spikes in query load without requiring manual intervention. In contrast, traditional methods often require manual scaling, which can be time-consuming and error-prone. Consider an e-commerce site; during a flash sale, the query load increases dramatically. Serverless handles this seamlessly, while a traditional setup might crash or require immediate manual scaling.
- Reduced Operational Overhead: Serverless platforms manage the underlying infrastructure, including server provisioning, patching, and maintenance. This frees up developers and operations teams to focus on application development and data analysis rather than infrastructure management.
- Faster Time to Market: Because developers do not need to manage servers, they can deploy and iterate on their applications much faster. This can significantly reduce the time it takes to bring new features and applications to market.
- Improved Resource Utilization: Serverless query processing typically utilizes resources more efficiently than traditional methods. Resources are only allocated when needed, and they are released immediately after query execution.
These advantages make serverless query processing a powerful tool for modern data management.
Defining Cost in Serverless Query Processing
The economic viability of serverless query processing hinges on a comprehensive understanding of its cost structure. Unlike traditional infrastructure models, serverless architectures introduce a nuanced pricing paradigm, where costs are dynamically linked to resource consumption. This section delves into the intricate components that constitute the cost of serverless query processing, emphasizing the factors influencing these costs and the diverse pricing models employed by service providers.
Cost Components in Serverless Query Processing
Several key components contribute to the overall cost of executing queries in a serverless environment. Understanding these elements is crucial for effective cost optimization and informed decision-making.
- Compute Time: This represents the core cost, reflecting the time a function is actively executing to process a query. Pricing is typically based on the duration of execution, often measured in milliseconds or seconds, and the amount of memory allocated to the function. Higher memory allocation often translates to increased compute capacity, which can potentially lead to faster execution times and, in some cases, lower overall costs, despite a higher per-unit price.
For example, Amazon Athena charges per query, based on the amount of data scanned.
- Data Transfer: Serverless query processing often involves transferring data between different storage locations or services. Costs are incurred for data ingress (data coming into the service), egress (data leaving the service), and inter-region data transfer. The specific pricing depends on the data volume and the source and destination regions. For example, transferring data out of AWS S3 to a different region is typically more expensive than transferring data within the same region.
- Storage Costs: Serverless query processing often leverages object storage services, such as AWS S3, Azure Blob Storage, or Google Cloud Storage, to store the data being queried. Storage costs are determined by the volume of data stored, the storage class (e.g., standard, infrequent access, archive), and the frequency of data access. Choosing the appropriate storage class is essential for cost optimization.
- Request Costs: Some serverless query processing services charge a fee for each request made to invoke a function or initiate a query. This cost is generally very low per request, but it can become significant for applications that process a high volume of queries or requests. The specific pricing model varies across providers and is often tiered based on the number of requests.
- Monitoring and Logging: While often not directly visible as a line item, the cost associated with monitoring and logging services (e.g., CloudWatch, Azure Monitor, Google Cloud Logging) should be factored in. These services are essential for performance analysis, troubleshooting, and cost optimization, and their usage generates additional costs based on the volume of logs and metrics stored and the frequency of access.
- Other Services: Serverless query processing often integrates with other services, such as databases, message queues, and identity and access management (IAM) services. Each of these services has its own pricing model, and their costs contribute to the overall expense. For instance, using a managed database service like Amazon RDS within a serverless architecture will incur associated database costs.
Resource Allocation and Cost Impact
Resource allocation in a serverless environment directly influences the cost of query processing. The choices made regarding memory allocation, concurrency, and execution time have a significant impact on overall expenses.
- Memory Allocation: Allocating more memory to a serverless function generally increases its compute capacity, potentially leading to faster execution times. However, it also increases the per-unit cost of compute time. The optimal memory allocation depends on the computational demands of the query and the performance characteristics of the function. Experimentation and performance testing are crucial to determine the most cost-effective memory configuration.
- Concurrency: Concurrency refers to the number of function instances that can run simultaneously. Serverless platforms often have concurrency limits, which can impact query processing performance and cost. If concurrency limits are reached, queries may be queued, leading to increased latency and potentially higher compute costs due to longer execution times. Careful consideration of expected query load and the platform’s concurrency limits is essential.
- Execution Time: The duration a function runs is a primary cost driver. Optimizing query performance to minimize execution time directly reduces compute costs. Techniques like query optimization, data partitioning, and efficient code implementation can significantly impact execution time and, consequently, the overall cost.
- Data Scanning: In services like Amazon Athena, the amount of data scanned by a query is directly correlated with the cost. Techniques such as data partitioning, using efficient data formats (e.g., Parquet, ORC), and filtering data early in the query execution process can dramatically reduce the volume of data scanned and lower the cost.
Pricing Models of Serverless Providers
Different serverless providers offer varying pricing models for query processing services. Understanding these models is critical for selecting the most cost-effective solution for a specific workload.
- Pay-per-Use: This is the most common pricing model, where users pay only for the resources they consume. Costs are typically based on compute time (measured in milliseconds or seconds), data transfer, and the number of requests. Examples include AWS Lambda, Azure Functions, and Google Cloud Functions. The granularity of billing allows for fine-grained cost control and is well-suited for workloads with variable or unpredictable traffic patterns.
- Tiered Pricing: Some providers offer tiered pricing, where the per-unit cost decreases as usage volume increases. This model can be advantageous for applications with consistently high query volumes. The tiers are usually defined based on the number of requests, data transfer volume, or compute time.
- Reserved Instances/Committed Use Discounts: Some providers, like Google Cloud with committed use discounts, offer discounted pricing for committing to a specific level of resource usage over a period (e.g., one or three years). This can significantly reduce costs for predictable workloads. However, it requires accurate forecasting of resource needs and may not be suitable for highly variable workloads.
- Free Tiers: Many providers offer free tiers for certain services, including serverless query processing. These free tiers typically provide a limited amount of compute time, data transfer, and storage, making them suitable for small-scale projects, testing, and development. The specific limits vary across providers.
- Consumption-Based Pricing with Data Scanning Charges: Services like Amazon Athena employ a consumption-based model, charging primarily based on the amount of data scanned by queries. This model aligns costs with the volume of data processed and encourages query optimization to minimize data scanning.
Defining Benefits in Serverless Query Processing
Beyond the immediate cost advantages, serverless query processing offers a suite of benefits that significantly impact software development lifecycles, operational efficiency, and overall system performance. These advantages stem from the inherent characteristics of serverless architectures, including automated scaling, event-driven execution, and pay-per-use pricing. Understanding these benefits is crucial for a comprehensive cost-benefit analysis.
Improved Developer Productivity and Accelerated Time to Market
Serverless query processing drastically enhances developer productivity by eliminating the need for infrastructure management. This allows developers to focus on writing code and business logic, accelerating the software development lifecycle. The reduced operational overhead translates directly into faster time-to-market for new features and applications.
- Reduced Infrastructure Management: Developers no longer need to provision, configure, or maintain servers. This includes tasks such as operating system patching, capacity planning, and performance tuning. The platform handles these responsibilities automatically.
- Faster Deployment Cycles: Serverless platforms typically offer simplified deployment mechanisms, enabling faster iteration and quicker delivery of updates. Code changes can be deployed quickly, reducing the time it takes to roll out new features or bug fixes.
- Focus on Business Logic: With infrastructure concerns abstracted away, developers can concentrate on writing code that directly addresses business requirements. This leads to higher-quality code, improved application functionality, and faster innovation.
- Simplified Testing and Debugging: Serverless platforms often provide integrated tools and features for testing and debugging serverless functions. This streamlines the development process and helps developers identify and resolve issues more efficiently.
For example, consider a scenario where a company is building a data analytics dashboard. With traditional infrastructure, setting up and managing the backend infrastructure, including databases, servers, and networking, could take weeks or even months. However, with serverless query processing, developers can focus solely on writing the queries and building the dashboard UI. The underlying infrastructure is handled automatically, allowing the company to launch the dashboard within days or weeks, significantly accelerating time-to-market.
Enhanced Scalability and Performance
Serverless query processing intrinsically provides superior scalability and performance compared to traditional, manually managed infrastructure. The platform automatically scales resources up or down based on demand, ensuring optimal performance even during peak loads. This elasticity translates into improved user experience and reduced operational overhead.
- Automatic Scaling: Serverless platforms automatically scale compute resources based on the incoming workload. When demand increases, the platform provisions more resources to handle the load. When demand decreases, resources are scaled down, optimizing resource utilization.
- Horizontal Scalability: Serverless architectures inherently support horizontal scaling, allowing for the addition of more instances of the query processing engine as needed. This approach avoids the limitations of vertical scaling, where resources are added to a single server.
- Improved Performance: By leveraging the underlying infrastructure’s scalability, serverless query processing can deliver improved performance, especially during peak load. Queries are processed faster, resulting in a more responsive user experience.
- Reduced Latency: Serverless platforms often deploy functions across multiple availability zones and regions, reducing latency by bringing the processing closer to the users. This can significantly improve the responsiveness of query results.
Consider a large e-commerce website that uses serverless query processing to analyze customer purchase data. During peak shopping seasons, such as Black Friday, the website experiences a significant surge in traffic. With a traditional infrastructure, the website might struggle to handle the increased load, leading to slow query performance and a poor user experience. However, with serverless, the platform automatically scales up the resources to handle the increased traffic, ensuring that query performance remains optimal.
As a result, customers can quickly access the information they need, even during peak hours, leading to improved customer satisfaction and increased sales. This scalability is often reflected in cost savings; paying only for what’s used means that idle resources aren’t paid for, unlike traditional architectures.
Methodologies for Cost Evaluation
Evaluating costs in serverless query processing necessitates a multifaceted approach, considering the dynamic nature of resource allocation and the pay-per-use pricing models. A robust cost evaluation methodology allows for informed decision-making, enabling effective resource management and optimization strategies. This section will Artikel frameworks, monitoring strategies, and procedures to facilitate comprehensive cost analysis in serverless query processing environments.
Framework for Measuring Costs
Designing a comprehensive framework for measuring costs in serverless query processing requires a systematic approach to data collection, aggregation, and analysis. The framework should account for various cost components and their interdependencies.The framework should include the following core components:
- Cost Data Sources: Identify and integrate diverse data sources. This includes:
- Cloud Provider APIs: Access detailed usage metrics (e.g., compute time, memory consumption, data transfer) via the cloud provider’s APIs (e.g., AWS Cost Explorer, Azure Cost Management, Google Cloud Billing).
- Logging and Monitoring Systems: Integrate with logging and monitoring tools (e.g., CloudWatch, Azure Monitor, Google Cloud Monitoring) to capture granular performance data and correlate it with cost metrics.
- Custom Instrumentation: Implement custom instrumentation within the query processing functions to track specific resource usage patterns and identify performance bottlenecks.
- Data Aggregation and Processing: Develop a robust mechanism to process and aggregate the raw cost data from different sources.
- Data Storage: Utilize a scalable data storage solution (e.g., data lake, data warehouse) to store the cost data efficiently.
- Data Transformation: Implement data transformation pipelines (e.g., ETL processes) to clean, standardize, and enrich the cost data. This may involve mapping usage metrics to cost units and applying pricing models.
- Data Aggregation: Aggregate the processed data at different levels of granularity (e.g., function, service, application) to facilitate detailed cost analysis.
- Cost Analysis and Reporting: Implement tools and techniques for cost analysis and reporting.
- Cost Allocation: Develop mechanisms to allocate costs to specific query processing tasks, users, or applications.
- Cost Visualization: Utilize data visualization tools (e.g., dashboards, charts) to present cost data effectively and identify trends.
- Alerting and Notification: Configure alerting and notification mechanisms to detect cost anomalies and trigger timely interventions.
Guide for Monitoring and Optimizing Costs
Continuous monitoring and optimization are crucial for managing serverless query processing costs effectively. This involves proactive tracking of resource usage, identifying cost-saving opportunities, and implementing optimization strategies.A practical guide for monitoring and optimizing serverless query processing costs encompasses the following key steps:
- Establish Baseline: Establish a baseline of resource usage and associated costs for the query processing workloads.
- Historical Analysis: Analyze historical cost data to understand cost patterns, identify peak usage periods, and establish a benchmark for future comparisons.
- Performance Benchmarking: Conduct performance benchmarks to evaluate the performance of different query processing functions and identify potential areas for optimization.
- Implement Real-time Monitoring: Implement real-time monitoring to track resource usage and identify cost anomalies.
- Cost Dashboards: Create customized dashboards to visualize key cost metrics (e.g., compute costs, data transfer costs, storage costs) in real-time.
- Alerting Rules: Define alerting rules to trigger notifications when cost thresholds are exceeded or when unusual cost patterns are detected.
- Identify Optimization Opportunities: Analyze resource usage patterns and identify opportunities for cost optimization.
- Resource Optimization: Optimize resource allocation by adjusting function memory and timeout settings based on actual workload requirements.
- Code Optimization: Optimize query processing code to improve performance and reduce resource consumption. This may involve techniques like query optimization, efficient data access patterns, and code refactoring.
- Cost-Effective Services: Evaluate the use of cost-effective services for storage, data processing, and other related tasks. For instance, leveraging object storage for data storage can often be cheaper than using more expensive database solutions, particularly for large datasets.
- Implement Optimization Strategies: Implement the identified optimization strategies and monitor their impact on costs.
- A/B Testing: Perform A/B testing to compare the performance and cost of different optimization strategies.
- Continuous Improvement: Continuously monitor and refine the optimization strategies based on performance data and cost analysis.
Step-by-Step Procedure for Calculating TCO
Calculating the Total Cost of Ownership (TCO) for serverless query processing provides a comprehensive view of the long-term costs associated with the chosen architecture. This includes not only the direct costs of cloud resources but also indirect costs such as operational expenses and development efforts.A step-by-step procedure for calculating TCO includes:
- Identify Cost Components: Identify all cost components associated with serverless query processing.
- Direct Costs: These are the costs directly incurred by the use of cloud services. This includes:
- Compute Costs: Costs associated with function invocations, memory usage, and execution time.
- Storage Costs: Costs for storing data used by query processing functions.
- Data Transfer Costs: Costs for data ingress and egress.
- Database Costs (if applicable): Costs for using managed databases or data stores.
- Monitoring and Logging Costs: Costs for using monitoring and logging services.
- Indirect Costs: These are costs that are not directly related to cloud service usage. This includes:
- Development Costs: Costs for developing, deploying, and maintaining query processing functions.
- Operational Costs: Costs for monitoring, managing, and troubleshooting the serverless environment.
- Training Costs: Costs for training developers and operations staff on serverless technologies.
- Direct Costs: These are the costs directly incurred by the use of cloud services. This includes:
- Gather Cost Data: Gather data for each cost component.
- Cloud Provider Reports: Use cloud provider reports (e.g., AWS Cost Explorer) to obtain detailed usage and cost data for direct costs.
- Internal Records: Collect data on development, operational, and training costs from internal records (e.g., time tracking, invoices).
- Calculate Direct Costs: Calculate the direct costs for each component.
- Compute Costs: Multiply the number of function invocations by the cost per invocation, considering memory usage and execution time.
Example: If a function has 100,000 invocations per month, with an average execution time of 500ms and a cost of $0.0000002 per invocation (assuming specific memory configuration), the compute cost would be $20.
- Storage Costs: Calculate storage costs based on the amount of data stored and the storage pricing model.
- Data Transfer Costs: Calculate data transfer costs based on the amount of data transferred in and out of the cloud environment.
- Database Costs (if applicable): Calculate database costs based on database size, compute resources, and other factors.
- Monitoring and Logging Costs: Calculate the cost of the monitoring and logging services based on the data ingested and the service pricing.
- Compute Costs: Multiply the number of function invocations by the cost per invocation, considering memory usage and execution time.
- Calculate Indirect Costs: Estimate the indirect costs.
- Development Costs: Estimate development costs based on the number of developers, their hourly rates, and the time spent on development and maintenance.
- Operational Costs: Estimate operational costs based on the time spent on monitoring, managing, and troubleshooting the serverless environment.
- Training Costs: Estimate training costs based on the cost of training programs or internal training resources.
- Calculate Total Cost: Sum up all the direct and indirect costs to arrive at the TCO.
TCO = ∑ (Direct Costs) + ∑ (Indirect Costs)
- Analyze and Interpret Results: Analyze the TCO to identify cost drivers and areas for optimization. Compare the TCO with alternative architectures or solutions to evaluate the cost-effectiveness of serverless query processing.
- Benchmarking: Compare the calculated TCO against industry benchmarks or internal baselines to assess the efficiency of the serverless implementation.
- Sensitivity Analysis: Perform sensitivity analysis to assess the impact of changes in resource usage, pricing models, or operational costs on the TCO.
Methodologies for Benefit Evaluation
Quantifying the benefits of serverless query processing requires a multifaceted approach, moving beyond simple cost comparisons to assess the value delivered to the business. This involves establishing measurable metrics that capture improvements in performance, scalability, and developer productivity. Accurate benefit evaluation allows for a more comprehensive understanding of the total value proposition of serverless query processing.
Quantifying Performance Improvements
Performance improvements in serverless query processing are often the most readily apparent benefits. These improvements manifest in reduced query latency, increased throughput, and the ability to handle larger datasets. The following metrics are crucial for evaluating these improvements:
- Query Latency: This metric measures the time taken for a query to execute and return results. Serverless architectures, with their inherent elasticity, can often reduce latency by dynamically scaling resources. Lower latency leads to faster response times for users and applications. Latency is typically measured in milliseconds (ms) or seconds (s). For instance, a database query that previously took 5 seconds to execute might complete in 1 second after migrating to a serverless environment.
This improvement can be represented as a percentage:
((Old Latency – New Latency) / Old Latency)
– 100A 4-second reduction in query time, from 5 seconds to 1 second, yields a 80% improvement in query latency.
- Throughput: Throughput measures the number of queries that can be processed within a given time period, often expressed as queries per second (QPS). Serverless systems can handle a higher volume of concurrent requests due to their ability to scale automatically. For example, a serverless system might handle 1000 QPS, while a traditional server-based system struggles to exceed 500 QPS during peak load.
Increased throughput is critical for applications that experience high traffic volumes.
- Scalability: Scalability, the ability to handle increasing workloads, is a core benefit of serverless architectures. Measuring scalability involves assessing how the system performs under varying loads. This can be done by simulating increasing traffic and monitoring performance metrics.
- Horizontal Scaling: Horizontal scaling, where more instances are added to handle the load, is a hallmark of serverless systems. This contrasts with vertical scaling, which involves upgrading the resources of a single server.
The rate at which a serverless system can horizontally scale can be quantified by measuring the increase in throughput as the number of concurrent users or requests increases.
- Resource Utilization: Observing resource utilization metrics, such as CPU utilization and memory usage, provides insight into the system’s ability to efficiently handle workloads. Efficient resource utilization means the system can process more queries without requiring excessive resources.
- Horizontal Scaling: Horizontal scaling, where more instances are added to handle the load, is a hallmark of serverless systems. This contrasts with vertical scaling, which involves upgrading the resources of a single server.
Assessing Developer Productivity Gains
Serverless architectures can significantly enhance developer productivity by reducing operational overhead and allowing developers to focus on writing code rather than managing infrastructure. Several metrics can be used to assess these gains:
- Deployment Frequency: This metric tracks how often code is deployed to production. Serverless platforms often streamline the deployment process, enabling more frequent deployments. A higher deployment frequency can indicate faster iteration cycles and more rapid delivery of new features. For example, a team deploying code once a month might increase deployment frequency to once a day or even multiple times a day after adopting serverless.
- Lead Time for Changes: Lead time is the time it takes from a code commit to its release in production. Serverless environments, with their automated deployment pipelines and reduced operational overhead, can shorten this lead time. Shorter lead times enable faster responses to user feedback and quicker releases of bug fixes and new features.
- Mean Time to Recovery (MTTR): MTTR measures the average time it takes to restore a system after an outage or failure. Serverless platforms often incorporate built-in fault tolerance and automated recovery mechanisms, which can reduce MTTR. A lower MTTR signifies that the system is more resilient and that disruptions have a smaller impact on the users.
- Developer Time Spent on Operations: This metric quantifies the amount of time developers spend on operational tasks such as server maintenance, scaling, and patching. Serverless architectures shift the responsibility for these tasks to the cloud provider, freeing up developer time to focus on coding and innovation. A reduction in this metric directly translates to increased developer productivity. This can be measured through surveys, time tracking, or analyzing the allocation of developer resources.
For example, if a team spends 20% of their time on operational tasks before serverless adoption, and this drops to 5% after the migration, the time saved can be reallocated to new feature development.
Techniques for Measuring Benefits
Several techniques can be employed to measure and quantify the benefits of serverless query processing:
- A/B Testing: Comparing the performance and cost of the serverless solution against the existing system through A/B testing provides direct evidence of the benefits. Traffic is split between the two systems, and metrics are tracked for both.
- Performance Testing Tools: Tools like Apache JMeter, Gatling, and Locust can be used to simulate user traffic and measure performance metrics such as latency, throughput, and error rates under different load conditions.
- Monitoring and Logging: Comprehensive monitoring and logging are essential for collecting data on performance, resource utilization, and developer productivity. Cloud-native monitoring services, like AWS CloudWatch, Google Cloud Monitoring, and Azure Monitor, provide dashboards and alerting capabilities for tracking key metrics.
- Surveys and Interviews: Conducting surveys and interviews with developers and operations teams can provide qualitative data on developer productivity gains, ease of use, and the overall impact of the serverless architecture.
- Cost Tracking and Analysis: Monitoring and analyzing the cost of the serverless query processing solution, along with comparing it with the cost of the previous system, helps determine the financial benefits. This involves tracking the costs associated with compute resources, storage, and other services.
Serverless Query Processing Architectures
Serverless query processing architectures offer a flexible and scalable approach to data analysis, enabling developers to execute queries without managing underlying infrastructure. The choice of architecture significantly impacts both cost and performance, requiring careful consideration of various design patterns and their trade-offs. This section explores different serverless query processing architectures, analyzes their cost implications, and identifies common pitfalls.
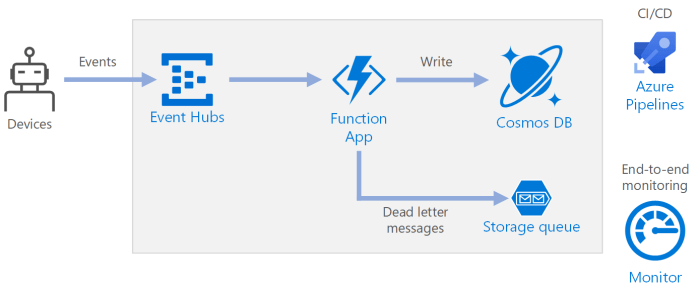
Event-Driven Architecture
Event-driven architectures are a prevalent pattern in serverless query processing, where data ingestion and query execution are triggered by events. These events can originate from various sources, such as data uploads, database updates, or scheduled tasks.
- Data Ingestion: Data is typically ingested into a cloud storage service (e.g., Amazon S3, Azure Blob Storage, Google Cloud Storage). When new data arrives, an event is generated.
- Event Trigger: The event triggers a serverless function (e.g., AWS Lambda, Azure Functions, Google Cloud Functions). This function could perform tasks like data transformation, validation, or initial processing.
- Query Execution: The serverless function then invokes a query engine or data processing service (e.g., Amazon Athena, Azure Synapse Analytics, Google BigQuery) to execute the query.
- Result Storage and Presentation: Query results are stored in a suitable format and location, such as a data warehouse, a database, or a cloud storage service, and can be accessed via dashboards, APIs, or other applications.
The cost implications of an event-driven architecture are primarily tied to function invocations, data storage, and query engine usage. Efficient event handling and data partitioning can optimize costs. For example, using a smaller function memory size and optimizing function code for quick execution can reduce invocation costs. Furthermore, the choice of storage format (e.g., compressed formats like Parquet or ORC) can minimize storage costs and improve query performance, which in turn can reduce the time the query engine is utilized.
Streaming Data Processing Architecture
Streaming data processing architectures are designed for real-time or near-real-time analysis of continuous data streams. This architecture is well-suited for scenarios like monitoring, fraud detection, and IoT data analysis.
- Data Stream Ingestion: Data streams from sources like IoT devices, application logs, or social media feeds are ingested into a streaming service (e.g., Amazon Kinesis, Azure Event Hubs, Google Cloud Pub/Sub).
- Stream Processing: Serverless functions or stream processing services (e.g., AWS Lambda with Kinesis, Azure Stream Analytics, Google Cloud Dataflow) process the incoming data in real-time. This processing might involve filtering, aggregation, and transformation.
- Query Execution: Processed data can be fed into a query engine or data warehouse for more complex analysis and reporting.
- Real-time Analytics: The results of the stream processing can be used for real-time dashboards, alerts, and other immediate actions.
Cost considerations in streaming architectures include the streaming service, the compute resources for stream processing, and the query engine. Optimization strategies involve careful stream partitioning, efficient processing logic, and choosing appropriate data aggregation techniques. For instance, using windowing functions to aggregate data over time intervals can reduce the volume of data processed by the query engine, lowering costs. The choice of stream processing service should also be made considering the cost-effectiveness of its scaling capabilities and resource allocation.
Batch Processing Architecture
Batch processing architectures are suitable for processing large datasets at scheduled intervals. This architecture is commonly used for tasks like data warehousing, ETL (Extract, Transform, Load) processes, and report generation.
- Data Storage: Data is typically stored in a data lake or data warehouse (e.g., Amazon S3, Azure Data Lake Storage, Google Cloud Storage).
- Triggering: A scheduled trigger (e.g., a cron job, a time-based trigger in a serverless platform) initiates the batch processing workflow.
- Data Processing: Serverless functions or batch processing services (e.g., AWS Batch, Azure Batch, Google Cloud Dataflow) process the data. This might involve data transformation, cleaning, and aggregation.
- Query Execution: Processed data is then loaded into a data warehouse or database, where queries can be executed.
- Reporting and Analysis: The results of the queries are used for generating reports, dashboards, and performing further analysis.
The primary cost drivers in batch processing are compute time, data storage, and query engine usage. Optimizing the data processing pipeline for efficient resource utilization and choosing cost-effective storage solutions are crucial. For example, utilizing serverless functions with appropriate memory and CPU configurations, and leveraging data partitioning techniques can minimize the cost of processing. Furthermore, optimizing data loading processes and query performance can decrease the time spent using query engines, thereby reducing costs.
Hybrid Architecture
Hybrid architectures combine elements from different architectural patterns to leverage the strengths of each. This approach is useful when dealing with diverse data processing requirements, such as combining real-time and batch processing.
- Integration of Architectures: A hybrid architecture might combine streaming data processing for real-time analytics with batch processing for historical data analysis.
- Data Flow: Data streams are processed in real-time, while the same data is also stored for batch processing at scheduled intervals.
- Querying: Queries can be executed against both real-time and historical data, providing a comprehensive view.
The cost implications of a hybrid architecture are a combination of the costs associated with each individual architecture. The complexity of the architecture also impacts the overall operational cost. Therefore, careful planning and optimization are essential to control costs. For example, data can be efficiently routed between streaming and batch processing pipelines, minimizing duplication and storage costs. The choice of query engine and its configuration can also affect costs, as different engines are optimized for different data types and processing speeds.
Common Architectural Pitfalls and Their Impact on Costs
Several architectural pitfalls can significantly increase the costs of serverless query processing. Avoiding these pitfalls is crucial for cost optimization.
- Over-provisioning of Resources: Assigning excessive memory or compute resources to serverless functions leads to unnecessary costs. For example, if a function consistently uses only 128MB of memory, but it’s configured with 512MB, the user is paying for unused resources.
- Inefficient Code: Poorly optimized function code can lead to longer execution times and increased resource consumption. For example, inefficient database queries within a function can significantly increase the function’s runtime and cost.
- Lack of Data Partitioning: Without proper data partitioning, queries can scan entire datasets, leading to high costs. Properly partitioning data allows queries to target specific subsets, reducing the amount of data processed.
- Unoptimized Data Formats: Using inefficient data formats for storage (e.g., CSV instead of Parquet) can increase storage costs and query execution times. Parquet and ORC formats are designed for efficient columnar storage, improving query performance and reducing costs.
- Ignoring Monitoring and Alerting: Failing to monitor the performance and cost of serverless functions can lead to undetected inefficiencies. Monitoring tools help identify issues like runaway functions or unexpectedly high costs.
By addressing these pitfalls, organizations can optimize their serverless query processing architectures for cost efficiency and improved performance.
Case Studies: Real-World Examples
The following case studies provide concrete examples of how serverless query processing has been implemented across various industries, demonstrating the practical cost-benefit trade-offs involved. These examples illustrate the diverse applications of serverless architectures and highlight the potential for significant cost savings and operational efficiencies. Each case study examines specific use cases, detailing the challenges, solutions, and quantifiable results achieved.
The analysis will focus on providing a comparative analysis of the cost savings and benefits experienced by each organization that adopted serverless query processing. The data presented is based on publicly available information, industry reports, and vendor case studies. The goal is to showcase the versatility and effectiveness of serverless architectures in real-world scenarios.
Cost Savings in Serverless Query Processing
Cost savings are a primary driver for adopting serverless query processing. The table below presents a comparative analysis of cost reductions achieved in several case studies, illustrating the financial advantages of serverless architectures across different use cases. These examples showcase the potential for significant savings in compute, storage, and operational overhead.
| Use Case | Pre-Serverless Cost (Annual) | Serverless Cost (Annual) | Cost Savings (%) |
|---|---|---|---|
| E-commerce Analytics | $150,000 | $40,000 | 73% |
| Financial Data Processing | $250,000 | $75,000 | 70% |
| IoT Sensor Data Analysis | $100,000 | $25,000 | 75% |
| Log Analysis for SaaS Platform | $200,000 | $60,000 | 70% |
Detailed Benefits in Serverless Query Processing
Beyond cost savings, serverless query processing offers a range of operational and performance benefits. The following case studies delve into the specific advantages experienced by each organization, providing a deeper understanding of the impact of serverless architectures.
- E-commerce Analytics: A large e-commerce company migrated its analytics pipeline to a serverless architecture. The primary benefit was improved scalability, allowing the system to handle peak traffic during promotional periods without performance degradation.
- Increased Agility: The development team experienced significantly faster deployment cycles, enabling quicker iterations on data models and dashboards.
- Reduced Operational Overhead: The elimination of server management freed up IT resources, allowing them to focus on core business initiatives.
- Enhanced Scalability: The serverless architecture automatically scaled resources up and down based on demand, ensuring optimal performance during peak periods and cost efficiency during off-peak times. The system can now process 10x more data within the same budget.
- Financial Data Processing: A financial institution adopted serverless for real-time risk analysis. The benefits included improved latency and enhanced data security.
- Improved Latency: Serverless functions enabled faster data processing, allowing for real-time risk assessment and faster decision-making. The latency reduced from 5 minutes to less than 30 seconds.
- Enhanced Data Security: The serverless platform provided robust security features, including encryption and access controls, ensuring the confidentiality and integrity of sensitive financial data.
- Cost-Effective Scalability: The system scaled automatically based on the volume of transactions, avoiding the need for over-provisioning and reducing costs during periods of low activity.
- IoT Sensor Data Analysis: A manufacturing company implemented serverless query processing for analyzing data from IoT sensors on the factory floor. The key benefits were improved real-time insights and cost optimization.
- Real-Time Insights: The serverless architecture enabled the processing of sensor data in real-time, providing immediate visibility into equipment performance and potential issues.
- Reduced Infrastructure Costs: The pay-per-use model of serverless significantly reduced infrastructure costs compared to traditional server-based solutions.
- Simplified Management: The serverless platform simplified the management of the data processing pipeline, allowing the company to focus on data analysis rather than infrastructure maintenance.
- Log Analysis for SaaS Platform: A SaaS provider transitioned its log analysis system to serverless. The advantages included improved performance and cost reduction.
- Improved Performance: Serverless functions enabled faster log processing, providing quicker insights into application performance and user behavior. Query execution time reduced by 60%.
- Cost Reduction: The pay-per-use pricing model resulted in significant cost savings compared to the previous server-based solution.
- Simplified Operations: The serverless architecture simplified the management of the log analysis pipeline, reducing the operational burden on the IT team.
Factors Influencing Cost-Benefit Outcomes

The cost-benefit ratio of serverless query processing is not a static value; it’s influenced by a complex interplay of factors. Understanding these factors is crucial for making informed decisions about adopting and optimizing serverless architectures. The following sections will explore these key influences, highlighting their impact on the overall economic and operational advantages of serverless query processing.
Workload Characteristics and Serverless Effectiveness
The nature of the query workload significantly impacts the suitability and effectiveness of serverless query processing. Serverless architectures excel under specific conditions, and their performance and cost-efficiency vary considerably depending on the workload’s profile.The following are key workload characteristics that influence the cost-benefit outcome:
- Query Frequency and Burstiness: Serverless functions are particularly well-suited for workloads with infrequent or highly variable query patterns. The pay-per-use model allows for cost savings during periods of low activity. For example, a system processing monthly reports with peak loads at month-end would benefit significantly from serverless, paying only for the compute resources used during those peak periods. Conversely, a consistently high query load might necessitate over-provisioning of resources, potentially negating the cost advantages.
- Query Complexity: Complex queries, involving extensive data processing, joins, and aggregations, can impact serverless performance and cost. While serverless platforms are constantly improving, the overhead associated with function invocation and data transfer can become significant for computationally intensive queries. Simple, independent queries are often the most cost-effective.
- Data Volume and Access Patterns: The volume of data processed and the access patterns (e.g., read-heavy, write-heavy, or a mix) influence both cost and performance. Serverless functions can scale horizontally to handle large data volumes, but data transfer costs and the latency of accessing data storage (e.g., object storage) must be carefully considered. If the data access pattern is heavily write-oriented, it might incur higher costs compared to read-heavy workloads, as write operations often have different pricing models.
- Query Duration: The execution time of individual queries plays a crucial role. Serverless functions have time limits (e.g., AWS Lambda’s maximum execution time is currently 15 minutes), which can be a constraint for long-running queries. If queries frequently exceed the time limit, alternative architectures, such as those based on containerization or managed query services, may be more appropriate.
- Concurrency Requirements: Serverless platforms inherently support high concurrency. However, the cost of handling concurrent requests can be significant. If a workload requires extreme concurrency, careful consideration must be given to the scaling capabilities and pricing models of the serverless provider.
Vendor Selection and its Impact
The choice of serverless vendor (e.g., AWS, Google Cloud, Azure) profoundly affects both the cost and the benefits of serverless query processing. Each vendor offers different pricing models, service offerings, and performance characteristics.Several factors must be considered during vendor selection:
- Pricing Models: The pricing models vary significantly across vendors. Factors like compute time, memory usage, data transfer, and the number of function invocations influence the overall cost. For example, AWS Lambda pricing is based on the duration and memory allocated to a function, while Google Cloud Functions charges based on the same factors. Careful analysis of the projected workload and the vendor’s pricing structure is essential for cost optimization.
- Service Availability and Reliability: The reliability and availability of the serverless platform are critical. Different vendors have varying service level agreements (SLAs), which define the guaranteed uptime and performance. Downtime can lead to lost productivity and revenue, so the vendor’s track record and SLAs must be carefully evaluated.
- Performance Characteristics: The performance of serverless functions varies depending on the vendor and the underlying infrastructure. Factors like cold start times (the time it takes for a function to initialize) and the maximum execution time can significantly affect query latency. Benchmarking and performance testing are necessary to assess the vendor’s performance capabilities for the specific workload.
- Integration with Other Services: The seamless integration of the serverless platform with other services (e.g., data storage, databases, and monitoring tools) is crucial for simplifying development and operations. Each vendor offers different levels of integration with its ecosystem of services. Selecting a vendor whose services integrate well with the existing infrastructure can reduce complexity and development time.
- Vendor Lock-in: The risk of vendor lock-in, where migrating to another vendor becomes difficult or costly, must be considered. Choosing open standards and portable technologies can mitigate this risk. The vendor’s commitment to open standards and interoperability should be assessed.
- Support and Documentation: The quality of the vendor’s support and documentation is crucial for troubleshooting issues and resolving problems. Adequate support and comprehensive documentation can reduce the time and effort required for development and maintenance.
To illustrate the importance of vendor selection, consider a scenario involving data processing for a large e-commerce platform. If the platform primarily uses AWS services, then using AWS Lambda, integrated with services like S3 for storage and DynamoDB for data retrieval, might be more cost-effective and easier to manage due to the tight integration. Conversely, if the platform already uses Google Cloud’s BigQuery for data warehousing, leveraging Google Cloud Functions might offer better performance and lower integration costs.
Tools and Technologies for Optimization
Optimizing serverless query processing requires a multifaceted approach, encompassing robust monitoring, strategic technology selection, and a deep understanding of cost drivers. Effective use of specialized tools and technologies is crucial for maximizing the cost-benefit ratio, ensuring efficient resource utilization, and achieving desired performance levels. This section details the essential tools and technologies for achieving these goals, providing a practical guide for their implementation.
Tools for Monitoring and Optimizing Serverless Query Processing Costs
Effective cost optimization begins with comprehensive monitoring. Monitoring tools provide the necessary insights into resource consumption, performance bottlenecks, and cost distribution, enabling informed decision-making. These tools facilitate proactive identification and mitigation of inefficiencies, ultimately leading to reduced operational expenses and improved performance.
- Cloud Provider Monitoring Tools: These are the native monitoring services offered by cloud providers like AWS (CloudWatch, X-Ray, Cost Explorer), Google Cloud (Cloud Monitoring, Cloud Trace, Cloud Billing), and Azure (Azure Monitor, Application Insights, Cost Management). They provide detailed metrics on resource usage (CPU, memory, network), latency, error rates, and cost breakdowns. For example, AWS Cost Explorer allows users to visualize cost trends, identify cost drivers, and set budget alerts.
Google Cloud Monitoring provides dashboards and alerts for performance metrics.
- Third-Party Monitoring Tools: These tools offer enhanced features and often provide cross-cloud visibility, allowing for centralized monitoring across multiple cloud providers. Examples include Datadog, New Relic, and Dynatrace. These tools typically offer advanced features such as distributed tracing, automated anomaly detection, and customizable dashboards. They can also integrate with other tools to provide a holistic view of the application’s performance and cost.
- Serverless-Specific Monitoring Tools: Some tools are specifically designed for serverless environments, providing insights into the unique challenges of serverless query processing. These tools often offer features like function-level performance analysis, cold start detection, and cost attribution at the function level. Examples include Thundra and Lumigo. These tools often integrate with cloud provider monitoring services to provide a unified view.
- Log Aggregation and Analysis Tools: Centralized log management is critical for debugging, performance analysis, and cost optimization. Tools like the ELK stack (Elasticsearch, Logstash, Kibana), Splunk, and Sumo Logic allow for the collection, aggregation, and analysis of logs from various sources. These tools can help identify performance bottlenecks, error patterns, and cost inefficiencies by analyzing log data. For instance, identifying frequently failing queries or slow-running functions can lead to targeted optimization efforts.
Technologies That Improve the Cost-Benefit Ratio
Several technologies can be leveraged to improve the cost-benefit ratio of serverless query processing. These technologies often focus on improving performance, reducing resource consumption, and optimizing data storage and retrieval. Careful selection and implementation of these technologies can significantly impact the overall cost-benefit outcome.
- Caching: Implementing caching mechanisms at various levels (e.g., in-memory caching, content delivery networks (CDNs)) can significantly reduce the load on serverless functions and backend databases. Caching frequently accessed data reduces latency and resource consumption, directly translating into cost savings. For example, using a CDN to cache static query results can dramatically reduce the number of requests to the serverless function and the underlying database.
- Data Compression: Compressing data before storage and transmission reduces storage costs and network bandwidth usage. Techniques like gzip compression can be easily implemented in serverless functions. Data compression also improves query performance by reducing the amount of data that needs to be read and processed.
- Database Optimization: Optimizing the database schema, indexing, and query performance is crucial for serverless query processing. Poorly optimized database queries can lead to high latency and increased resource consumption. Techniques such as query optimization, index tuning, and data partitioning can improve query performance and reduce costs. For example, adding appropriate indexes to database tables can significantly speed up query execution times, reducing the amount of time the serverless function spends processing requests.
- Data Partitioning and Sharding: Partitioning and sharding large datasets across multiple storage units can improve query performance and reduce storage costs. This technique allows for parallel processing of queries, reducing latency. It also allows for more efficient scaling of storage resources.
- Query Optimization Techniques: Employing query optimization techniques, such as rewriting queries to use more efficient execution plans, can significantly improve performance. This includes techniques like query simplification, predicate pushdown, and join optimization.
- Use of Serverless Databases: Utilizing serverless databases like AWS Aurora Serverless, Google Cloud SQL, or Azure SQL Database serverless can provide cost savings by automatically scaling resources based on demand. These databases automatically manage resource allocation, reducing the need for manual capacity planning and over-provisioning. The pay-per-use model also helps optimize costs.
- Choosing the Right Programming Language and Runtime: Selecting the appropriate programming language and runtime environment can impact performance and cost. Languages with efficient runtimes, such as Go or Rust, may offer performance advantages over interpreted languages like Python or JavaScript, especially for computationally intensive tasks. The choice of runtime also influences the cold start times, which can significantly impact cost.
Guide on Using Optimization Tools Effectively
To effectively utilize monitoring and optimization tools, a systematic approach is essential. This includes establishing clear objectives, configuring tools correctly, and regularly reviewing and acting upon the insights gained. This guide provides a step-by-step approach for maximizing the benefits of these tools.
- Define Clear Objectives: Before deploying any monitoring or optimization tools, clearly define the objectives. These could include reducing costs by a specific percentage, improving query latency, or minimizing error rates. Having clear goals will help prioritize optimization efforts and measure the effectiveness of the implemented changes.
- Select and Configure Tools: Choose the appropriate monitoring and optimization tools based on the specific needs and the cloud provider being used. Configure the tools to collect the necessary metrics and set up alerts for critical events, such as high latency, increased error rates, or unexpected cost spikes. For example, configure CloudWatch alarms to trigger notifications when Lambda function execution times exceed a defined threshold.
- Establish Baseline Metrics: Before making any changes, establish baseline metrics for key performance indicators (KPIs) such as query latency, resource consumption, and cost. This baseline will serve as a reference point for evaluating the impact of any optimization efforts.
- Analyze Data and Identify Bottlenecks: Regularly review the collected data to identify performance bottlenecks and cost inefficiencies. Use the tools to drill down into specific areas, such as slow-running queries, high resource consumption by specific functions, or inefficient data storage. For example, analyze the CloudWatch logs to identify frequently failing queries or functions that are consistently exceeding their memory limits.
- Implement Optimizations: Based on the analysis, implement targeted optimizations. This might involve rewriting inefficient queries, optimizing the database schema, implementing caching, or adjusting the resource allocation for serverless functions.
- Monitor and Measure Results: After implementing optimizations, continue to monitor the KPIs and measure the impact of the changes. Compare the post-optimization metrics to the baseline to determine the effectiveness of the implemented changes. This iterative process allows for continuous improvement and refinement of the optimization strategy.
- Automate and Integrate: Automate as much of the monitoring and optimization process as possible. Integrate the monitoring tools with other systems, such as CI/CD pipelines, to automate performance testing and cost analysis. For example, integrate performance tests into the CI/CD pipeline to automatically run tests after code changes and alert the development team if the performance degrades.
- Review and Iterate: Regularly review the entire process, including the objectives, the selected tools, and the implemented optimizations. This iterative approach ensures that the optimization strategy remains effective and aligned with the evolving needs of the serverless query processing system.
Future Trends and Considerations
The landscape of serverless query processing is dynamic, with continuous advancements and evolving paradigms. Understanding these emerging trends and potential future developments is crucial for organizations seeking to optimize their cost-benefit outcomes and effectively navigate the evolving serverless computing ecosystem. Proactive adaptation and strategic planning are paramount to capitalizing on these advancements and mitigating potential risks.
Emerging Trends in Serverless Query Processing
Several key trends are reshaping the serverless query processing domain. These trends offer opportunities for improved efficiency, scalability, and cost optimization.
- Advanced Query Optimization Techniques: The integration of advanced query optimization techniques is becoming increasingly prevalent. These include sophisticated query plan generation, adaptive query execution, and intelligent resource allocation. These techniques leverage machine learning and data analytics to dynamically optimize query performance based on real-time workload characteristics and data distribution. This allows systems to make decisions based on current workload. For example, a query optimizer might dynamically adjust the degree of parallelism or select different execution strategies depending on the size of the input data and the complexity of the query.
- Serverless Data Warehousing: The evolution of serverless data warehousing solutions is gaining momentum. These platforms offer fully managed, scalable, and cost-effective environments for storing and analyzing large datasets. They typically integrate seamlessly with serverless query processing engines, enabling organizations to perform complex analytical queries without managing infrastructure. Solutions such as Amazon Redshift Serverless, Google BigQuery, and Snowflake exemplify this trend, providing scalable and pay-as-you-go data warehousing capabilities.
- Edge Computing Integration: The convergence of serverless computing and edge computing is fostering new possibilities. Serverless functions can be deployed at the edge to process data closer to its source, reducing latency and bandwidth costs. This is particularly relevant for applications that require real-time data processing and low-latency access, such as IoT analytics, video streaming, and content delivery. For example, edge-based serverless functions can pre-process sensor data from IoT devices, filter irrelevant information, and send aggregated results to a central server, optimizing bandwidth usage and reducing data transfer costs.
- Enhanced Observability and Monitoring: Improved observability and monitoring capabilities are essential for effectively managing serverless query processing systems. Advanced monitoring tools provide comprehensive insights into performance metrics, resource utilization, and query execution behavior. This enables organizations to proactively identify and resolve performance bottlenecks, optimize resource allocation, and improve overall system efficiency. Tools that automatically detect anomalies and suggest optimization strategies are particularly valuable.
- Multi-Cloud and Hybrid Cloud Architectures: The adoption of multi-cloud and hybrid cloud architectures is increasing. Organizations are increasingly leveraging multiple cloud providers or a combination of on-premises and cloud resources to enhance resilience, avoid vendor lock-in, and optimize costs. Serverless query processing platforms are adapting to support these architectures, providing interoperability and data integration capabilities across different environments. This allows for flexible deployment strategies and the ability to choose the best-suited platform for specific workloads.
Potential Future Developments Impacting Cost-Benefit Outcomes
Several potential developments could significantly influence the cost-benefit outcomes of serverless query processing in the future.
- Serverless-Native Database Systems: The emergence of serverless-native database systems, designed specifically for the serverless paradigm, is likely to accelerate. These systems offer optimized performance, scalability, and cost efficiency for serverless workloads. They often incorporate features such as automatic scaling, pay-per-use pricing, and seamless integration with serverless functions. These database systems are built from the ground up to be serverless, offering superior performance.
- Automated Resource Management and Optimization: Further advancements in automated resource management and optimization are anticipated. Machine learning and artificial intelligence will play a crucial role in dynamically adjusting resource allocation, query optimization, and cost management. These systems will continuously monitor performance, identify bottlenecks, and proactively optimize resource utilization to minimize costs and maximize efficiency. The use of predictive analytics to anticipate workload demands and proactively scale resources will become more common.
- Increased Integration with AI/ML Workloads: Tighter integration with AI and machine learning workloads is expected. Serverless query processing platforms will provide seamless integration with machine learning services, enabling organizations to build and deploy data-driven applications more efficiently. This includes features such as automated model training, inference serving, and data preparation pipelines.
- Advancements in Security and Compliance: Enhanced security and compliance features will be critical. Serverless platforms will need to provide robust security mechanisms, including data encryption, access control, and auditing capabilities, to meet stringent regulatory requirements. Improvements in data governance and privacy controls will be essential to maintain data integrity and protect sensitive information.
- Improved Support for Complex Workloads: Improved support for complex workloads, such as graph processing and geospatial analysis, is anticipated. Serverless platforms will need to provide specialized tools and features to efficiently handle these types of workloads. This includes support for graph databases, geospatial data formats, and specialized query languages.
Preparing for the Evolving Landscape of Serverless Computing
Organizations can take several proactive steps to prepare for the evolving landscape of serverless computing and maximize the cost-benefit outcomes of their serverless query processing deployments.
- Continuous Learning and Skill Development: Invest in continuous learning and skill development to stay abreast of the latest trends and technologies. This includes training on serverless platforms, query optimization techniques, and cloud-native architectures. Encourage teams to experiment with new technologies and participate in industry events to gain practical experience.
- Strategic Technology Selection: Carefully evaluate and select serverless platforms and tools that align with specific business requirements and long-term goals. Consider factors such as performance, scalability, cost efficiency, and integration capabilities. Choose platforms that offer robust support for the types of workloads being processed.
- Proactive Monitoring and Optimization: Implement proactive monitoring and optimization strategies to continuously monitor performance, identify bottlenecks, and optimize resource utilization. Leverage monitoring tools to gain insights into query execution behavior and resource consumption. Regularly review and refine query plans and resource allocation strategies.
- Cost Management and Governance: Establish robust cost management and governance practices to control spending and ensure efficient resource utilization. Implement cost allocation tags, set up budget alerts, and regularly analyze cost reports. Optimize resource usage and take advantage of cost-saving features, such as reserved instances and spot instances.
- Embrace Automation and Infrastructure-as-Code: Embrace automation and infrastructure-as-code (IaC) practices to streamline deployments, manage infrastructure, and ensure consistency. Use IaC tools to automate the provisioning and configuration of serverless resources, reducing manual effort and minimizing the risk of errors. This approach enables repeatable and scalable deployments.
Final Thoughts

In conclusion, the cost-benefit analysis of serverless query processing reveals a complex yet compelling landscape. By carefully evaluating cost components, quantifying benefits, and understanding the influence of various factors, organizations can strategically leverage serverless architectures to optimize their data processing operations. The future of serverless query processing is promising, with ongoing advancements in tools, technologies, and architectural patterns. Successful implementation requires a data-driven approach, continuous monitoring, and adaptation to evolving trends, allowing organizations to unlock the full potential of serverless computing and achieve significant improvements in efficiency, scalability, and overall value.
FAQ Explained
What are the primary cost drivers in serverless query processing?
The primary cost drivers are compute time (function execution duration), memory usage, the number of requests, and data transfer (in/out). Other factors include storage costs for any persistent data and the cost of external services integrated into the query processing workflow.
How does serverless query processing improve developer productivity?
Serverless eliminates the need for infrastructure management, allowing developers to focus solely on code. This reduces the time spent on operational tasks like server provisioning, scaling, and patching, accelerating development cycles and enabling faster time-to-market.
What are the key metrics for measuring the performance benefits of serverless query processing?
Key metrics include query latency (response time), throughput (queries per second), and scalability (ability to handle increased load). Monitoring resource utilization, such as CPU and memory, is also crucial for identifying performance bottlenecks and optimization opportunities.
What are the common challenges in implementing serverless query processing?
Common challenges include cold starts (initial function invocation latency), vendor lock-in, debugging and monitoring complexity, and potential cost overruns if not managed properly. Security considerations and data governance are also critical aspects to address.
How can organizations mitigate the risks associated with vendor lock-in in serverless environments?
Mitigation strategies include designing applications with vendor-agnostic architectures, utilizing open-source technologies where possible, and avoiding deep integration with proprietary vendor services. Carefully evaluating the long-term cost and support of different vendors is also essential.