Managing dependencies within a Lambda function is crucial for ensuring its efficient operation, deployment success, and overall maintainability. Serverless functions, by their nature, rely on external libraries, SDKs, and configuration files to perform their intended tasks. However, improperly handling these dependencies can lead to deployment failures, increased cold start times, and difficult troubleshooting scenarios. This comprehensive guide delves into the intricacies of dependency management within the Lambda environment, offering practical solutions and best practices to optimize your serverless applications.
We’ll explore various approaches, from leveraging Lambda layers for code reuse to employing build tools like npm and pip for automated package creation. The guide will also address common challenges such as dependency conflicts and versioning issues, providing strategies for effective resolution. Furthermore, we will cover the integration of external libraries, the utilization of AWS SDKs, and the secure handling of configuration files and environment variables.
Finally, we’ll examine advanced techniques, including container images and custom runtimes, to streamline dependency management for complex serverless applications.
Introduction: Understanding Lambda Function Dependencies
Serverless functions, such as AWS Lambda functions, operate within a managed execution environment. These functions, however, often require external resources to perform their intended tasks. These external resources are referred to as dependencies, and their effective management is crucial for the performance, reliability, and cost-effectiveness of the Lambda function. Properly managing dependencies ensures that the function can execute correctly, efficiently, and without unforeseen complications.Dependencies in the context of Lambda functions encompass a wide range of components that are not inherently part of the function’s runtime environment but are essential for its operation.
These dependencies must be made available to the function during execution. The way these dependencies are managed significantly impacts the function’s deployment process, cold start times, and overall operational cost.
Common Types of Lambda Function Dependencies
A Lambda function’s functionality often relies on various dependencies. Understanding the different types of dependencies is essential for effective management.
- Libraries and Frameworks: These are pre-written code modules that provide specific functionalities. Examples include:
- Python: Libraries like `requests` for making HTTP requests, `pandas` for data analysis, or `numpy` for numerical operations.
- Node.js: Frameworks like Express.js for building web applications or libraries like `aws-sdk` for interacting with AWS services.
- Java: Libraries such as Apache Commons for utility functions or Spring Framework for application development.
- Software Development Kits (SDKs): SDKs provide interfaces and tools for interacting with specific services. For example, the AWS SDK allows Lambda functions to interact with services like S3, DynamoDB, and others.
- Configuration Files: These files contain settings and parameters that govern the function’s behavior. They may include API keys, database connection strings, or other environment-specific configurations.
- Native Dependencies: These are libraries or tools written in languages like C or C++ that are compiled and linked to the Lambda function. They may provide performance benefits or access to system-level resources.
- Data Files: Static data files such as JSON files, CSV files, or other data formats required by the function to process information.
Potential Problems Arising from Poorly Managed Dependencies
Inefficient management of dependencies can lead to several problems that negatively affect the performance and cost-effectiveness of Lambda functions. Addressing these issues is crucial for optimizing serverless application development.
- Deployment Failures: When dependencies are not correctly packaged or included, deployment can fail. This can occur if the function is unable to locate the necessary libraries or if the package size exceeds the Lambda deployment limits. For example, if a required Python library is missing from the deployment package, the function will fail during invocation.
- Increased Cold Start Times: The cold start time refers to the time it takes for a Lambda function to start running when it hasn’t been invoked recently. Including large or unnecessary dependencies in the deployment package can significantly increase cold start times, as the function needs to load these dependencies before it can execute. A function with a large number of dependencies may experience cold starts of several seconds, impacting the user experience.
- Increased Package Size: Large dependency packages increase the size of the function’s deployment package. This affects both deployment time and storage costs. Exceeding the size limits imposed by AWS can render the function unusable.
- Runtime Errors: Version conflicts between different dependencies or incompatibilities with the Lambda runtime environment can lead to runtime errors. If a function is built using a specific version of a library, but a different version is available in the execution environment, unexpected behavior or errors can occur.
- Security Vulnerabilities: Outdated or unpatched dependencies may contain security vulnerabilities. Exploiting these vulnerabilities could compromise the function and the resources it accesses. Regularly updating dependencies is crucial to mitigate security risks.
- Increased Costs: Larger package sizes can lead to increased storage costs. Moreover, increased cold start times and slower execution times can consume more compute resources, thereby increasing the overall operational costs.
Packaging Dependencies
Lambda layers offer a streamlined approach to managing dependencies, enabling code reuse and optimizing deployment packages. This method significantly improves the efficiency of Lambda functions, particularly those requiring shared libraries or common utility functions. Understanding the intricacies of layers is crucial for building scalable and maintainable serverless applications.
Advantages and Disadvantages of Using Lambda Layers
Lambda layers provide several benefits, but they also present certain drawbacks. A comprehensive understanding of these aspects is essential for making informed decisions regarding dependency management.
- Advantages:
- Code Reuse: Layers allow developers to share code across multiple Lambda functions, eliminating the need to package the same dependencies repeatedly. This promotes modularity and reduces code duplication.
- Reduced Package Size: By externalizing dependencies into layers, the deployment package size of individual Lambda functions decreases. Smaller package sizes lead to faster deployment times and improved cold start performance.
- Simplified Updates: Updating a dependency in a layer automatically propagates the changes to all Lambda functions that use that layer. This simplifies the maintenance process and ensures consistency across functions.
- Version Control: Layers support versioning, allowing developers to manage different versions of dependencies and easily roll back to previous versions if necessary.
- Improved Cold Start Performance: While not always a significant factor, smaller deployment packages generally contribute to faster cold start times, enhancing the user experience.
- Disadvantages:
- Layer Size Limits: There are size limitations for layers. The total unzipped size of all layers attached to a function, plus the function’s deployment package, cannot exceed a certain limit (currently 250 MB). Exceeding this limit can cause deployment failures.
- Complexity: Implementing and managing layers can add complexity to the deployment process, especially for simple functions with few dependencies.
- Dependency Conflicts: If different layers contain conflicting dependencies, it can lead to unexpected behavior or runtime errors. Careful planning and testing are crucial to avoid such conflicts.
- Version Compatibility: Functions must be compatible with the layer’s versions, or issues will arise.
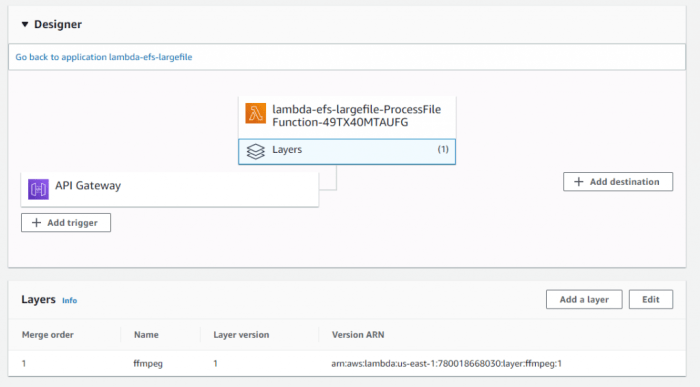
Creating a Lambda Layer Using the AWS CLI
The AWS Command Line Interface (CLI) provides a powerful and flexible way to create and manage Lambda layers. The following steps Artikel the process.
- Prepare the Dependencies:
First, create a directory structure that mirrors the expected layout within the Lambda function. This structure typically includes a `python` directory for Python dependencies. For example:
mkdir -p my-layer/pythonInstall the required dependencies into this directory using `pip`:
pip install -t my-layer/python requests - Create the Layer Archive:
Zip the contents of the directory to create a layer archive. This archive will be uploaded to AWS.
cd my-layer zip -r ../my-layer.zip . cd .. - Upload the Layer:
Use the AWS CLI to upload the layer archive to Amazon S3. This step stores the zip file, ready for use.
aws s3 cp my-layer.zip s3://your-bucket-name/ - Create the Layer in AWS Lambda:
Use the AWS CLI to create the Lambda layer, specifying the S3 bucket and key where the layer archive is stored.
aws lambda create-layer \ --layer-name my-layer-name \ --description "My custom layer with requests library" \ --license-info "MIT" \ --compatible-runtimes python3.9 python3.10 python3.11 \ --content S3Bucket=your-bucket-name,S3Key=my-layer.zip - Attach the Layer to a Lambda Function:
Modify the Lambda function configuration to include the layer. This can be done through the AWS CLI or the AWS Management Console.
aws lambda update-function-configuration \ --function-name my-function-name \ --layers arn:aws:lambda:REGION:ACCOUNT_ID:layer:my-layer-name:1Replace `REGION` with your AWS region, `ACCOUNT_ID` with your AWS account ID, and `1` with the layer version. The ARN (Amazon Resource Name) is essential for linking the function to the layer.
Benefits of Using Layers for Code Reuse and Package Size Reduction
Lambda layers significantly improve code reuse and reduce the size of deployment packages, resulting in a more efficient and scalable architecture. The use of layers has demonstrable advantages.
- Code Reuse:
Layers allow developers to centralize common code, such as utility functions, helper libraries, and shared modules, into a single location. This promotes the DRY (Don’t Repeat Yourself) principle, leading to cleaner, more maintainable code. For example, a function that needs to connect to a database can use a shared layer containing the database connection code. This reduces the size of the function’s code and simplifies maintenance.
- Package Size Reduction:
By moving dependencies into layers, the size of the Lambda function’s deployment package is reduced. Smaller package sizes lead to faster deployment times and improved cold start performance. Consider a Lambda function that uses the `requests` library. Without layers, the `requests` library (and its dependencies) would be included in the function’s deployment package. Using a layer removes these dependencies from the function’s package, making it smaller and faster to deploy.
This is especially important for functions that are triggered frequently, where fast cold starts are critical.
Updating a Layer and Redeploying a Lambda Function
Updating a Lambda layer and redeploying a function that uses it involves a straightforward process. This ensures that all functions using the layer benefit from the latest updates.
- Update the Layer Contents:
Modify the dependencies within the layer directory. For example, update the version of a library:
pip install -t my-layer/python requests==2.28.0 - Re-zip the Layer:
Create a new zip archive with the updated contents.
cd my-layer zip -r ../my-layer.zip . cd .. - Upload the Updated Layer:
Upload the new layer archive to Amazon S3, overwriting the previous version.
aws s3 cp my-layer.zip s3://your-bucket-name/ - Create a New Layer Version:
Create a new version of the Lambda layer, pointing to the updated archive in S3. The layer name remains the same, but the version number increments automatically.
aws lambda publish-layer-version \ --layer-name my-layer-name \ --description "Updated requests library" \ --compatible-runtimes python3.9 python3.10 python3.11 \ --content S3Bucket=your-bucket-name,S3Key=my-layer.zip - Update the Lambda Function Configuration:
Update the Lambda function to use the new layer version. Retrieve the ARN of the new layer version and update the function’s configuration.
aws lambda update-function-configuration \ --function-name my-function-name \ --layers arn:aws:lambda:REGION:ACCOUNT_ID:layer:my-layer-name:2Replace `2` with the new layer version number. Testing is recommended after updates.
- Test the Function:
Thoroughly test the Lambda function to ensure that the updated dependencies are working as expected and that there are no regressions.
Packaging Dependencies
Deploying Lambda functions often requires managing dependencies, which are external libraries or packages your function relies on to execute its logic. These dependencies need to be included alongside your function’s code for successful execution in the AWS environment. The methods for incorporating these dependencies significantly impact deployment complexity, function performance, and overall manageability.
Deployment Package vs. Layer Approach
Two primary strategies exist for including dependencies: the deployment package approach and the layer approach. Each offers distinct advantages and disadvantages, influencing the design of your Lambda function and its deployment pipeline.To illustrate the differences, consider the following comparison:
| Feature | Deployment Package | Lambda Layer |
|---|---|---|
| Dependency Inclusion | Dependencies are packaged directly within the function’s deployment archive (e.g., a ZIP file). | Dependencies are packaged into a separate archive (layer) and attached to the function. |
| Size Limits | Subject to function deployment package size limits (e.g., 250MB unzipped). | Layer size limits apply (e.g., 250MB unzipped per layer). Function code size is separate. |
| Code Reusability | Dependencies are specific to each function; no direct code reuse across functions. | Dependencies can be shared across multiple functions, promoting code reuse and reducing redundancy. |
| Update Management | Updating a dependency requires redeploying the entire function package. | Updating a dependency in a layer allows for updates across multiple functions simultaneously. |
| Deployment Complexity | Potentially simpler for small projects; dependencies are managed within the function’s build process. | More complex initial setup; requires managing separate layer deployments. However, simplifies dependency management across multiple functions. |
| Execution Performance | May result in slower cold starts due to larger package sizes. | Potentially faster cold starts, especially when using shared layers, as dependencies are pre-loaded. |
The deployment package approach is generally simpler for small projects or functions with few dependencies. However, it becomes less manageable as the number of dependencies grows, or when those dependencies are shared across multiple functions. The layer approach offers better code reusability and streamlined dependency management, particularly in larger, more complex projects where shared libraries are common. Choosing the right approach depends on the specific requirements of the project, including function size, dependency complexity, and the need for code reusability.
Including Dependencies Directly within the Deployment Package
Including dependencies directly within the deployment package involves bundling them with your function’s code during the build process. This is typically achieved using a build tool like npm (for Node.js) or pip (for Python).Here are the steps for including dependencies within the deployment package, using Python as an example:
- Create a directory for your Lambda function and a subdirectory for your dependencies (e.g., `my_function` and `my_function/lib`).
- Inside the `my_function` directory, create your Python function file (e.g., `lambda_function.py`).
- Use `pip` to install the required dependencies into the `lib` directory. For example:
pip install -t lib requestsThis command installs the `requests` library and its dependencies into the `lib` directory.
- Organize your directory structure so that the `lambda_function.py` file is at the root of the deployment package, along with the `lib` directory.
- Create a ZIP file containing the `lambda_function.py` file and the `lib` directory. This ZIP file constitutes your deployment package.
- Upload the ZIP file to your Lambda function.
Inside `lambda_function.py`, you would then import the `requests` library:“`pythonimport jsonimport requestsdef lambda_handler(event, context): try: response = requests.get(“https://www.example.com”) return ‘statusCode’: 200, ‘body’: json.dumps(‘message’: f”Request to example.com successful.
Status code: response.status_code”) except requests.exceptions.RequestException as e: return ‘statusCode’: 500, ‘body’: json.dumps(‘message’: f”Request failed: e”) “`This approach ensures that all dependencies are available to the Lambda function during execution.
Similar processes exist for other languages, such as Node.js, where dependencies are typically installed using `npm` and bundled into a `node_modules` directory within the deployment package.
Considerations for Deployment Package Size Limits
AWS imposes size limits on Lambda function deployment packages. These limits are crucial because they directly impact deployment time, cold start performance, and overall function efficiency. Exceeding these limits will prevent deployment.The key limits to consider are:
- Unzipped Package Size: The unzipped size of the deployment package is limited (e.g., 250MB). This includes the function code, dependencies, and any other files included in the package.
- Zipped Package Size: While not always a direct concern, the zipped size also matters, especially during the upload process. Large zipped files take longer to upload.
- Layer Size Limits: While not directly related to the deployment package, layers also have size limits (e.g., 250MB unzipped per layer).
Strategies to manage deployment package size include:
- Minimizing Dependencies: Only include the dependencies that are absolutely necessary for your function’s operation. Evaluate whether all dependencies are required.
- Using Layers: For shared dependencies, layers are the preferred method. This reduces the size of individual deployment packages.
- Optimizing Dependencies: Utilize tools like `pip-tools` (for Python) or `npm prune` (for Node.js) to remove unnecessary files from your dependencies. This reduces the size of the deployment package.
- Code Optimization: Write efficient code to reduce the overall size of the function code itself.
For instance, if a function uses the `requests` library and several of its dependencies, it is vital to use only the specific modules from the library required. By removing unused dependencies or modules, the overall size of the deployment package will be smaller, leading to faster deployments and improved performance. If a project is nearing the size limit, refactoring dependencies to use layers is highly recommended.
Automating Deployment Package Creation with Build Tools
Automating the creation of the deployment package is critical for a repeatable and efficient development workflow. This automation ensures that dependencies are correctly included and that the package is consistently built for each deployment. Build tools like npm (for Node.js) and pip (for Python) are instrumental in this process.Here’s a general workflow for automating deployment package creation using a build tool, such as npm:
- Project Setup: Initialize your project with the build tool (e.g., `npm init -y` for Node.js). This creates a `package.json` file to manage dependencies.
- Dependency Declaration: Declare your function’s dependencies in the `package.json` file. For example: “`json “name”: “my-lambda-function”, “version”: “1.0.0”, “dependencies”: “axios”: “^1.0.0” “`
- Dependency Installation: Install the dependencies using the build tool (e.g., `npm install`). This creates a `node_modules` directory containing the installed packages.
- Build Script (Optional): Create a build script in your `package.json` file to perform tasks like transpilation (if using TypeScript) or code minification. For example: “`json “scripts”: “build”: “tsc” “`
- Deployment Package Creation Script: Implement a script (e.g., a shell script or a script using a tool like `zip`) to create the deployment package. This script should:
- Copy your function code (e.g., `index.js`) into a temporary directory.
- Copy the `node_modules` directory into the same temporary directory.
- Zip the contents of the temporary directory into a ZIP file (the deployment package).
- Deployment: Integrate the package creation script into your deployment process (e.g., using the AWS CLI, a CI/CD pipeline like AWS CodePipeline, or a deployment framework like the Serverless Framework).
An example of a simplified deployment package creation script using `zip` (for Linux/macOS):“`bash#!/bin/bashset -e# Define the name of the function and the deployment packageFUNCTION_NAME=”my-lambda-function”DEPLOYMENT_PACKAGE=”$FUNCTION_NAME.zip”# Create a temporary directoryTEMP_DIR=$(mktemp -d)# Copy the function codecp index.js $TEMP_DIR# Copy the node_modules directorycp -r node_modules $TEMP_DIR# Zip the contents of the temporary directoryzip -r $DEPLOYMENT_PACKAGE $TEMP_DIR/*# Clean up the temporary directoryrm -rf $TEMP_DIRecho “Deployment package ‘$DEPLOYMENT_PACKAGE’ created successfully.”“`This script copies the function code (`index.js` in this example) and the `node_modules` directory into a temporary directory, then zips the contents of that directory into the deployment package.
The script then cleans up the temporary directory. This automated process ensures that the deployment package is correctly created with all necessary dependencies for each deployment, streamlining the development and deployment workflow.
Managing Dependencies with Build Tools (Node.js)
Build tools streamline the process of managing dependencies for Node.js Lambda functions, ensuring efficient packaging and deployment. These tools automate the installation of required packages, optimize code size, and facilitate the creation of deployment packages that can be uploaded to AWS Lambda. This approach significantly simplifies dependency management compared to manual methods, promoting code maintainability and reducing the potential for errors.
Role of Package Managers in Dependency Management
Package managers, such as npm (Node Package Manager) and yarn, are fundamental to managing dependencies in Node.js projects, including those intended for Lambda functions. They provide a centralized repository for JavaScript packages and automate the process of installing, updating, and removing dependencies.
- Dependency Declaration: Package managers allow developers to declare project dependencies in a `package.json` file, specifying package names and version requirements. This ensures that the correct versions of dependencies are installed consistently across different environments.
- Dependency Resolution: When a project is built, the package manager resolves the dependencies, downloading the necessary packages and their transitive dependencies (dependencies of dependencies).
- Version Management: Package managers handle version conflicts and ensure that the correct versions of dependencies are used. They also allow for updating dependencies to newer versions, simplifying the process of keeping the project up-to-date with the latest features and security patches.
- Deployment Package Creation: Package managers are often integrated with build tools that facilitate the creation of deployment packages for Lambda functions. These tools bundle the function code and its dependencies into a single package, ready for deployment to AWS Lambda.
Using `package.json` to Declare and Manage Dependencies
The `package.json` file is the heart of dependency management in Node.js projects. It acts as a manifest file, containing metadata about the project and a list of its dependencies. This file is crucial for ensuring that the correct dependencies are installed when the Lambda function is deployed.
- Structure of `package.json`: The `package.json` file is a JSON (JavaScript Object Notation) file. It typically includes fields such as `name`, `version`, `description`, and, most importantly for dependency management, `dependencies` and `devDependencies`.
- `dependencies` Field: This field lists the production dependencies required by the Lambda function. These are the packages that are necessary for the function to run correctly in the production environment. Each dependency is specified with its name and a version range (e.g., `”lodash”: “^4.17.21″`). The caret symbol (`^`) indicates that any version compatible with the specified major version is acceptable.
- `devDependencies` Field: This field lists the development dependencies, which are packages used during development, testing, and building, but not required in the production environment. Examples include testing frameworks (like Jest), linters (like ESLint), and build tools (like Webpack). These are not bundled with the Lambda function code unless explicitly configured.
- Example `package.json`:
"name": "my-lambda-function", "version": "1.0.0", "description": "A simple Lambda function", "dependencies": "lodash": "^4.17.21", "axios": "^1.6.7" , "devDependencies": "jest": "^29.7.0"
- Installation with `npm install`: When the `package.json` file is present, running `npm install` (or `yarn install`) installs all the dependencies listed in the `dependencies` and `devDependencies` fields, creating a `node_modules` directory where the packages are stored.
- Deployment Package Considerations: Only the dependencies listed in the `dependencies` field, and their transitive dependencies, are typically included in the deployment package for a Lambda function to minimize its size and improve deployment speed.
Creating a Deployment Package with a Build Tool
Creating a deployment package involves bundling the function’s code and its dependencies into a single archive, ready for upload to AWS Lambda. Build tools automate this process, streamlining the workflow and ensuring that the package contains everything needed for the function to execute correctly.
- Building the Package: A build tool typically performs several steps, including:
- Installing dependencies (if not already done).
- Copying the function code and its dependencies into a designated directory.
- Optimizing the code (e.g., minifying JavaScript files).
- Creating a zip archive of the resulting directory.
- Build Tool Configuration: Build tools often require a configuration file (e.g., `webpack.config.js` for Webpack) that specifies how to build the package. This configuration can include information about the entry point of the function, the target environment (e.g., Node.js), and any transformations or optimizations to be applied.
- Example using Webpack:
- Install Webpack: `npm install –save-dev webpack webpack-cli`
- Create `webpack.config.js`:
const path = require('path'); module.exports = entry: './index.js', // Your Lambda function entry point output: filename: 'index.js', path: path.resolve(__dirname, 'dist'), // Output directory libraryTarget: 'commonjs2' , target: 'node', mode: 'production', // or 'development' ; - Build the package: `npx webpack`
- This creates a `dist` directory containing `index.js` (your bundled code) and any necessary dependencies. You can then zip the `dist` directory to create the deployment package.
- Automated Deployment: Many build tools integrate with deployment pipelines, automating the upload of the deployment package to AWS Lambda. This simplifies the process of deploying and updating Lambda functions.
Comparing Build Tools for Node.js Lambda Functions
Different build tools offer varying features and capabilities for managing dependencies and creating deployment packages. The choice of tool depends on the complexity of the project, the desired level of optimization, and the developer’s familiarity with the tool.
| Tool | Advantages | Disadvantages |
|---|---|---|
| Webpack |
|
|
| esbuild |
|
|
| Parcel |
|
|
| Serverless Framework (with plugins) |
|
|
Managing Dependencies with Build Tools (Python)
Python, a versatile language for serverless functions, relies heavily on managing dependencies for efficient execution. This section details the use of `pip` and `requirements.txt` alongside build tools to streamline dependency management for Python-based Lambda functions. Effective dependency handling ensures code portability, reproducibility, and reduces the likelihood of runtime errors.
Using `pip` and `requirements.txt`
`pip`, the Python package installer, and `requirements.txt`, a file listing project dependencies, form the core of dependency management in Python. This approach facilitates the consistent installation of required packages across different environments, including the Lambda function’s execution environment.
The `requirements.txt` file acts as a manifest, explicitly specifying the packages and their versions needed by the project. This file is crucial for ensuring that the Lambda function has all the necessary dependencies when it’s deployed.
To create a `requirements.txt` file, you typically use the following command:
“`bash
pip freeze > requirements.txt
“`
This command captures the currently installed packages and their versions in your development environment and writes them to `requirements.txt`. For instance, if your project uses the `requests` library version 2.28.1 and the `boto3` library version 1.26.107, the `requirements.txt` file might contain:
“`
requests==2.28.1
boto3==1.26.107
“`
When deploying the Lambda function, these dependencies are installed within the function’s execution environment, making the packages available for use.
Creating a Deployment Package
Creating a deployment package involves bundling the Lambda function’s code and its dependencies into a zip file. This package is then uploaded to AWS Lambda. The process varies slightly depending on the build tool used. The general steps, however, remain consistent.
A common method for creating a deployment package is as follows:
1. Create a Project Directory: Organize your project into a directory, for example, `my_lambda_function`. Within this directory, you will have your Python code (e.g., `lambda_function.py`) and the `requirements.txt` file.
2. Install Dependencies Locally: Use `pip` to install the dependencies listed in `requirements.txt`. It is recommended to use a virtual environment (explained in the next section) to isolate these dependencies from your system-wide Python installation. If you haven’t used a virtual environment, dependencies can be installed using:
“`bash
pip install -r requirements.txt -t .
“`
The `-t .` argument specifies that the packages should be installed in the current directory.
3. Package the Code: Zip the contents of the project directory, including the Python code and the installed dependencies. For example:
“`bash
zip -r deployment_package.zip .
“`
This creates a zip file named `deployment_package.zip`.
4. Upload to AWS Lambda: Upload the `deployment_package.zip` file to your AWS Lambda function. This can be done via the AWS Management Console, the AWS CLI, or infrastructure-as-code tools like Terraform or AWS CloudFormation.
This process ensures that all necessary packages are available when the Lambda function executes. Any missing dependencies would result in runtime errors.
Using Virtual Environments (e.g., `venv`)
Virtual environments, such as those created using the `venv` module, provide isolated Python environments. This isolation prevents conflicts between project dependencies and the global Python installation, ensuring that each project has its own set of dependencies.
The advantages of using virtual environments are numerous:
* Dependency Isolation: Prevents conflicts between different projects by isolating their dependencies.
– Reproducibility: Ensures consistent dependency versions across different development and deployment environments.
– Cleanliness: Keeps the global Python installation clean and uncluttered.
To use `venv`, follow these steps:
1. Create a Virtual Environment: Navigate to your project directory and create a virtual environment:
“`bash
python -m venv .venv
“`
This creates a directory named `.venv` (or whatever name you choose) containing the virtual environment files.
2. Activate the Virtual Environment: Activate the virtual environment to use its isolated Python installation:
– Linux/macOS: `source .venv/bin/activate`
– Windows: `.venv\Scripts\activate`
After activation, the terminal prompt will typically indicate that the virtual environment is active (e.g., `(.venv) $`).
3. Install Dependencies: With the virtual environment activated, install the project’s dependencies using `pip`:
“`bash
pip install -r requirements.txt
“`
The packages are installed within the virtual environment’s `site-packages` directory.
4. Deactivate the Virtual Environment: When you are finished working on the project, deactivate the virtual environment:
“`bash
deactivate
“`
When creating the deployment package, the dependencies installed within the virtual environment will be included in the zip file. This ensures that the Lambda function has the correct dependencies.
Handling Dependencies with Specific Versions
Specifying dependency versions in `requirements.txt` is crucial for ensuring that your Lambda function behaves predictably. Using specific versions mitigates the risk of unexpected behavior caused by updates to dependencies.
The `requirements.txt` file allows you to specify the exact versions of the packages your project requires. This is done using the `==` operator:
“`
requests==2.28.1
boto3==1.26.107
“`
This example specifies that the `requests` package must be version 2.28.1 and the `boto3` package must be version 1.26.107. If a different version is installed in the Lambda execution environment, your code may break.
You can also use comparison operators for version constraints. For example:
* `requests>=2.28.0`: Allows any version of `requests` that is version 2.28.0 or later.
– `boto3 <2.0.0`: Allows any version of `boto3` that is less than 2.0.0.When deploying, the Lambda function will use the specified versions. It's essential to test your code with the specified versions to ensure compatibility and prevent runtime errors. Regularly updating the versions in your `requirements.txt` and testing the changes can keep your dependencies secure and up-to-date.
Dependency Conflicts and Resolution
Managing dependencies effectively is crucial for the stability and maintainability of Lambda functions. However, conflicts between different package versions can arise, leading to runtime errors and unexpected behavior. Understanding the causes of these conflicts and implementing robust resolution strategies is essential for ensuring reliable function execution.
Common Causes of Dependency Conflicts
Dependency conflicts in Lambda functions often stem from inconsistencies in the versions of packages required by different parts of the application or by the underlying Lambda execution environment. These conflicts can manifest in several ways, causing the function to fail.
- Conflicting Version Requirements: Different dependencies within the same Lambda function may specify incompatible versions of a shared dependency. For example, one library might require version 1.0 of a package, while another requires version 2.0, which introduces breaking changes.
- Transitive Dependencies: Conflicts can arise from transitive dependencies, where a package depends on another package, and that package in turn depends on a third package. If different packages in the dependency tree require conflicting versions of the same transitive dependency, a conflict occurs.
- Lambda Runtime Environment: The Lambda runtime environment itself may include certain packages. If the function’s dependencies require different versions of those packages, a conflict may arise, especially if the required version is not compatible with the runtime environment’s version.
- Packaging Errors: Incorrect packaging, such as including duplicate copies of the same dependency or failing to include all required dependencies, can lead to conflicts and runtime errors.
Strategies for Resolving Dependency Conflicts
Resolving dependency conflicts requires careful planning and the implementation of several strategies to ensure that the Lambda function functions correctly. This often involves specifying version constraints, using dependency management tools effectively, and testing the function thoroughly.
- Version Pinning: The most common and effective approach is to specify precise versions for all dependencies. This ensures that the same versions are used consistently across all deployments.
- Version Range Specification: Instead of pinning to a specific version, version ranges can be used, allowing for minor version updates while maintaining compatibility.
- Dependency Tree Analysis: Utilize tools to analyze the dependency tree and identify conflicting versions. This helps to pinpoint the source of the conflict and determine the appropriate resolution strategy.
- Dependency Isolation: In some cases, it may be possible to isolate dependencies by using separate packaging or containerization techniques, although this can add complexity.
- Regular Updates and Testing: Regularly update dependencies and thoroughly test the Lambda function to identify and address potential conflicts early. This includes running tests that cover different scenarios and edge cases.
Using Version Constraints in `package.json` (Node.js)
Node.js projects use `package.json` to manage dependencies. Specifying version constraints is critical for preventing conflicts. The `package.json` file uses semantic versioning (SemVer) to define the allowed version ranges for dependencies.
- Exact Version: Pinning a dependency to a specific version ensures that only that version is used. This is the most conservative approach and offers the highest level of stability. For example:
"lodash": "4.17.21" - Version Range: Using version ranges allows for updates within a specified range. This provides a balance between stability and the ability to benefit from bug fixes and minor improvements. Common range operators include:
- `^` (Caret): Allows updates that do not change the leftmost non-zero digit in the version number. For example, `”^1.2.3″` allows updates to `1.x.x` but not `2.x.x`.
- `~` (Tilde): Allows updates that do not change the middle digit. For example, `”~1.2.3″` allows updates to `1.2.x` but not `1.3.x`.
- `>` (Greater than): Specifies a minimum version. For example, `”>1.2.3″` allows any version greater than 1.2.3.
- `<` (Less than): Specifies a maximum version. For example, `” <1.2.3"` allows any version less than 1.2.3.
"express": "^4.17.1"
Using Version Constraints in `requirements.txt` (Python)
Python projects use `requirements.txt` to manage dependencies. Similar to `package.json`, it allows specifying version constraints to avoid conflicts.
- Exact Version: Specifying an exact version ensures that only the specified version of a package is installed.
requests==2.28.1 - Version Comparison Operators: Python’s `requirements.txt` supports various comparison operators to specify version ranges.
- `==` (Equals): Specifies an exact version.
- `>=` (Greater than or equal to): Specifies a minimum version.
- `<=` (Less than or equal to): Specifies a maximum version.
- `!=` (Not equal to): Specifies a version to exclude.
- `~=` (Compatible release): Specifies a compatible release. This behaves similarly to the caret (^) operator in npm, allowing for updates within a compatible range. For example, `requests~=2.28.0` would allow updates to `2.28.x` but not `2.29.x`.
Flask>=2.0.0,<3.0.0
Flowchart: Diagnosing and Resolving a Dependency Conflict
The following flowchart illustrates a structured approach to diagnosing and resolving dependency conflicts in a Lambda function.
The flowchart begins with a start node: "Function Fails or Unexpected Behavior". From this point, the process follows a sequence of steps.
1. Analyze Logs and Error Messages: The first step involves analyzing the function's logs and any error messages to identify the potential cause of the failure. This helps in pinpointing which dependencies might be involved.
2. Identify Conflicting Dependencies: Next, the process identifies which dependencies are involved in the conflict.
This can be done by examining the error messages, the function's code, and the dependency manifests (e.g., `package.json` or `requirements.txt`).
3. Inspect Dependency Manifests: Review the `package.json` (Node.js) or `requirements.txt` (Python) file to check the version constraints of the dependencies. This step helps to determine if any version ranges are too broad or if there are any conflicting versions specified.
4. Analyze Dependency Tree: Use a dependency tree analysis tool to visualize the dependencies and their versions. This will reveal any transitive dependencies that may be causing conflicts.
5. Determine Resolution Strategy: Based on the analysis, decide on the best resolution strategy.
This might involve:
- Pinning dependencies to specific versions.
- Adjusting version ranges.
- Updating dependencies to compatible versions.
6. Modify Dependency Manifests: Implement the chosen resolution strategy by modifying the dependency manifests (e.g., `package.json` or `requirements.txt`).
7. Re-package and Deploy: Re-package the Lambda function with the updated dependencies and deploy it.
8.
Test the Function: Thoroughly test the function to ensure that the conflict is resolved and that the function is working as expected.
9. Is the Conflict Resolved?: If the conflict is resolved, the process ends. If not, the process loops back to the "Analyze Logs and Error Messages" step to begin the diagnosis again.
This flowchart provides a systematic approach to resolving dependency conflicts, ensuring the Lambda function functions correctly.
Using External Libraries and SDKs
Lambda functions frequently require functionality beyond the built-in capabilities of the runtime environment. This necessitates the integration of external libraries and Software Development Kits (SDKs). These tools provide pre-built functionalities, simplifying complex tasks and enabling interaction with external services. Effective management of these dependencies is crucial for both functionality and performance of the Lambda function.
Incorporating External Libraries into Lambda Functions
The process of integrating external libraries involves packaging them with the function's deployment package. The specific steps vary slightly depending on the programming language used. For instance, in Python, libraries are typically included using a package manager like `pip`. Node.js projects use `npm` or `yarn`. These package managers download the dependencies and their transitive dependencies, which are then included in the deployment package.
For Python, the process involves:
- Creating a virtual environment (Recommended): Using a virtual environment isolates the project's dependencies, preventing conflicts with other projects. The command `python3 -m venv .venv` creates a virtual environment. Activating the environment ensures that `pip` installs packages within the isolated context.
- Installing Dependencies: Use `pip install
` to install required libraries. For example, `pip install pandas requests` installs the Pandas and requests libraries. - Packaging the Dependencies: The deployment package needs to include the installed libraries. This is achieved by copying the libraries from the virtual environment's `site-packages` directory into the function's deployment package. The zip file containing the function code and dependencies is then uploaded to AWS Lambda.
For Node.js, the process involves:
- Initializing a Node.js project: If you don't already have a `package.json` file, use `npm init -y` to create one. This file defines the project and its dependencies.
- Installing Dependencies: Use `npm install
` to install required libraries. For example, `npm install axios` installs the axios library. - Packaging the Dependencies: The `node_modules` directory, which contains the installed dependencies, needs to be included in the deployment package along with the function's code. The zip file containing the function code and dependencies is then uploaded to AWS Lambda.
Using AWS SDKs within Lambda Functions
AWS SDKs provide a programmatic interface for interacting with AWS services. Using the AWS SDKs in Lambda functions enables tasks such as accessing data in S3, sending messages via SQS, or managing resources in DynamoDB. The SDKs are designed to handle authentication, error handling, and other complexities of interacting with AWS services.
For Python, Boto3 is the primary SDK. The following is a simplified example:
```python
import boto3
def lambda_handler(event, context):
s3 = boto3.client('s3')
try:
response = s3.list_buckets()
bucket_names = [bucket['Name'] for bucket in response['Buckets']]
return
'statusCode': 200,
'body': f'Bucket names: bucket_names'
except Exception as e:
return
'statusCode': 500,
'body': f'Error: str(e)'
```
This code snippet demonstrates listing S3 buckets. The `boto3.client('s3')` line creates an S3 client. The `s3.list_buckets()` method retrieves a list of buckets.
For Node.js, the AWS SDK for JavaScript is used. A similar example is:
```javascript
const AWS = require('aws-sdk');
exports.handler = async (event) =>
const s3 = new AWS.S3();
try
const data = await s3.listBuckets().promise();
const bucketNames = data.Buckets.map(bucket => bucket.Name);
return
statusCode: 200,
body: JSON.stringify( bucketNames )
;
catch (err)
console.error(err);
return
statusCode: 500,
body: JSON.stringify( error: err.message )
;
;
```
This JavaScript code performs a similar function, using the `AWS.S3()` constructor to create an S3 client. The `.promise()` method is used to handle the asynchronous operation.
Handling Version Compatibility Issues
Version conflicts can arise when a Lambda function's runtime environment includes a different version of a library than the one required by the function's code. This can lead to unexpected behavior or runtime errors. Careful management of dependencies is crucial to mitigate these issues.
- Specify Version Constraints: Explicitly define the required versions of external libraries in the project's dependency management file (e.g., `requirements.txt` for Python or `package.json` for Node.js). This ensures that the correct versions are installed during the deployment process. For example, in `requirements.txt`, a line like `pandas==1.5.3` specifies a specific version of Pandas.
- Test Thoroughly: Conduct comprehensive testing of the Lambda function with the packaged dependencies to identify and resolve potential version conflicts before deploying to production. This includes unit tests, integration tests, and end-to-end tests.
- Consider Runtime Environment: Understand the runtime environment's default libraries and their versions. This information is available in the AWS Lambda documentation for each supported runtime. Avoid installing dependencies that are already provided by the runtime environment, unless a specific version is required.
- Use Layering (Advanced): For complex dependencies or shared libraries, consider using Lambda Layers. Layers allow you to package dependencies separately from the function code, which can simplify dependency management and reduce the size of the deployment package.
Optimizing the Use of External Libraries for Cold Start Times
Cold start times, the time it takes for a Lambda function to initialize when invoked for the first time, can be significantly impacted by the size and number of dependencies. Optimizing the use of external libraries is a key factor in minimizing cold start times.
- Minimize Package Size: Reduce the size of the deployment package by only including necessary dependencies. Remove any unused libraries or modules. Use tools like `pip-audit` for Python to identify and remove unused dependencies. For Node.js, consider using a tool like `webpack` or `esbuild` to bundle the code and dependencies, which can help reduce the package size.
- Use Layers (Strategic): Layers can be used to share dependencies across multiple Lambda functions, reducing the overall package size for each function. This is particularly effective for large or commonly used libraries.
- Lazy Loading (If Applicable): If a library is not always required, consider lazy loading it within the function's code. This means importing the library only when it is needed. This can help reduce the initial load time.
- Optimize Code: Write efficient code that avoids unnecessary imports or operations. Profiling tools can help identify performance bottlenecks within the function.
- Choose Efficient Libraries: When possible, select libraries that are known for their performance and efficiency. Research the performance characteristics of different libraries before choosing one.
Handling Configuration Files and Environment Variables
Effective management of configuration files and environment variables is crucial for creating robust and maintainable Lambda functions. This approach allows for the separation of code and configuration, promoting flexibility and security. By storing configuration details externally, developers can modify function behavior without altering the underlying code, simplifying deployments and reducing the risk of errors.
Including Configuration Files in Deployment Packages
To include configuration files within a Lambda function's deployment package, specific steps must be followed depending on the runtime environment. This process ensures that the function can access the necessary settings during execution.
For Node.js, configuration files (e.g., JSON, YAML, or .env files) can be placed within the same directory structure as the Lambda function code. When the deployment package is created (e.g., using `zip` or a build tool like `webpack`), these files are included. During function execution, the code can then read these files using standard file system operations (e.g., `fs.readFileSync` in Node.js).
For instance:
```javascript
const fs = require('fs');
const config = JSON.parse(fs.readFileSync('config.json', 'utf8'));
console.log(config.apiKey);
```
In Python, similar to Node.js, configuration files can be included in the deployment package. When the package is created (e.g., using `zip` or a build tool), the configuration files are included. Python can then access these files using the `open()` function or libraries like `configparser` for parsing configuration files in a specific format (e.g., INI files). For example:
```python
import json
with open('config.json', 'r') as f:
config = json.load(f)
print(config['apiKey'])
```
Accessing Configuration Settings Using Environment Variables
Environment variables provide a dynamic and secure method for accessing configuration settings within a Lambda function. This approach allows for easy modification of configuration values without changing the code itself. Lambda functions provide a dedicated interface for accessing these variables.
To access environment variables in Node.js, the `process.env` object is used. For instance:
```javascript
const apiKey = process.env.API_KEY;
console.log(apiKey);
```
In Python, the `os.environ` dictionary is used to retrieve environment variables:
```python
import os
api_key = os.environ.get('API_KEY')
print(api_key)
```
Environment variables are set in the Lambda function's configuration within the AWS Management Console, the AWS CLI, or infrastructure-as-code tools like AWS CloudFormation or Terraform.
Securely Storing and Retrieving Sensitive Information with AWS Secrets Manager
For sensitive information like API keys, database passwords, and other credentials, AWS Secrets Manager is the recommended approach. Secrets Manager provides secure storage and retrieval of these values, offering features like encryption, access control, and automatic rotation.
The following steps Artikel the process:
- Store the Secret: Create a secret in AWS Secrets Manager. This involves providing a name for the secret and storing the sensitive value. Secrets can be stored as key-value pairs (JSON format) or as plain text.
- Grant Access: Configure an IAM role for the Lambda function that grants permissions to retrieve the secret from Secrets Manager. This is done by attaching a policy to the IAM role that allows the `secretsmanager:GetSecretValue` action for the specific secret or secrets.
- Retrieve the Secret: In the Lambda function code, use the AWS SDK for the appropriate language (e.g., `aws-sdk` for Node.js, `boto3` for Python) to retrieve the secret. The `GetSecretValue` API is called, providing the secret's name. The retrieved value can then be accessed and used.
For example, in Node.js:
```javascript
const AWS = require('aws-sdk');
const secretsManager = new AWS.SecretsManager();
async function getSecret(secretName)
try
const data = await secretsManager.getSecretValue( SecretId: secretName ).promise();
if ('SecretString' in data)
return JSON.parse(data.SecretString);
else
return data.SecretBinary;
catch (error)
console.error("Error retrieving secret:", error);
throw error;
exports.handler = async (event) =>
try
const secrets = await getSecret('my-api-key-secret');
const apiKey = secrets.apiKey;
console.log('API Key:', apiKey);
return
statusCode: 200,
body: JSON.stringify( message: 'API Key retrieved successfully' )
;
catch (error)
return
statusCode: 500,
body: JSON.stringify( error: 'Failed to retrieve API key' )
;
;
```
And in Python:
```python
import boto3
import json
import os
def get_secret(secret_name):
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=os.environ.get('AWS_REGION')
)
try:
get_secret_value_response = client.get_secret_value(
SecretId=secret_name
)
except Exception as e:
print(f"Error getting secret: e")
raise e
if 'SecretString' in get_secret_value_response:
secret = json.loads(get_secret_value_response['SecretString'])
return secret
else:
return secret
def lambda_handler(event, context):
try:
secrets = get_secret('my-api-key-secret')
api_key = secrets.get('apiKey')
print(f"API Key: api_key")
return
'statusCode': 200,
'body': json.dumps('message': 'API Key retrieved successfully')
except Exception as e:
return
'statusCode': 500,
'body': json.dumps('error': f'Failed to retrieve API key: e')
```
Designing a System to Dynamically Update Configuration Files
Dynamically updating configuration files without redeploying a Lambda function can be achieved through several methods, each with its own advantages and disadvantages. The key is to separate the configuration data from the function code and to provide a mechanism for the function to retrieve the updated configuration.
One approach involves using AWS Systems Manager Parameter Store. This service provides a centralized and secure way to store configuration data.
- Store Configuration in Parameter Store: Store the configuration settings as parameters in Systems Manager Parameter Store. Parameters can be stored as plain text, secure strings (encrypted using KMS), or other formats.
- Grant Access to Parameter Store: The Lambda function's IAM role needs permissions to retrieve parameters from Parameter Store (e.g., `ssm:GetParameters`).
- Retrieve Configuration at Runtime: Within the Lambda function code, use the AWS SDK to retrieve the configuration settings from Parameter Store. The function can then use these settings during execution. The code can be modified to periodically check for updates.
For example, using Python:
```python
import boto3
import json
import os
def get_config(parameter_name):
ssm = boto3.client('ssm', region_name=os.environ.get('AWS_REGION'))
try:
response = ssm.get_parameter(Name=parameter_name, WithDecryption=True)
return json.loads(response['Parameter']['Value'])
except Exception as e:
print(f"Error retrieving parameter: e")
return None
def lambda_handler(event, context):
config = get_config('my-app-config')
if config:
api_endpoint = config.get('apiEndpoint')
print(f"API Endpoint: api_endpoint")
return
'statusCode': 200,
'body': json.dumps('message': 'Configuration retrieved successfully')
else:
return
'statusCode': 500,
'body': json.dumps('error': 'Failed to retrieve configuration')
```
Another approach is using an external configuration service or data store.
- Store Configuration in an External Service: Utilize a service like AWS DynamoDB, AWS S3 (for storing JSON or YAML files), or a third-party configuration management platform.
- Grant Access to the Service: Configure the Lambda function's IAM role to allow access to the external service (e.g., read access to an S3 bucket, read/write access to a DynamoDB table).
- Retrieve Configuration at Runtime: The Lambda function retrieves the configuration data from the external service. The function can be designed to periodically poll the service for updates or to react to events (e.g., a DynamoDB stream event indicating a configuration change).
This method provides greater flexibility, allowing for more complex configuration management scenarios, but introduces dependencies on external services and requires careful consideration of latency and cost implications. A DynamoDB table, for example, can be designed to store configuration data with versioning, allowing for rollback capabilities. S3 can be used to store configuration files that are updated and then reloaded by the Lambda function.
For both methods, careful consideration should be given to the following:
- Caching: Implement caching mechanisms (e.g., in-memory caching) to reduce the frequency of calls to the configuration service, improving performance and reducing costs.
- Error Handling: Implement robust error handling to gracefully manage situations where the configuration service is unavailable or returns an error.
- Security: Securely store and access sensitive configuration data, using encryption and appropriate access controls.
- Updates: Implement strategies for propagating configuration updates to all instances of the Lambda function, such as using a broadcast mechanism or by triggering function invocations upon configuration changes.
Monitoring and Logging Dependencies
Monitoring and logging are crucial for maintaining the health and performance of Lambda functions, especially those that rely on external dependencies. Effective monitoring allows for proactive identification of performance bottlenecks and potential issues stemming from dependencies. Robust logging provides detailed insights into dependency-related errors and warnings, facilitating rapid troubleshooting and resolution.
Monitoring Lambda Function Performance with Dependencies
Monitoring the performance of Lambda functions with dependencies requires a multifaceted approach, encompassing metrics related to function execution, dependency behavior, and resource utilization. This is achieved through cloud-based monitoring services like Amazon CloudWatch, which provide a centralized platform for collecting, analyzing, and visualizing data.
- Function Execution Metrics: These metrics provide a baseline understanding of the function's overall performance. They include:
- Invocation Count: The number of times the function is executed. This metric helps to understand the function's workload.
- Duration: The time taken for the function to complete execution, measured in milliseconds. Analyzing duration over time can reveal performance degradations caused by dependency issues, such as slow network requests or inefficient library usage.
- Errors: The number of errors encountered during function execution. An increase in errors can indicate problems with dependencies, such as incompatible versions or missing resources.
- Throttles: The number of times the function execution was throttled due to resource limitations. This can be a sign of dependencies consuming excessive resources.
- Dependency-Specific Metrics: These metrics provide insight into the behavior of dependencies. They often require custom instrumentation within the function code.
- Network Latency: The time taken for network requests to dependencies. High latency can significantly impact function duration. Measuring latency to external APIs or databases is crucial.
- Dependency Call Counts: The number of calls made to specific dependencies. This can help identify inefficient code or excessive dependency usage.
- Dependency Error Rates: The rate at which errors occur when interacting with dependencies. A high error rate suggests problems with the dependency itself.
- Resource Utilization Metrics: These metrics track the resources consumed by the function.
- Memory Usage: The amount of memory consumed by the function. Dependencies can significantly increase memory usage, potentially leading to performance issues or function failures.
- CPU Utilization: The percentage of CPU time used by the function. High CPU utilization may indicate inefficient dependency usage or resource-intensive operations within the dependencies.
Logging Dependency-Related Errors and Warnings
Effective logging is essential for diagnosing and resolving issues related to dependencies. Logging should capture critical information about errors, warnings, and other relevant events. This allows for the creation of a comprehensive audit trail that facilitates debugging and performance optimization.
- Error Logging: Errors should be logged with sufficient detail to facilitate troubleshooting. This includes:
- Error Message: A clear and concise description of the error.
- Timestamp: The time the error occurred.
- Function Name: The name of the Lambda function.
- Request ID: The unique identifier for the function invocation.
- Dependency Name and Version: The name and version of the dependency that caused the error.
- Stack Trace: A detailed stack trace to pinpoint the source of the error within the code and dependencies.
- Warning Logging: Warnings should be logged to highlight potential issues that may not immediately cause errors but could lead to problems in the future. Examples include:
- Deprecated Dependency Usage: Warnings when using deprecated features of a dependency.
- Dependency Version Conflicts: Warnings about potential conflicts between dependency versions.
- Slow Dependency Operations: Warnings about operations that are taking longer than expected.
- Informational Logging: Provide context to the function execution. This is particularly useful to understand the data flow.
- Start and End of Dependency Calls: Log the start and end of calls to dependencies, including the duration.
- Input and Output Data: Log relevant input and output data for dependency calls (with appropriate redaction of sensitive information).
Best Practices for Logging Dependency-Related Errors
Implementing robust logging practices is critical for efficient troubleshooting. These practices enhance the clarity and usefulness of log data.
- Use Structured Logging: Employ structured logging formats, such as JSON, to facilitate parsing and analysis. Structured logs allow for easier filtering, searching, and aggregation of log data.
- Include Contextual Information: Always include relevant context in log messages, such as function name, request ID, dependency name, and version. This context enables you to quickly understand the environment in which the error occurred.
- Log Severity Levels: Utilize appropriate log levels (e.g., ERROR, WARN, INFO, DEBUG) to categorize log messages based on their severity. This allows you to filter and prioritize log data based on the urgency of the issue.
- Redact Sensitive Information: Be mindful of sensitive information. Before logging any data, redact any Personally Identifiable Information (PII), API keys, or other sensitive data.
- Centralized Logging: Send logs to a centralized logging service, such as CloudWatch Logs, for easy access and analysis. Centralized logging allows you to aggregate logs from multiple Lambda functions and other services in one place.
Code Example: Logging Best Practices for Dependency-Related Errors (Node.js)
The following code block demonstrates best practices for logging dependency-related errors in a Node.js Lambda function using the `winston` logging library. This example encapsulates error handling, structured logging, and context inclusion.
```javascript
const winston = require('winston');
// Configure Winston logger
const logger = winston.createLogger(
level: 'info',
format: winston.format.json(),
defaultMeta: service: 'my-lambda-function' ,
transports: [
new winston.transports.Console(), // Output to console (CloudWatch Logs)
],
);
exports.handler = async (event, context) =>
const requestId = context.awsRequestId;
try
// Simulate a dependency call
const result = await makeDependencyCall();
logger.info('Dependency call successful', requestId, dependency: 'my-dependency', result );
return
statusCode: 200,
body: JSON.stringify( message: 'Success', result ),
;
catch (error)
logger.error('Dependency call failed',
requestId,
dependency: 'my-dependency',
error: error.message,
stack: error.stack,
);
return
statusCode: 500,
body: JSON.stringify( message: 'Error', error: error.message ),
;
;
async function makeDependencyCall()
// Simulate an error
const simulateError = Math.random() < 0.5; // 50% chance of error if (simulateError) throw new Error('Simulated dependency error'); // Simulate a successful call return status: 'success', data: value: 'some data' ; ```The code above shows a Lambda function that:
- Initializes a Winston logger configured to output structured JSON logs to the console (which is captured by CloudWatch Logs).
- Includes the function name in the default metadata for each log entry.
- Wraps a dependency call (simulated here) in a `try...catch` block to handle potential errors.
- Logs successful dependency calls with an `INFO` level, including the request ID, dependency name, and result.
- Logs dependency errors with an `ERROR` level, including the request ID, dependency name, error message, and stack trace. This is crucial for debugging.
- The `makeDependencyCall` function simulates an error to demonstrate error handling.
Advanced Techniques: Container Images and Custom Runtimes

Leveraging container images and custom runtimes represents a significant advancement in managing dependencies within AWS Lambda functions. This approach offers enhanced control, portability, and flexibility, especially when dealing with complex dependencies or specialized runtime environments. Containerization simplifies the deployment process and streamlines the management of dependencies, leading to more efficient and reproducible function execution.
Benefits of Using Container Images for Packaging Lambda Functions
Container images provide several advantages for Lambda function deployments. These benefits stem from the standardized and isolated nature of containers, which encapsulate the function code, dependencies, and runtime environment.
- Dependency Isolation: Container images isolate the function's dependencies from the underlying Lambda execution environment. This isolation minimizes the risk of conflicts with system libraries and ensures consistent behavior across different deployments. This contrasts with traditional deployment methods where dependency conflicts could arise from shared libraries.
- Reproducibility: Container images guarantee consistent behavior across different environments. The same image, when deployed, will always produce the same results, irrespective of the underlying infrastructure. This reproducibility is critical for debugging and maintaining the function over time.
- Portability: Container images are portable across different platforms and environments, including local development machines, CI/CD pipelines, and various AWS regions. This portability simplifies the deployment process and allows for easy migration between different infrastructures.
- Simplified Dependency Management: Container images simplify the process of managing dependencies. All dependencies are packaged within the image, reducing the need for manual configuration or external package management tools within the Lambda function itself. This is especially beneficial when using numerous or complex dependencies.
- Custom Runtimes: Container images facilitate the use of custom runtimes. This capability allows developers to use programming languages or frameworks not natively supported by AWS Lambda, expanding the range of possible applications.
Building a Container Image That Includes Dependencies
Creating a container image for a Lambda function involves several key steps, starting with defining a Dockerfile. This file specifies the base image, installs dependencies, and configures the function's entry point.
- Dockerfile Creation: A Dockerfile is created to define the image. This file specifies the base image, the working directory, the installation of dependencies, the function code, and the entry point. For example, a Python function might use a base image like `python:3.9-slim-buster`.
- Dependency Installation: Within the Dockerfile, dependencies are installed using the package manager appropriate for the language and base image. For Python, this typically involves using `pip` to install packages from a `requirements.txt` file. For Node.js, the dependencies would be installed using `npm install`.
- Code Copying: The function code is copied into the image, typically into the working directory specified in the Dockerfile. This ensures the code is accessible to the runtime environment within the container.
- Entry Point Configuration: The Dockerfile specifies the entry point, which is the command executed when the container starts. This entry point usually invokes the Lambda function handler. The entry point should be configured to receive and process the events.
- Image Building: The Docker image is built using the `docker build` command, which uses the Dockerfile to create the image. The command specifies the build context (usually the directory containing the Dockerfile) and tags the image with a name and version.
- Image Pushing: The built image is pushed to a container registry, such as Amazon Elastic Container Registry (ECR), to make it accessible for deployment to Lambda. This allows Lambda to pull the image and execute the function.
Here is an example Dockerfile for a Python Lambda function:
```dockerfile
FROM public.ecr.aws/lambda/python:3.9
# Set the working directory
WORKDIR /app
# Copy requirements.txt
COPY requirements.txt .
# Install dependencies
RUN pip3 install -r requirements.txt --target "$LAMBDA_TASK_ROOT"
# Copy function code
COPY lambda_function.py .
# Set the handler
CMD ["lambda_function.lambda_handler"]
```
This Dockerfile installs the dependencies listed in `requirements.txt` and then copies the `lambda_function.py` file into the container. The `CMD` instruction specifies the function's handler.
Creating and Deploying a Custom Runtime for a Lambda Function
Creating a custom runtime enables the use of languages or frameworks not natively supported by AWS Lambda. This involves building an executable that receives and processes Lambda invocation events and sends the responses back to Lambda.
- Runtime Implementation: The custom runtime is implemented in a language of choice (e.g., Go, Rust, C++). It needs to communicate with the Lambda runtime API. This API is used to fetch invocation events and send back responses.
- Executable Compilation: The runtime code is compiled into an executable. This executable will be the entry point of the container image.
- Container Image Creation: A container image is created, including the custom runtime executable. The Dockerfile should specify the executable as the entry point.
- Deployment to Lambda: The container image is deployed to Lambda. The Lambda function is configured to use the custom runtime. The function handler is set to the runtime executable.
The custom runtime executable typically performs the following steps:
- Initialization: The runtime initializes itself and establishes a connection with the Lambda runtime API.
- Event Retrieval: It fetches invocation events from the Lambda runtime API.
- Function Invocation: It invokes the function handler, passing the event data as input.
- Response Transmission: It sends the function's response back to the Lambda runtime API.
- Error Handling: It handles any errors that occur during the invocation and sends error information to the Lambda runtime API.
Diagram: Container Images Streamlining Dependency Management
The diagram below illustrates how container images streamline dependency management in Lambda functions. It highlights the key components and their interactions.
Diagram Description:
The diagram is a simplified illustration depicting the flow of a Lambda function execution using a container image. It shows three main components: "Developer's Machine," "Container Image," and "AWS Lambda Service." Arrows represent the flow of information and actions.
Developer's Machine: This section represents the developer's environment, where the function code and dependencies are managed. It is connected to the "Container Image" component. The Developer's Machine includes the code, a requirements file, and a Dockerfile. The Dockerfile is used to create the container image, which encapsulates all dependencies and the function code.
Container Image: This central component represents the containerized Lambda function. Inside, the image holds the application code, all the dependencies (e.g., libraries), and the runtime environment necessary for execution. This image is stored in a container registry (e.g., ECR) and is ready to be deployed to AWS Lambda.
AWS Lambda Service: This section represents the AWS Lambda service, where the container image is deployed and executed. When an event triggers the Lambda function, the service pulls the container image from the registry, creates a container instance, and executes the function code within the container. The function processes the event and returns a response, which is then handled by AWS Lambda.
Flow of Execution: The flow begins with the developer creating the code and defining the dependencies. The developer then builds the container image using the Dockerfile. This image is pushed to a container registry. When the Lambda function is invoked, AWS Lambda pulls the image, creates a container instance, and executes the function code, which utilizes the packaged dependencies. The result is sent back to the caller.
Benefits Illustrated: The diagram clearly illustrates the key benefits of using container images: encapsulation of dependencies, portability (deploying the same image across different environments), and simplified deployment.
Last Point
In conclusion, effective dependency management is paramount for building robust and scalable Lambda functions. This guide has illuminated various strategies, from leveraging Lambda layers and build tools to addressing conflicts and integrating external libraries. By implementing the best practices Artikeld here, developers can significantly improve the performance, reliability, and maintainability of their serverless applications. Understanding these techniques empowers developers to create efficient, deployable, and well-organized Lambda functions, ultimately maximizing the benefits of serverless computing.
Clarifying Questions
What is a Lambda layer and why should I use it?
A Lambda layer is a ZIP archive containing libraries, custom runtimes, or other dependencies that can be used by multiple Lambda functions. Layers promote code reuse, reduce package size for individual functions, and simplify updates. This leads to faster deployment times and improved code organization.
How do I update a Lambda layer and ensure my functions use the updated version?
To update a layer, you rebuild the layer's content, package it into a new ZIP file, and upload it to AWS. Then, you update the Lambda function's configuration to point to the new layer version. Redeploying the function will then utilize the updated dependencies.
What are the size limits for Lambda function deployment packages and layers?
The unzipped deployment package size limit for a Lambda function is 250MB. For Lambda layers, the unzipped size limit is 250MB per layer, and a function can use up to 5 layers. These limits apply to the total size of the code and dependencies used by the function.
How can I handle different versions of the same dependency across multiple Lambda functions?
Using Lambda layers is a good practice to isolate and manage dependencies. You can create separate layers for different versions of the same dependency and configure each Lambda function to use the specific layer version it requires. This avoids conflicts and ensures each function operates with its intended dependencies.
How do I debug dependency-related issues in my Lambda function?
Utilize proper logging to capture errors and warnings related to dependency loading and execution. Check the function's CloudWatch logs for any error messages or stack traces. Also, verify that your dependencies are correctly packaged and accessible to the function's runtime environment.