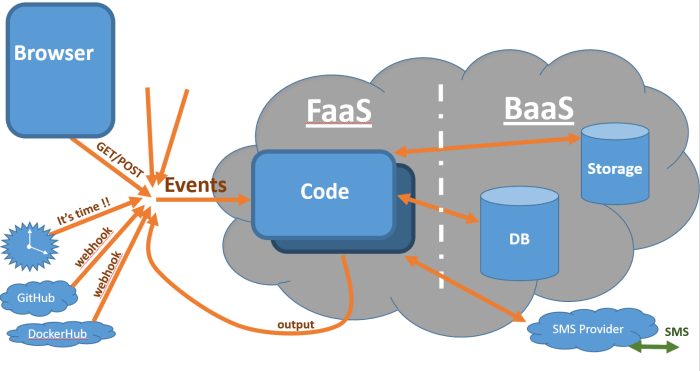
Serverless computing, a paradigm shift in application development, allows developers to focus on code without managing infrastructure. A fundamental aspect of this model is the concept of execution time limits, a critical constraint that dictates how long a serverless function can run before being terminated. These limits, while providing benefits such as cost control and resource management, introduce complexities that developers must carefully navigate.
This discussion delves into the nuances of these time constraints, exploring their impact on application design, optimization strategies, and the broader implications for serverless architectures.
The serverless landscape is populated by platforms with varying time limits, each influencing the architecture and performance of applications. Understanding these limits, from the default values to the maximum allowable duration, is paramount. Furthermore, the reasons behind these restrictions are multifaceted, encompassing cost efficiency, protection against resource exhaustion, and mitigation of potential denial-of-service attacks. This analysis will provide a comprehensive understanding of the constraints and the associated trade-offs in serverless development.
Introduction to Serverless Execution Time Limits
Serverless computing represents a paradigm shift in cloud computing, enabling developers to build and run applications without managing servers. This approach focuses on abstracting away infrastructure concerns, allowing developers to concentrate on writing code and deploying functions. Execution time limits are a fundamental aspect of serverless architecture, influencing how developers design and optimize their applications.
Core Principles of Serverless Computing
Serverless computing, at its core, embodies several key principles:
- Abstraction of Infrastructure: The cloud provider manages the underlying infrastructure, including servers, operating systems, and scaling. Developers do not provision or maintain any servers.
- Event-Driven Architecture: Serverless functions are typically triggered by events, such as HTTP requests, database updates, or scheduled timers. This event-driven model allows for highly responsive and scalable applications.
- Pay-per-Use Pricing: Users are charged only for the actual compute time consumed by their functions, leading to cost optimization, especially for applications with variable workloads.
- Automatic Scaling: Serverless platforms automatically scale the resources allocated to functions based on demand, ensuring optimal performance and availability.
Execution Time Limits in Serverless Functions
Execution time limits, also known as function timeouts, are a crucial characteristic of serverless platforms. They define the maximum duration a serverless function can run before being terminated by the provider. This limit is imposed to manage resource allocation, prevent runaway processes, and maintain the stability and performance of the overall serverless environment.
Benefits and Drawbacks of Execution Time Limits for Developers
Execution time limits introduce both advantages and disadvantages for developers. Understanding these trade-offs is essential for effective serverless application design.
- Benefits:
- Cost Control: Execution time limits help control costs by preventing functions from consuming excessive resources. This is especially beneficial for applications with unpredictable workloads.
- Resource Management: Limits prevent a single function from monopolizing resources, ensuring fairness and stability across the platform.
- Security: Timeouts can mitigate the impact of malicious or poorly written code, preventing them from consuming excessive resources or causing denial-of-service (DoS) conditions.
- Drawbacks:
- Function Design Constraints: Execution time limits can restrict the complexity and scope of functions, requiring developers to break down large tasks into smaller, more manageable units.
- Debugging Challenges: Debugging functions that exceed the time limit can be complex, requiring developers to analyze logs and identify performance bottlenecks.
- Architectural Considerations: Developers must carefully consider the execution time when designing their applications, choosing appropriate programming languages and optimizing code for performance.
Common Serverless Platforms and Their Limits
Serverless computing, while offering significant benefits in terms of scalability and cost-effectiveness, introduces constraints that developers must carefully consider. One of the most critical of these is the execution time limit. This limit dictates the maximum duration a function can run before being terminated. Understanding these limits is crucial for designing and deploying serverless applications that function reliably and efficiently.
Different platforms impose varying limits, influencing the architectural choices and optimization strategies employed by developers.
Platform Overview and Execution Time Limits
Several prominent serverless platforms dominate the market, each with its own set of features and limitations. These platforms provide the infrastructure and tools necessary to execute functions in response to various triggers, such as HTTP requests, database updates, or scheduled events. The execution time limit is a key differentiator, directly impacting the complexity of the tasks that can be handled and the overall application design.
The following table summarizes the execution time limits for some popular serverless platforms. This information is current as of October 26, 2023, but it’s essential to consult the official documentation of each platform for the most up-to-date information, as these limits are subject to change.
| Platform | Default Limit | Maximum Limit | Notes |
|---|---|---|---|
| AWS Lambda | 3 seconds | 15 minutes (900 seconds) | The default limit is typically sufficient for many short-lived functions. The maximum limit is suitable for more complex workloads, such as data processing or long-running computations, but requires careful design to avoid exceeding the limit. |
| Azure Functions | 10 minutes | 10 minutes (Consumption plan) / Unlimited (App Service plan) | The Consumption plan, designed for pay-per-execution pricing, has a 10-minute limit. The App Service plan, which provides dedicated resources, allows for longer execution times, effectively unlimited depending on the service plan configuration. |
| Google Cloud Functions | 1 minute (1st gen) / 9 minutes (2nd gen) | 9 minutes (1st gen) / 60 minutes (2nd gen) | Google Cloud Functions offers two generations. The first generation has a shorter default and maximum limit compared to the second generation. The second generation provides enhanced performance and longer execution times, suitable for a wider range of use cases. |
Comparative Analysis of Execution Time Limits
The execution time limits across these platforms demonstrate a range of capabilities. AWS Lambda, with its relatively flexible maximum limit of 15 minutes, caters to a broad spectrum of use cases, from simple API endpoints to more involved data processing tasks. Azure Functions offers a distinction based on the hosting plan. The Consumption plan, optimized for cost-efficiency, imposes a 10-minute limit, while the App Service plan offers greater flexibility, enabling long-running processes.
Google Cloud Functions provides a more nuanced approach, with the first and second generations having different limits. The 2nd gen functions support a longer maximum execution time than 1st gen functions, allowing more complex operations.The choice of platform and function design must align with the anticipated workload and the potential for tasks to exceed the execution time limit. For example, if a function needs to process large datasets or perform computationally intensive operations, a platform with a higher maximum limit or a different architectural approach, such as breaking the task into smaller, independent functions, is essential.
Conversely, for functions designed to respond to user interactions or handle lightweight API calls, the default limits are usually sufficient. Understanding these limits allows developers to select the appropriate platform, optimize function code, and design resilient serverless applications that meet performance requirements.
Reasons for Execution Time Limits
Serverless computing, with its pay-per-use model, introduces inherent complexities in resource management. Execution time limits are a critical component of this model, addressing several key concerns related to cost, resource allocation, and security. These limits are not arbitrary; they are carefully considered design choices that optimize the operational efficiency and financial viability of serverless platforms.
Cost Optimization Mechanisms
Execution time limits are directly linked to cost optimization in serverless environments. By capping the duration of function executions, providers can control the resources consumed and, consequently, the charges incurred by users.
- Precise Resource Allocation: Serverless platforms charge based on the amount of compute time used. Shorter execution times translate directly into lower costs. Limits encourage developers to write efficient code that executes quickly, optimizing resource utilization. For example, if a function takes 500 milliseconds to execute, the cost is determined by that duration. A time limit of, say, 60 seconds prevents a runaway process from consuming excessive resources and accruing substantial charges.
- Preventing Uncontrolled Spending: Without limits, a poorly written or inefficient function could potentially run indefinitely, leading to significant and unexpected costs. Execution time limits act as a safeguard, preventing runaway processes from depleting a user’s budget. This predictability is crucial for financial planning. Consider a scenario where a function inadvertently enters an infinite loop. Without a time limit, this could quickly consume the user’s allocated resources and incur substantial costs.
- Incentivizing Efficient Code: Limits encourage developers to optimize their code for performance. Developers are incentivized to profile and improve their functions to minimize execution time, thereby reducing costs. Techniques such as code profiling, efficient data structures, and optimized algorithms become essential for cost-effective serverless development. For example, choosing a more efficient algorithm for a computationally intensive task can dramatically reduce execution time and cost.
Resource Exhaustion Prevention
Execution time limits play a vital role in preventing resource exhaustion within the serverless infrastructure. This is essential for maintaining the overall stability and availability of the platform.
- Protecting Shared Resources: Serverless platforms operate on a shared infrastructure model. Limits prevent individual functions from monopolizing resources like CPU, memory, and network bandwidth, ensuring that other functions can also execute. Without limits, a single, resource-intensive function could starve other functions of necessary resources, leading to performance degradation or even service outages.
- Maintaining Platform Stability: By limiting the execution time, the platform can prevent a single function from impacting the overall stability of the system. Long-running or poorly optimized functions can degrade performance for other users and potentially trigger cascading failures. Time limits act as a safety net, preventing a single function from causing widespread disruption.
- Fair Resource Allocation: Execution time limits contribute to fair resource allocation among all users of the serverless platform. By preventing any single function from consuming excessive resources, the platform can ensure that all users have access to the necessary resources to run their applications. This promotes a more equitable and reliable computing environment.
Denial-of-Service (DoS) Attack Mitigation
Execution time limits are a critical security measure against denial-of-service (DoS) attacks, where malicious actors attempt to exhaust the resources of a system, making it unavailable to legitimate users.
- Thwarting Resource Exhaustion Attacks: By limiting execution time, the platform can mitigate the impact of DoS attacks that aim to consume excessive compute time. Even if an attacker manages to trigger numerous function invocations, the time limit will prevent each invocation from running indefinitely, thereby limiting the total resource consumption.
- Protecting Against Malicious Code: Execution time limits can also protect against malicious code that is designed to consume excessive resources. If a function contains malicious code that attempts to run indefinitely or consume large amounts of CPU or memory, the time limit will prevent it from doing so, thereby limiting the damage.
- Mitigating Distributed Denial-of-Service (DDoS) Attacks: In the context of DDoS attacks, where an attacker uses multiple sources to overwhelm a system, execution time limits are still relevant. While they may not stop the attack entirely, they can limit the impact by preventing each individual function invocation from consuming an excessive amount of resources.
Impact of Time Limits on Application Design
Serverless execution time limits are a fundamental constraint that profoundly shapes the architecture and implementation of serverless applications. These limits necessitate a shift in design philosophy, moving away from monolithic, long-running processes towards distributed, event-driven architectures. Developers must strategically decompose applications to adhere to these constraints, optimizing for scalability, resilience, and cost-effectiveness. Failure to address execution time limits can lead to unpredictable application behavior, including function timeouts, data loss, and increased operational costs.
Architectural Implications of Time Limits
The imposed time limits force developers to adopt architectural patterns that prioritize short-lived, stateless functions. This shift necessitates careful consideration of how tasks are broken down, data is managed, and state is preserved across function invocations. The choice of architecture significantly impacts the overall performance, scalability, and maintainability of the application.
- Event-Driven Architectures: Serverless applications frequently leverage event-driven architectures. These architectures use events to trigger functions, decoupling different parts of the application. When a user uploads a file, an event is generated, triggering a function to process the file. This function, in turn, can generate other events, leading to other functions. This architecture allows for parallel processing and scaling, optimizing for the short-lived nature of serverless functions.
For example, consider an image processing pipeline: an upload event triggers a function to resize the image, another function to create thumbnails, and yet another to store the processed images. Each function executes independently, minimizing the impact of time limits.
- Microservices: Decomposing an application into microservices is another critical architectural pattern. Each microservice encapsulates a specific business capability, allowing for independent development, deployment, and scaling. The microservices communicate via APIs or message queues. This pattern enables teams to focus on specific functionalities and optimize the performance of individual components. Consider an e-commerce platform.
Microservices can be created for product catalog management, order processing, user authentication, and payment processing. Each microservice can be scaled independently, making efficient use of serverless resources and mitigating the risk of exceeding execution time limits.
- Asynchronous Operations: Asynchronous operations are essential for handling long-running tasks without blocking function execution. Functions can initiate asynchronous tasks, such as database updates or external API calls, and return immediately. The function then receives the result through callbacks or by polling the status of the asynchronous task. This allows the function to return before the task completes, staying within time limits.
A common example is sending emails. A function can trigger an email sending task and return, even if the email sending process takes longer than the function’s execution limit.
Strategies for Managing Long-Running Tasks
Effectively managing long-running tasks is crucial in a serverless environment. Several techniques can be employed to break down large tasks into smaller, more manageable functions, thereby staying within execution time limits.
- Function Chaining: Function chaining involves linking multiple functions together to form a pipeline. One function triggers the next upon completion, allowing a series of operations to be performed sequentially. This pattern is suitable for tasks that can be logically broken down into discrete steps. For instance, a video encoding process can be split into functions for format conversion, resolution adjustment, and compression.
Each function completes a specific task, and triggers the subsequent one.
- Fan-Out/Fan-In: This pattern is suitable for parallelizing tasks. A “fan-out” function distributes work across multiple worker functions, which perform the same task on different data. A “fan-in” function aggregates the results from the worker functions. This pattern dramatically reduces execution time for tasks that can be parallelized. Imagine processing a large dataset: a function can distribute the data across multiple worker functions for parallel processing.
The fan-in function then combines the results.
- Using Message Queues: Message queues, such as Amazon SQS or Azure Queue Storage, provide a robust mechanism for decoupling functions and handling asynchronous operations. Long-running tasks can be placed in a queue, and separate worker functions can consume messages from the queue to process the tasks. This allows functions to offload work and operate independently of each other. This is especially useful for batch processing operations.
For example, a large report generation task can be broken down into individual report segments, each added to a message queue. Worker functions then process each segment independently.
- State Management: Managing state is essential for handling long-running tasks. Serverless functions are inherently stateless, meaning they do not retain state between invocations. To maintain state, developers can use databases, object storage, or distributed caching systems. Careful consideration must be given to how state is managed, especially regarding consistency and data integrity. For example, during a long-running process, progress can be tracked in a database.
Each function updates the progress status, allowing for monitoring and resumption if the function fails.
Illustrative Examples of Task Decomposition
To demonstrate these concepts, let’s consider several practical scenarios.
- Large File Processing: Imagine processing a large CSV file. Instead of a single function attempting to read and process the entire file within the time limit, you could break it down using function chaining. A first function could read the file and split it into smaller chunks, each written to a storage service. A second function could then be triggered for each chunk, performing data transformation and validation.
Finally, a third function could aggregate the results.
- Complex Calculations: For computationally intensive tasks, such as scientific simulations or financial modeling, the fan-out/fan-in pattern becomes advantageous. A function distributes the calculation across multiple worker functions, each processing a subset of the data. The worker functions then return their results, which the main function aggregates.
- Background Jobs: For tasks like sending bulk emails or generating reports, message queues are a good choice. A function adds tasks to a queue, and worker functions pick up and process them asynchronously. This ensures that the main function returns quickly, while the background jobs are handled without blocking.
Monitoring and Measuring Execution Time
Effective monitoring and measurement of serverless function execution time are crucial for performance optimization, cost management, and overall application health. By tracking execution duration, developers can identify bottlenecks, ensure compliance with service level agreements (SLAs), and proactively address potential issues before they impact users. This proactive approach enables informed decision-making and allows for continuous improvement of serverless applications.
Monitoring Execution Time of Serverless Functions
Serverless platforms typically provide built-in monitoring capabilities that allow developers to track the execution time of their functions. These tools often integrate with logging and tracing systems to provide a comprehensive view of function behavior.The primary method for monitoring involves accessing platform-provided dashboards and metrics. These dashboards offer real-time and historical data on function invocations, execution durations, and other relevant performance indicators.
Furthermore, most platforms allow for the creation of custom dashboards tailored to specific monitoring needs. The ability to set up alerts based on predefined thresholds (e.g., exceeding a certain execution time) is another key feature. These alerts notify developers of potential problems, enabling rapid response and mitigation.In addition to platform-specific monitoring, third-party monitoring solutions can be integrated. These tools often offer more advanced features, such as distributed tracing and application performance monitoring (APM), providing a more granular view of function execution across multiple services.
Tools and Techniques for Measuring Function Performance
Measuring function performance involves a combination of techniques and tools, ensuring a detailed understanding of execution characteristics. The selection of appropriate tools depends on the platform used and the specific performance aspects being investigated.One fundamental technique is utilizing the platform’s built-in logging and monitoring services. Most serverless platforms automatically log key events, including function invocation start and end times, allowing for the calculation of execution duration.
These logs can be analyzed using various tools, such as the platform’s own query language or third-party log analysis solutions.Distributed tracing is another powerful technique, particularly for applications that involve multiple serverless functions or microservices. Tracing tools provide a detailed view of how requests propagate through the system, identifying bottlenecks and performance issues in individual function calls. This helps visualize the flow of requests and identify areas where optimization is needed.Profiling tools can also be used to identify performance bottlenecks within the function’s code itself.
These tools analyze the function’s execution, identifying areas where code is consuming the most time or resources. This information can then be used to optimize the code and improve overall performance.Finally, load testing tools simulate real-world traffic patterns, allowing developers to assess function performance under varying load conditions. This helps to identify potential scaling issues and ensures that functions can handle the expected workload.
For example, a load test might simulate 100 concurrent users accessing a function, measuring the average execution time and the number of successful invocations.
Common Metrics to Track
Tracking specific metrics is essential for understanding and optimizing serverless function performance. The following metrics provide a comprehensive view of function behavior:
- Average Execution Time: This metric represents the average time taken for a function to complete its execution across all invocations. It is calculated by summing the execution times of all invocations and dividing by the total number of invocations. This metric provides a general overview of function performance and can be used to identify trends over time. For instance, if the average execution time increases, it could indicate a performance degradation that needs investigation.
- Maximum Execution Time: This metric represents the longest time taken for any single function invocation. It is particularly useful for identifying outliers and potential performance bottlenecks. Extremely long execution times can indicate issues such as inefficient code, resource contention, or cold starts.
- Minimum Execution Time: The shortest time observed for a function’s execution. This metric can be useful in understanding the theoretical best-case performance of the function.
- Invocation Count: This metric represents the total number of times a function has been invoked within a specific time period. It provides insight into the function’s usage and workload.
- Error Rate: The percentage of function invocations that resulted in errors. This metric is critical for assessing the reliability of the function. A high error rate can indicate issues such as code bugs, external service failures, or resource limitations.
- Successful Invocations: The number of function invocations that completed without errors. This metric is essential for understanding the function’s operational effectiveness.
- Cold Start Percentage: The percentage of invocations that experienced a cold start, where the function’s execution environment had to be initialized. This metric is particularly important for functions that are not frequently invoked, as cold starts can significantly impact execution time. For instance, if a function has a high cold start percentage, developers might consider optimizing the function’s startup time or increasing the provisioned concurrency.
- Memory Usage: The amount of memory consumed by the function during execution. Tracking memory usage is important for ensuring that the function does not exceed its allocated memory limit, which can lead to errors or performance degradation.
- Concurrency: The number of function instances that are running concurrently. Monitoring concurrency helps to understand the function’s scalability and resource utilization.
- Duration Distribution: The distribution of execution times, often visualized using histograms or percentiles. This provides a more detailed understanding of function performance, revealing patterns and outliers. For example, the 95th percentile execution time represents the execution time below which 95% of invocations fall.
Strategies for Optimizing Function Execution Time
Optimizing serverless function execution time is critical for cost efficiency, performance, and overall application responsiveness. Several strategies can be employed to reduce the duration of function invocations, mitigating the limitations imposed by execution time limits. These strategies span code optimization, architectural considerations, and the utilization of performance-enhancing techniques.
Code Optimization Techniques
Code optimization is a fundamental approach to reducing execution time. This involves streamlining the code itself to minimize the operations performed and the resources consumed.
Efficient coding practices vary based on the programming language, but common principles apply universally.
- Algorithm Efficiency: The choice of algorithm significantly impacts performance. Using algorithms with lower time complexity (e.g., O(log n) instead of O(n)) is crucial for large datasets. For example, consider the difference between searching a sorted array using binary search (O(log n)) versus a linear search (O(n)). Binary search drastically reduces the number of comparisons required, especially for extensive datasets.
- Code Profiling: Profiling tools identify performance bottlenecks within the code. These tools provide insights into which parts of the code consume the most time. For instance, a profiler might reveal that a specific loop is taking an excessive amount of time, allowing developers to focus optimization efforts there.
- Minimize Dependencies: Reducing the number and size of dependencies helps to decrease the cold start time and overall execution time. Evaluate the necessity of each library and consider using lightweight alternatives. For example, instead of using a large, general-purpose library, utilize a specific, smaller library that performs the required tasks.
- Lazy Loading: Delay the loading of resources until they are needed. This can significantly reduce the initial load time of a function. An example is loading a configuration file only when it is first accessed.
- Optimized Data Structures: Choose appropriate data structures for the task at hand. The selection of a suitable data structure can optimize the performance of operations. For example, using a hash table (dictionary or map) for fast lookups is more efficient than using a list when searching for a specific element.
- Avoid Unnecessary Operations: Eliminate redundant computations and operations. This includes avoiding unnecessary loops, function calls, and object creations. For example, pre-calculating values that are used multiple times can save significant processing time.
Language-specific optimizations further enhance performance.
- Python:
- Use list comprehensions instead of explicit loops for faster data manipulation.
- Leverage built-in functions, as they are often optimized for performance.
- Consider using libraries like NumPy for numerical computations, which are optimized for array operations.
- JavaScript (Node.js):
- Optimize asynchronous operations using `async/await` or Promises to avoid blocking the event loop.
- Minimize the use of blocking operations.
- Use efficient data structures for data storage and retrieval.
- Java:
- Use efficient data structures like `HashMap` and `ArrayList`.
- Optimize object creation and garbage collection by reusing objects where possible.
- Use appropriate Java Virtual Machine (JVM) settings for performance tuning.
Performance-Enhancing Techniques
Several techniques can be employed to improve the performance of serverless functions, particularly regarding execution time. These techniques often involve caching, connection pooling, and other strategies designed to reduce latency and improve efficiency.
- Caching: Caching is a fundamental technique to reduce execution time by storing frequently accessed data in a fast-access storage. This reduces the need to repeatedly compute or retrieve data from slower sources.
- In-Memory Caching: For data that can fit within the function’s memory, in-memory caching can provide the fastest access times.
- Distributed Caching: For larger datasets or data shared across multiple functions, distributed caching services like Redis or Memcached are suitable. These services provide fast, scalable storage for cached data.
- Caching at the API Gateway: API gateways can cache responses, reducing the load on serverless functions for frequently requested data.
- Connection Pooling: Establishing database connections can be time-consuming. Connection pooling involves maintaining a pool of pre-established database connections that can be quickly reused by serverless functions, reducing connection overhead.
- Asynchronous Operations: Utilize asynchronous operations to prevent functions from blocking while waiting for I/O operations. This allows the function to continue processing other tasks while waiting for the I/O operation to complete, reducing the overall execution time.
- Reduce Cold Start Times: Cold starts can significantly impact execution time. Several strategies can be used to mitigate this.
- Provisioned Concurrency: Some serverless platforms offer provisioned concurrency, allowing you to pre-warm function instances, reducing the likelihood of cold starts.
- Keep Functions Warm: Regularly invoke functions to keep them warm and prevent them from being idle for too long.
- Optimize Package Size: Smaller function package sizes lead to faster deployment and cold start times.
- Use Content Delivery Networks (CDNs): CDNs cache static assets closer to users, reducing the time it takes for users to receive these assets. This improves the overall user experience and reduces the load on serverless functions.
Handling Timeouts and Function Failures
Serverless functions, by their nature, are subject to execution time limits. These limits necessitate robust strategies for managing timeouts and failures to ensure application resilience and prevent cascading issues. Effective handling of these scenarios is crucial for maintaining application availability and data integrity within a serverless architecture.
Function Execution Time Exceeding Limits
When a serverless function surpasses its designated execution time limit, the platform abruptly terminates the function’s execution. This termination prevents the function from consuming excessive resources and potentially impacting other functions or services within the platform.
Strategies for Timeout Handling
Implementing proactive timeout handling mechanisms is paramount to building fault-tolerant serverless applications. These strategies help mitigate the impact of function timeouts and maintain operational stability.
- Retry Mechanisms: Implementing retry logic allows the function to be re-executed in the event of a timeout. This is particularly useful for transient errors or temporary service unavailability. However, it’s crucial to incorporate exponential backoff strategies to avoid overwhelming the underlying service if the issue persists. For instance, a function could initially retry after a few seconds, then progressively increase the delay between retries (e.g., 2 seconds, 4 seconds, 8 seconds).
- Error Handling: Comprehensive error handling is essential. Functions should be designed to catch exceptions and log relevant information before a timeout occurs. This logging provides crucial diagnostic data for troubleshooting and identifying the root cause of the timeout. Implement custom error handling that captures specific error codes, such as HTTP status codes or database connection errors, and respond appropriately.
- Circuit Breakers: Circuit breakers can be implemented to prevent repeated function calls to a failing service. If a function consistently times out or fails, the circuit breaker “opens,” preventing further calls for a predetermined period. This prevents cascading failures and gives the underlying service time to recover.
- Idempotency: Designing functions to be idempotent is crucial, especially when retries are employed. An idempotent function can be executed multiple times without unintended side effects. This is often achieved by implementing mechanisms like unique request identifiers or using transaction management within a database.
- Asynchronous Operations: For long-running tasks, consider offloading them to asynchronous processes, such as message queues (e.g., Amazon SQS, Azure Service Bus) or event-driven architectures. This allows the initial function to return quickly, while the long-running task continues in the background.
Alerting and Logging Function Failures
Robust monitoring and alerting are critical for detecting and responding to function failures. Detailed logging provides essential information for debugging and improving application performance.
- Centralized Logging: Implement a centralized logging system (e.g., AWS CloudWatch Logs, Azure Monitor, Google Cloud Logging) to aggregate logs from all functions. This provides a single pane of glass for monitoring and analyzing function behavior.
- Detailed Logging: Log critical information, including function invocation details (e.g., function name, request ID, start time, end time), error messages, stack traces, and relevant context data.
- Alerting on Failures: Set up alerts based on specific error conditions or timeout thresholds. These alerts should notify the appropriate teams or individuals immediately when a failure occurs.
- Monitoring Execution Metrics: Monitor key metrics, such as function execution time, error rates, and the number of invocations. This provides valuable insights into function performance and helps identify potential issues. For example, monitoring the average execution time of a function can help detect performance degradation before timeouts become a major problem.
- Tracing: Implement distributed tracing (e.g., AWS X-Ray, Azure Application Insights, Google Cloud Trace) to trace requests across multiple functions and services. This helps identify bottlenecks and pinpoint the source of errors in complex serverless applications.
Advanced Techniques

Serverless execution time limits necessitate employing advanced architectural and processing strategies to handle tasks exceeding these constraints. These techniques focus on decoupling long-running operations from the immediate function execution, ensuring responsiveness and scalability. Asynchronous processing and event-driven architectures are critical tools in achieving this.
Asynchronous Processing to Bypass Execution Time Limitations
Asynchronous processing enables serverless functions to initiate tasks without waiting for their completion. This approach effectively bypasses the execution time limits imposed by serverless platforms by offloading long-running operations to other services or processes. The initiating function quickly returns a response to the client, while the background task continues execution independently.
- Function Invocation and Task Offloading: A function receives a request, validates it, and then invokes a separate service (e.g., a queue, a message broker, or another function) to handle the long-running task. The initiating function returns a success or acknowledgement message to the client.
- Queueing Systems: Queues like Amazon SQS, Azure Queue Storage, or Google Cloud Pub/Sub act as intermediaries. The initial function places a message containing the task details into the queue. A separate worker function or service then consumes the message, processes the task, and may update the state or store results.
- Benefits of Asynchronous Processing: This strategy provides improved responsiveness to users, enhances scalability, and allows for efficient resource utilization. It separates the user-facing component from potentially time-consuming processes, leading to a better user experience.
Event-Driven Architectures for Handling Long-Running Tasks
Event-driven architectures are well-suited for managing long-running operations in a serverless environment. These architectures use events as the primary mechanism for communication and coordination between services. Events trigger functions to perform specific actions, allowing for complex workflows to be broken down into smaller, manageable units.
- Event Sources: Events can originate from various sources, including user actions, scheduled triggers, changes in data stores, or messages from other services.
- Event Bus or Broker: An event bus (e.g., AWS EventBridge, Azure Event Grid, or Google Cloud Pub/Sub) acts as a central hub, receiving events from event sources and routing them to the appropriate functions or services based on predefined rules.
- Function Interactions: Functions subscribe to specific events and are triggered when those events occur. They perform their designated tasks and can potentially emit new events, creating a chain of actions.
Illustration of an Event-Driven Architecture
Consider a scenario involving processing large image files uploaded by users. An event-driven architecture can effectively handle this.
- Event Source: A user uploads an image to an Amazon S3 bucket (this action triggers an event).
- Event Bus: S3 emits an “object created” event, which is then routed to an event bus like AWS EventBridge.
- Function 1 (Image Validation): This function subscribes to the “object created” event. It receives the event, validates the uploaded image (checking its format, size, and integrity), and publishes a “image_validated” event to the event bus.
- Function 2 (Image Resizing): This function subscribes to the “image_validated” event. Upon receiving the event, it retrieves the image from S3, resizes it to various dimensions, and saves the resized images back to S3, triggering a “image_resized” event.
- Function 3 (Metadata Update): This function subscribes to the “image_resized” event. It updates the metadata associated with the image in a database (e.g., adding information about the different sizes, thumbnails, etc.).
- Function 4 (Notification): This function can subscribe to the “image_resized” or “metadata_updated” events to notify the user about the image processing completion via email or other communication channels.
This event-driven flow allows each function to focus on a specific task, making the overall process modular, scalable, and resilient to failures. Each function executes within the execution time limits of the serverless platform, while the complete workflow handles the long-running image processing task. If one function fails, the system can retry the failed function without impacting the other functions in the process.
Cost Implications of Execution Time
Execution time is a fundamental driver of cost in serverless computing. Because serverless platforms typically charge based on the duration of function execution and the resources consumed during that time, understanding and managing execution time is crucial for controlling expenses. Inefficient code, unnecessary operations, and suboptimal configurations can significantly inflate costs, making optimization a critical aspect of serverless application development.
Cost Calculation Based on Execution Time and Resource Consumption
Serverless platforms employ a pay-per-use pricing model. This model directly links cost to the resources consumed by a function, including memory allocated, the number of invocations, and, most importantly, the execution time. Cost calculations are often based on a combination of factors, varying slightly between providers like AWS Lambda, Google Cloud Functions, and Azure Functions, but the core principle remains the same: longer execution times and higher resource consumption translate to higher costs.The basic formula for calculating the cost of a single function invocation can be expressed as:
Cost = (Execution Time (in seconds)
- Resource Consumption Rate (per second)) + (Number of Invocations
- Invocation Cost)
Where:* Execution Time: The duration for which the function runs, measured in seconds (or milliseconds, depending on the platform’s granularity).
Resource Consumption Rate
This is the rate at which the function consumes resources, such as memory. This rate is typically expressed as a cost per second, based on the memory allocated to the function. For example, AWS Lambda charges based on the memory allocated (e.g., 128MB, 256MB, etc.) and the execution time. Different memory allocations have different price tiers.
Invocation Cost
A small cost associated with each function invocation. This is a per-request fee.To illustrate, let’s consider an example using simplified values (these values are for illustrative purposes and do not reflect current pricing):Suppose a function runs for 1 second, has 256MB of memory allocated, and the resource consumption rate is $0.000002 per second for 256MB. The invocation cost is $0.0000002.The cost for this single invocation would be:Cost = (1 second – $0.000002/second) + ($0.0000002) = $0.0000022.This is the cost of a single invocation.
To calculate the overall cost, this calculation must be performed for each invocation and then summed. In reality, serverless providers use more granular units of measurement for execution time (e.g., milliseconds), and the pricing structures are more complex. Pricing models can vary between cloud providers and are subject to change. Therefore, it is essential to consult the specific pricing documentation of the chosen serverless platform.
Cost Implications of Different Optimization Strategies
Optimizing function execution time directly impacts cost. Several strategies can be employed, each with its own cost implications. The effectiveness of these strategies varies depending on the specific application and the chosen platform.
- Code Optimization: Reducing the execution time of the code directly lowers costs. This can involve optimizing algorithms, minimizing the use of computationally intensive operations, and reducing the size of dependencies. For example, replacing a linear search with a binary search in a large dataset can significantly reduce execution time and, consequently, cost. Similarly, optimizing database queries to retrieve only necessary data can reduce the time spent waiting for database responses.
- Resource Allocation: Selecting the appropriate memory allocation is crucial. Allocating too little memory can lead to increased execution time due to resource constraints, while allocating too much memory can increase costs unnecessarily. Monitoring function performance metrics, such as CPU utilization and memory usage, can help determine the optimal memory configuration. For example, if a function consistently uses less than 128MB of memory, reducing the allocated memory can lower costs.
However, reducing memory may also increase execution time if the function becomes CPU-bound.
- Caching: Implementing caching mechanisms can reduce the need to recompute results or retrieve data from external services. Caching frequently accessed data or results in memory or a dedicated caching service like Redis can dramatically reduce execution time and associated costs. For example, caching the results of an API call that is frequently accessed can prevent repeated calls to the API, thereby saving both time and cost.
- Asynchronous Operations: Utilizing asynchronous operations can improve efficiency. By offloading long-running tasks to background processes or queues, the main function can complete quickly, even if the background tasks take longer. This approach can reduce the execution time billed to the main function. For instance, sending an email confirmation after a user registers can be handled asynchronously, allowing the registration function to complete faster.
- Platform-Specific Optimizations: Each serverless platform offers specific optimization techniques. For instance, AWS Lambda functions can benefit from using provisioned concurrency to pre-warm function instances, reducing cold start times and the associated latency. Similarly, leveraging platform-specific features like Google Cloud Functions’ automatic scaling can help to efficiently manage resources and costs.
Future Trends and Considerations

The serverless computing landscape is in constant flux, with ongoing developments aimed at enhancing performance, flexibility, and cost-effectiveness. Execution time limits, a core constraint of serverless architectures, are a primary focus for evolution. Understanding the trajectory of these limits and the innovations shaping them is crucial for anticipating and adapting to the future of serverless applications.
Evolving Execution Time Limits
Serverless platforms are likely to witness a gradual increase in default execution time limits. This evolution will be driven by advancements in underlying infrastructure, including more efficient resource allocation and improved cold start times. Furthermore, the demand for supporting more complex and long-running tasks will fuel this trend.
- Increased Default Limits: Platforms will likely offer higher default execution time limits, catering to a broader range of use cases. This will enable serverless functions to handle more computationally intensive tasks, such as complex data processing or longer-running machine learning models. For example, a platform might increase its default execution time from the current 15 minutes to 30 or 60 minutes, depending on the service level.
- Configurable Limits: Greater flexibility in configuring execution time limits will become commonplace. Users might have the option to specify precise time windows for their functions, balancing cost optimization with performance requirements. This could involve dynamic adjustment based on the function’s activity, potentially leveraging machine learning to predict and adapt execution times.
- Tiered Execution Time Options: Different pricing tiers, each with varying execution time allowances, may emerge. This allows users to choose a plan that best suits their needs and budget. For instance, a premium tier could offer significantly extended execution times and advanced features, such as pre-warmed instances and optimized networking.
Addressing Current Limitations
Serverless platforms are actively working to mitigate the limitations imposed by execution time constraints. This includes optimizing cold start performance, enhancing resource allocation, and introducing mechanisms for long-running tasks.
- Cold Start Optimization: Significant investments are being made in reducing cold start latency, which is the time it takes for a serverless function to initialize and become ready to execute. This involves techniques such as container pre-warming, improved runtime environments, and optimized function packaging. For example, platforms are exploring methods to keep frequently used functions “warm” in anticipation of future requests, reducing latency.
- Improved Resource Allocation: Dynamic resource allocation is becoming more sophisticated, allowing functions to scale resources, such as memory and CPU, based on real-time demands. This ensures that functions have sufficient resources to complete tasks within the execution time limit. For example, platforms are moving towards more granular resource control, allowing users to specify exact resource requirements and optimize cost.
- Support for Long-Running Tasks: Several approaches are being explored to handle long-running operations. These include implementing workflow engines, stateful functions, and serverless orchestration services. Serverless workflow services allow users to break down long-running tasks into smaller, manageable steps. For example, AWS Step Functions enables the creation of state machines that manage complex processes, ensuring execution within manageable timeframes.
Potential Innovations in Serverless Computing
“The future of serverless will likely involve a convergence of several key innovations, fundamentally reshaping how applications are designed and deployed. This includes the integration of more powerful hardware resources, such as GPUs and specialized processors, to enable complex computations within serverless environments. Furthermore, the development of advanced scheduling algorithms and intelligent resource management systems will optimize function execution and minimize latency. Finally, the rise of edge computing and serverless deployments will bring compute closer to the user, enabling faster response times and improved user experiences.
Final Thoughts
In conclusion, serverless execution time limits are an inherent aspect of this computing model, influencing architectural decisions, cost considerations, and overall application performance. Effective strategies for optimization, graceful handling of timeouts, and the adoption of asynchronous processing techniques are crucial for maximizing the benefits of serverless while mitigating the inherent constraints. As the serverless landscape evolves, understanding and adapting to these time-based limitations will remain essential for developers seeking to build scalable, cost-effective, and resilient applications.
The future of serverless hinges on innovations that will likely offer greater flexibility and more sophisticated management of these crucial time-based parameters.
Essential Questionnaire
What happens if a serverless function exceeds its execution time limit?
The function is terminated, and any ongoing processes are abruptly stopped. Depending on the platform and configuration, this can result in a timeout error, and any uncommitted work may be lost.
How can I determine the execution time of my serverless function?
Serverless platforms provide monitoring tools that track function execution time. These tools often include metrics such as average execution time, maximum execution time, and the number of invocations. Logging and tracing can also be used to gather detailed timing information.
Are there any costs associated with exceeding the execution time limit?
While the function will be terminated, you will typically be charged for the resources consumed up to the point of termination. Therefore, exceeding the limit can increase costs, especially for functions that consume significant resources.
Can I increase the execution time limit on all serverless platforms?
No, each platform has its own maximum execution time. While you can often configure a higher limit than the default, there is always an upper bound. This upper bound can vary significantly between providers and is subject to change.
How do execution time limits affect the choice of programming language?
The choice of programming language can influence execution time. Some languages may execute faster than others, and the efficiency of the code can significantly impact performance. It is crucial to select a language suitable for the tasks and optimize the code accordingly.