What is a cloud migration business continuity plan? It’s a critical framework designed to maintain operational resilience during the complex process of transferring data and applications to a cloud environment. This plan proactively addresses potential disruptions, ensuring business operations remain functional, even amidst unforeseen challenges. Cloud migrations, while offering significant benefits, introduce inherent risks, making a robust business continuity plan not just beneficial, but essential for a successful transition.
This Artikel delves into the intricacies of cloud migration business continuity, dissecting the core concepts, potential pitfalls, and strategic approaches required to mitigate risks. From understanding the fundamental principles of business continuity to implementing robust data backup and disaster recovery strategies, we will explore the critical elements necessary for a seamless and secure cloud migration. This exploration includes the importance of planning, stakeholder communication, and the utilization of appropriate technologies and tools.
Understanding Cloud Migration Business Continuity
The transition of an organization’s IT infrastructure and data to a cloud environment, known as cloud migration, presents significant opportunities for enhanced scalability, cost efficiency, and agility. However, this migration also introduces new challenges, particularly concerning business continuity. A well-defined business continuity plan is crucial to mitigate risks and ensure operational resilience throughout the migration process and beyond. This plan provides a structured approach to maintain critical business functions in the face of disruptions, whether caused by technical failures, human error, or external events.
Core Concept of a Cloud Migration Business Continuity Plan
The core concept of a cloud migration business continuity plan revolves around proactively identifying potential threats and vulnerabilities within the cloud environment and establishing strategies to minimize their impact on business operations. This involves assessing the criticality of various business functions, analyzing potential failure scenarios, and implementing preventative measures and recovery procedures. The plan should be dynamic and adaptable, reflecting the evolving nature of the cloud environment and the organization’s business needs.
It moves beyond simply backing up data; it encompasses the entire ecosystem, including applications, infrastructure, and processes.
Definition of Business Continuity in the Context of Cloud Migrations
Business continuity in the context of cloud migrations is the capability of an organization to maintain or rapidly resume essential business functions following a disruption, leveraging the inherent resilience and flexibility of the cloud environment. It’s a proactive and holistic approach, encompassing the ability to restore data, applications, and infrastructure, as well as maintain business processes and communication channels. This definition emphasizes the speed and effectiveness of recovery, ensuring minimal downtime and impact on service delivery.
This includes considerations such as:
- Data Recovery: Implementing robust data backup and recovery strategies, including regular backups, geographically dispersed storage, and rapid recovery mechanisms. For example, utilizing cloud-based backup services that automatically replicate data across multiple availability zones.
- Application Resilience: Designing applications to be resilient to failures, utilizing techniques such as redundancy, load balancing, and auto-scaling. This ensures that applications can continue to function even if some components fail.
- Infrastructure Availability: Ensuring the availability of the underlying cloud infrastructure, including compute, storage, and network resources. This involves selecting cloud providers with high availability SLAs and implementing redundancy across different regions or availability zones.
- Process Automation: Automating key business processes to reduce the risk of human error and accelerate recovery times. This can include automated failover procedures, automated data synchronization, and automated system monitoring.
Primary Goals of Implementing a Business Continuity Plan During a Cloud Migration
The primary goals of implementing a business continuity plan during a cloud migration are centered around risk mitigation and operational stability. They aim to safeguard the organization’s ability to operate, even during disruptive events. Key objectives include:
- Minimize Downtime: Reducing the duration of any disruption to business operations. This is achieved through rapid detection, containment, and recovery strategies. Consider a scenario where a critical application experiences an outage. A well-defined business continuity plan, including automated failover mechanisms, could restore the application within minutes, minimizing the impact on users and revenue.
- Protect Data Integrity: Ensuring the availability and integrity of critical data throughout the migration and beyond. This involves implementing robust backup and recovery procedures, as well as data encryption and access controls. Data loss can lead to significant financial and reputational damage.
- Maintain Regulatory Compliance: Adhering to relevant regulatory requirements, such as data privacy regulations (e.g., GDPR, CCPA) and industry-specific standards. The business continuity plan should incorporate procedures to ensure compliance with these regulations, even during a disruption.
- Reduce Financial Impact: Minimizing the financial losses associated with disruptions, such as lost revenue, productivity, and increased operational costs. A well-designed plan can significantly reduce these costs by enabling faster recovery and minimizing downtime. For example, the costs associated with a data breach, including forensic investigations, legal fees, and customer notifications, can be substantial.
- Preserve Reputation: Protecting the organization’s reputation by ensuring continuous service delivery and maintaining customer trust. A proactive approach to business continuity demonstrates a commitment to customer satisfaction and business resilience.
Risks and Challenges in Cloud Migration
Cloud migration, while offering significant advantages, introduces inherent risks that can disrupt business operations if not meticulously planned and addressed. A robust business continuity plan must proactively identify and mitigate these potential threats to ensure minimal downtime and data loss during and after the migration process. Failing to account for these risks can lead to financial losses, reputational damage, and a decline in customer satisfaction.
Potential Disruptions During Cloud Migration
Several potential disruptions can occur during cloud migration, impacting business operations. These disruptions necessitate proactive planning and the implementation of robust mitigation strategies.
- Data Loss or Corruption: Data integrity is paramount. Migration processes can inadvertently lead to data loss or corruption due to various factors, including network interruptions, errors in data transfer tools, or incompatibilities between on-premises and cloud systems.
- Example: A financial institution migrating its customer database could experience significant reputational and financial damage if customer data is lost or corrupted during the migration.
- Downtime: Downtime is the period when business-critical systems are unavailable. Planned or unplanned downtime during migration can severely impact productivity, revenue generation, and customer service.
- Example: An e-commerce company experiencing downtime during a peak shopping season, such as Black Friday, could suffer substantial revenue losses and damage customer relationships.
- Security Breaches: Cloud migration can introduce new security vulnerabilities. Inadequate security configurations, misconfigurations, or vulnerabilities in the cloud provider’s infrastructure can lead to data breaches and unauthorized access to sensitive information.
- Example: A healthcare provider migrating patient records to the cloud must ensure robust security measures to comply with regulations like HIPAA and prevent data breaches that could compromise patient privacy.
- Performance Degradation: Performance issues can arise if the cloud infrastructure is not properly configured or scaled to handle the workload. This can result in slow application response times, reduced productivity, and a negative user experience.
- Example: A software-as-a-service (SaaS) provider experiencing performance degradation during peak usage times could lead to customer dissatisfaction and churn.
- Compliance Violations: Cloud migration must adhere to relevant industry regulations and compliance requirements. Failure to comply with these requirements can result in legal penalties, fines, and reputational damage.
- Example: A company operating in the European Union must ensure compliance with GDPR during cloud migration to protect the personal data of its customers.
Comparing Risks in Workload Migration
The risks associated with migrating different types of workloads vary based on their complexity, criticality, and dependencies. Understanding these differences is crucial for tailoring the business continuity plan.
- Databases: Database migrations often involve significant data volumes and complex dependencies. Risks include data loss, corruption, downtime during migration, and performance degradation if the cloud infrastructure is not properly configured.
- Example: Migrating a large, transactional database like an Oracle database requires careful planning, data validation, and testing to minimize downtime and data loss.
- Applications: Application migrations can be complex, especially for monolithic applications with numerous dependencies. Risks include compatibility issues, integration problems, and performance bottlenecks.
- Example: Migrating a legacy application built on an older technology stack might require significant code refactoring and testing to ensure compatibility with the cloud environment.
- Infrastructure: Infrastructure migrations involve moving virtual machines, servers, and network configurations to the cloud. Risks include misconfigurations, network outages, and compatibility issues with the cloud provider’s infrastructure.
- Example: Migrating a virtualized environment built on VMware requires careful planning and compatibility checks to ensure seamless operation in the cloud.
Challenges in Business Continuity During Cloud Migration
Ensuring business continuity during a cloud migration project presents several challenges that must be addressed proactively. These challenges often require a combination of technical expertise, strategic planning, and effective communication.
- Complexity: Cloud migration projects can be complex, involving multiple systems, data formats, and dependencies. Managing this complexity requires a well-defined migration strategy, a skilled project team, and robust project management processes.
- Example: A company migrating a complex IT infrastructure with numerous interconnected applications and databases requires a detailed migration plan, including a phased approach, data migration strategies, and testing procedures.
- Integration: Integrating on-premises systems with cloud-based systems can be challenging. This requires careful planning, testing, and the use of appropriate integration tools and technologies.
- Example: Integrating a legacy CRM system with a cloud-based marketing automation platform requires careful consideration of data mapping, data transformation, and API integration to ensure seamless data flow.
- Skills Gap: Cloud migration projects often require specialized skills in areas such as cloud architecture, security, and data migration. Organizations may need to invest in training, hire new talent, or partner with cloud experts to address skill gaps.
- Example: A company migrating to AWS might need to train its IT staff on AWS services, security best practices, and cloud management tools.
- Cost Management: Cloud migration projects can be expensive, especially if not properly planned and managed. Organizations must carefully estimate costs, monitor spending, and optimize resource utilization to avoid cost overruns.
- Example: Implementing cost optimization strategies, such as right-sizing instances, using reserved instances, and leveraging cloud-native services, can help organizations reduce cloud costs.
- Security and Compliance: Ensuring security and compliance in the cloud requires a robust security posture, including implementing appropriate security controls, adhering to industry regulations, and conducting regular security audits.
- Example: A financial institution migrating to the cloud must implement strong security controls, such as encryption, multi-factor authentication, and intrusion detection systems, to protect sensitive data and comply with regulatory requirements.
Planning and Preparation
Planning and preparation are critical phases in developing a robust cloud migration business continuity plan. A well-defined plan minimizes downtime, data loss, and reputational damage during the transition to the cloud. This section Artikels the essential steps, impact assessment frameworks, and pre-migration checklists necessary for ensuring business continuity.
Essential Steps in Planning a Cloud Migration Business Continuity Plan
The planning phase encompasses several critical steps to ensure a successful cloud migration and maintain business operations. These steps should be performed sequentially and iteratively, with constant review and refinement.
- Define Objectives and Scope: Clearly articulate the goals of the cloud migration and identify the specific applications, data, and services to be migrated. This definition sets the boundaries for the business continuity plan.
- Assess Current State: Conduct a thorough assessment of the existing IT infrastructure, including hardware, software, network configurations, and dependencies. This assessment informs the migration strategy and helps identify potential vulnerabilities.
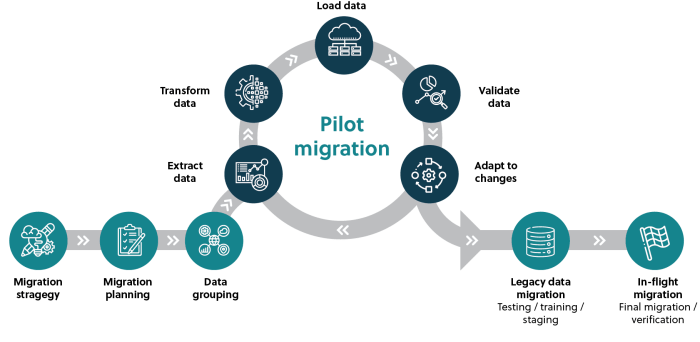
- Develop a Migration Strategy: Choose the appropriate migration strategy (e.g., rehosting, replatforming, refactoring, repurchase, retire). The chosen strategy will significantly impact the complexity and duration of the migration process.
- Identify and Prioritize Critical Business Functions: Determine which business functions are most crucial for operational continuity. Prioritize the migration of these functions to minimize the impact of potential disruptions.
- Develop Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs): Establish specific RTOs and RPOs for each critical business function.
RTO: The maximum acceptable time a business function can be unavailable after a disruption. RPO: The maximum acceptable data loss that can occur during a disruption.
These objectives will guide the design of the business continuity plan.
- Design a Business Continuity Plan: Develop a comprehensive plan that addresses potential disruptions, including data loss, application outages, and network failures. The plan should include procedures for data backup and recovery, failover mechanisms, and communication protocols.
- Select Cloud Providers and Services: Choose cloud providers and services that meet the business’s requirements for performance, security, and compliance. Evaluate the providers’ business continuity offerings and service level agreements (SLAs).
- Test and Validate the Plan: Regularly test the business continuity plan through simulations and exercises to ensure its effectiveness. Document the results and make necessary adjustments to the plan.
- Document the Plan: Create a detailed documentation of the business continuity plan, including procedures, roles and responsibilities, contact information, and recovery steps.
- Training and Communication: Provide training to relevant personnel on the business continuity plan and communication protocols. Regularly communicate updates and changes to all stakeholders.
Framework for Assessing the Impact of Potential Disruptions During the Migration Process
Assessing the impact of potential disruptions is crucial for proactively mitigating risks and ensuring business continuity. A structured framework provides a systematic approach to evaluating potential issues and their consequences.
- Identify Potential Disruptions: Brainstorm and identify potential disruptions that could occur during the cloud migration process. These could include data loss, application outages, network failures, security breaches, and vendor-related issues.
- Analyze the Impact: For each identified disruption, analyze its potential impact on critical business functions, including financial loss, reputational damage, legal and regulatory consequences, and operational disruption.
- Quantify the Impact: Where possible, quantify the impact of each disruption. This may involve estimating financial losses, the duration of downtime, and the number of affected customers or users.
- Prioritize Risks: Prioritize the identified risks based on their potential impact and likelihood of occurrence. Focus on mitigating the highest-priority risks first.
- Develop Mitigation Strategies: Develop mitigation strategies for each identified risk. These strategies may include data backup and recovery procedures, failover mechanisms, redundancy, and security controls.
- Implement Mitigation Strategies: Implement the developed mitigation strategies before and during the migration process.
- Monitor and Review: Continuously monitor the effectiveness of the mitigation strategies and review the risk assessment regularly. Adjust the plan as needed.
Checklist of Pre-Migration Activities Necessary for Business Continuity
A comprehensive checklist of pre-migration activities is essential for preparing for a smooth transition to the cloud and ensuring business continuity. These activities should be completed before initiating the actual migration process.
- Data Backup and Recovery: Implement a robust data backup and recovery strategy.
- Perform a full backup of all on-premises data.
- Verify the integrity of the backups.
- Test the data recovery process.
- Application Assessment and Remediation: Assess the compatibility of applications with the cloud environment.
- Identify any application dependencies.
- Address any compatibility issues.
- Update or refactor applications as needed.
- Network Configuration: Configure the network infrastructure to support the cloud migration.
- Establish network connectivity between on-premises and cloud environments.
- Configure firewalls and security groups.
- Test network performance and latency.
- Security Assessment and Hardening: Conduct a security assessment to identify vulnerabilities.
- Implement security controls to protect data and applications.
- Configure access controls and identity management.
- Establish security monitoring and incident response procedures.
- Vendor Selection and Management: Select cloud providers and services that meet the business’s requirements.
- Review service level agreements (SLAs).
- Establish vendor management procedures.
- Ensure compliance with regulatory requirements.
- Documentation and Training: Document the cloud migration plan and business continuity procedures.
- Provide training to relevant personnel on the new environment and procedures.
- Establish communication protocols for incident management.
- Testing and Validation: Test the cloud migration plan and business continuity procedures.
- Conduct simulations and exercises to validate the plan.
- Document the results and make necessary adjustments.
Data Backup and Recovery Strategies
Data backup and recovery strategies are crucial components of a cloud migration business continuity plan. They ensure the availability and integrity of data in the event of failures, disasters, or other disruptions. Implementing robust backup and recovery procedures minimizes downtime, data loss, and financial impact. This section details various strategies and considerations for effective data protection in cloud environments.
Data Backup Strategies for Cloud Environments
Cloud environments offer a variety of backup strategies, each with its strengths and weaknesses. The choice of strategy depends on factors like data volume, criticality, recovery time objectives (RTOs), and recovery point objectives (RPOs). These strategies are essential for creating a resilient and reliable cloud infrastructure.
- Snapshot-Based Backups: These backups capture the state of data at a specific point in time. They are typically fast and efficient for frequently changing data. Snapshots create a copy of the data volume’s state, allowing for quick restoration to a previous point. This method is often used for block storage volumes. For example, Amazon EBS snapshots and Azure Disk snapshots are common implementations.
The speed of snapshot creation and restoration makes them suitable for achieving low RTOs.
- Full Backups: Full backups involve copying all data to a backup location. While providing a complete data copy, they are time-consuming and resource-intensive. Full backups are often used as a baseline, with subsequent incremental or differential backups to reduce backup times. Full backups are fundamental for comprehensive data recovery but can significantly impact network bandwidth and storage costs.
- Incremental Backups: Incremental backups only copy data that has changed since the last backup (full or incremental). This method significantly reduces backup time and storage space requirements compared to full backups. However, restoring from incremental backups requires restoring the full backup and all subsequent incremental backups, increasing recovery time. The efficiency of incremental backups depends on the frequency of data changes and the time elapsed since the last full backup.
- Differential Backups: Differential backups copy data that has changed since the last full backup. They are faster than full backups but slower than incremental backups. Restoring from a differential backup requires restoring the full backup and the latest differential backup. Differential backups offer a balance between backup time and recovery time.
- Object Storage-Based Backups: Cloud object storage, like Amazon S3 or Azure Blob Storage, is often used for backups due to its scalability, durability, and cost-effectiveness. Data is stored as objects, and backups can be performed by copying objects to a different storage location or region. Object storage provides high data durability and availability, making it suitable for long-term data retention and disaster recovery scenarios.
The ability to store data in multiple geographic locations enhances data protection against regional outages.
- Database-Specific Backups: Database systems require specialized backup strategies to ensure data consistency and integrity. This may involve using database-specific backup tools, such as those provided by AWS RDS or Azure SQL Database. These tools typically perform transaction log backups, point-in-time recovery, and other features tailored to the database system. Database backups are crucial for maintaining data consistency and minimizing data loss in the event of a database failure.
Recovery Point Objective (RPO) and Recovery Time Objective (RTO) Options
Recovery Point Objective (RPO) and Recovery Time Objective (RTO) are critical metrics in business continuity planning. RPO defines the maximum acceptable data loss in a disaster scenario, while RTO defines the maximum acceptable downtime. Different backup strategies and recovery options offer varying RPO and RTO levels. The selection of appropriate RPO and RTO values depends on the business impact of data loss and downtime.
- Low RPO/Low RTO: This scenario requires the most aggressive backup and recovery strategies, such as real-time replication or continuous data protection (CDP). These methods aim to minimize data loss and downtime. For example, mission-critical applications often require an RPO of seconds or minutes and an RTO of minutes.
- Moderate RPO/Moderate RTO: This scenario typically involves frequent backups and automated recovery processes. The RPO might be a few hours, and the RTO might be a few hours or a few days. This level is suitable for applications where some data loss and downtime are acceptable. Daily or hourly backups, along with automated recovery procedures, are common.
- High RPO/High RTO: This scenario involves less frequent backups and manual recovery processes. The RPO might be a day or more, and the RTO might be days. This level is appropriate for less critical applications where data loss and downtime have a lower business impact. Weekly backups and manual recovery processes are typical.
Procedures for Testing Data Recovery Plans
Testing data recovery plans is essential to validate their effectiveness and ensure that recovery procedures function as intended. Regular testing identifies potential issues and allows for improvements to the plan. Testing should be performed at regular intervals and after any significant changes to the cloud environment or backup procedures.
- Test Types: Different types of tests can be used to validate data recovery plans.
- Failover Testing: Simulates a disaster scenario by switching to a backup environment. This test verifies the ability to restore services and data in a timely manner.
- Data Restoration Testing: Involves restoring data from backups to a test environment. This test validates the integrity of the backups and the effectiveness of the restoration procedures.
- Tabletop Exercises: Involves a discussion of the recovery plan and procedures without actually performing a restoration. This test helps to identify gaps in the plan and improve communication.
- Test Frequency: The frequency of testing depends on the criticality of the data and the rate of change in the cloud environment. Frequent testing is recommended for critical applications with stringent RPOs and RTOs. Testing should be performed at least annually, and preferably more frequently, such as quarterly or semi-annually.
- Test Documentation: Thorough documentation of test results is essential. This includes documenting the test procedures, the results, any issues encountered, and the actions taken to resolve those issues. Test results should be reviewed and analyzed to identify areas for improvement.
- Continuous Improvement: Data recovery plans should be continuously improved based on the results of testing and changes in the cloud environment. This includes updating the plan, refining the procedures, and improving the tools and technologies used for backup and recovery. Feedback from testing should be used to improve the plan’s effectiveness.
Disaster Recovery in the Cloud
Implementing robust disaster recovery (DR) strategies is a critical component of a successful cloud migration business continuity plan. The inherent elasticity and flexibility of cloud environments offer significant advantages in DR, enabling organizations to minimize downtime and data loss in the event of a disruptive incident. This section explores the implementation of disaster recovery solutions within the cloud, examining various DR models and best practices for configuring failover mechanisms.
Implementing Disaster Recovery Solutions
Cloud-based disaster recovery involves replicating data and applications to a secondary cloud region or availability zone. This ensures business operations can be restored quickly in case of a primary region outage or disaster. The implementation strategy depends on the specific business requirements, Recovery Time Objective (RTO), and Recovery Point Objective (RPO).
- Data Replication: This is the cornerstone of cloud-based DR. Data can be replicated using various methods, including:
- Asynchronous Replication: Data is replicated with a delay. This method is cost-effective but may result in some data loss if a disaster occurs.
- Synchronous Replication: Data is replicated in real-time, ensuring zero data loss. This approach is more expensive and requires a high-bandwidth connection.
- Snapshot-based Replication: Periodic snapshots of data are taken and replicated. This provides a balance between cost and data loss potential.
- Application Replication: Applications must also be replicated or designed to be easily deployed in a secondary region. This involves:
- Automated Deployment: Using Infrastructure as Code (IaC) tools like Terraform or CloudFormation to automate the deployment of applications in the DR region.
- Application-Specific Replication: Employing database replication features (e.g., PostgreSQL streaming replication, MySQL replication) to keep application data synchronized.
- Failover and Failback: The process of switching from the primary region to the DR region (failover) and, eventually, returning to the primary region (failback) must be carefully planned and tested. This includes:
- Automated Failover: Utilizing cloud-native services or third-party tools to automatically detect failures and initiate the failover process.
- Health Checks: Implementing health checks to monitor the status of applications and infrastructure components in both regions.
- DNS Configuration: Configuring DNS records to point to the DR region’s resources during failover.
- Testing and Validation: Regular testing is crucial to ensure the DR plan functions as expected. This involves:
- Failover Drills: Simulating a disaster scenario to test the failover process and identify potential issues.
- Recovery Testing: Verifying that data and applications can be successfully restored in the DR region.
Disaster Recovery Models
Various DR models can be employed in the cloud, each offering different levels of protection and cost implications. The choice of model depends on the organization’s RTO and RPO requirements.
- Active-Passive: In this model, the primary region is active, and the DR region is passive. The DR region is typically kept in a standby state, ready to be activated in case of a disaster. This model is cost-effective but may result in longer RTO.
- Example: An e-commerce company might use an active-passive model for its primary database. The database in the DR region is kept synchronized with the primary database using asynchronous replication.
In the event of a primary region outage, the DR database is activated, and DNS records are updated to point to the DR region.
- Example: An e-commerce company might use an active-passive model for its primary database. The database in the DR region is kept synchronized with the primary database using asynchronous replication.
- Active-Active: In this model, both the primary and DR regions are active and serving traffic. This model offers the lowest RTO, as traffic can be seamlessly routed to the DR region in case of a failure. However, it is the most expensive model.
- Example: A financial institution might use an active-active model for its online banking platform. Both regions are serving customer traffic, and a load balancer distributes traffic between them.
If one region fails, the load balancer automatically redirects traffic to the other region.
- Example: A financial institution might use an active-active model for its online banking platform. Both regions are serving customer traffic, and a load balancer distributes traffic between them.
- Pilot Light: This model keeps a minimal set of critical resources running in the DR region. When a disaster occurs, the remaining resources are provisioned and scaled up. This model provides a balance between cost and RTO.
- Example: A SaaS provider might keep a pilot light environment in the DR region, including core infrastructure components such as the database server and load balancers.
In case of a disaster, the application servers and other resources are scaled up from pre-configured images.
- Example: A SaaS provider might keep a pilot light environment in the DR region, including core infrastructure components such as the database server and load balancers.
- Cold Site: In this model, the DR region is a completely idle environment. Resources are provisioned and configured only when a disaster occurs. This model is the most cost-effective but has the longest RTO.
- Example: A small business might use a cold site for its file server. In the event of a disaster, the business would provision new servers and restore data from backups.
Configuring Failover Mechanisms
Configuring effective failover mechanisms is essential for ensuring business continuity in the cloud. This involves implementing automated processes to detect failures and seamlessly redirect traffic to the DR region.
- Health Monitoring: Implementing comprehensive health checks is critical. These checks should monitor the status of:
- Application Services: Monitoring the availability and responsiveness of application services using probes and synthetic transactions.
- Infrastructure Components: Monitoring the health of virtual machines, databases, and other infrastructure components.
- Network Connectivity: Monitoring network latency and bandwidth to ensure the DR region can handle traffic.
- Automated Failover Procedures: Automating the failover process minimizes downtime. This can be achieved using:
- Cloud-Native Services: Utilizing cloud-specific services such as AWS Route 53, Azure Traffic Manager, or Google Cloud DNS for automated DNS failover.
- Third-Party Tools: Employing third-party failover tools to automate the failover process and manage the DR environment.
- Custom Scripts: Developing custom scripts to automate failover procedures and manage the DR environment.
- DNS Configuration and Propagation: Properly configuring DNS settings is vital for directing traffic to the DR region during failover. This involves:
- Time-to-Live (TTL) Settings: Setting appropriate TTL values for DNS records to ensure that DNS changes propagate quickly.
- Health Checks and DNS Failover: Integrating health checks with DNS services to automatically update DNS records and redirect traffic to the DR region when a failure is detected.
- Testing and Validation: Regularly testing the failover process is critical to ensure its effectiveness. This includes:
- Failover Drills: Simulating disaster scenarios to test the failover process and identify potential issues.
- Failback Testing: Testing the process of returning to the primary region after the DR environment is restored.
- Load Balancing and Traffic Management: Employing load balancing solutions ensures traffic is distributed across available resources in both the primary and DR regions.
- Global Load Balancers: Utilizing global load balancers to direct traffic to the closest or most available region.
- Regional Load Balancers: Using regional load balancers to distribute traffic within a specific region.
Communication and Stakeholder Management
Effective communication and proactive stakeholder management are critical to the success of any cloud migration project, particularly within the context of business continuity. A well-defined communication strategy mitigates risks, manages expectations, and ensures all parties are informed and aligned throughout the migration process. This approach minimizes disruptions and promotes a smoother transition, safeguarding business operations.
Importance of Effective Communication During Cloud Migration
Effective communication is a cornerstone of a successful cloud migration strategy, serving multiple vital functions. It facilitates informed decision-making, minimizes misunderstandings, and ensures all stakeholders are aware of progress, potential issues, and mitigation strategies.
- Transparency and Trust: Open communication fosters transparency, building trust among stakeholders. Regularly sharing project updates, challenges, and solutions demonstrates a commitment to keeping everyone informed.
- Risk Mitigation: Proactive communication allows for the early identification and mitigation of potential risks. By keeping stakeholders informed of potential issues, such as data transfer delays or compatibility problems, teams can collaboratively develop and implement solutions.
- Expectation Management: Clear and consistent communication helps manage expectations regarding timelines, costs, and potential disruptions. Setting realistic expectations from the outset prevents dissatisfaction and ensures stakeholders understand the scope and complexities of the migration.
- Stakeholder Alignment: A well-defined communication plan ensures all stakeholders, from technical teams to executive leadership, are aligned on project goals, progress, and any required actions. This alignment is crucial for ensuring everyone works toward a common objective.
- Incident Response: In the event of an incident, such as a service outage or data loss, a robust communication plan enables rapid and effective response. Clear communication protocols ensure that the right information reaches the right people quickly, minimizing the impact on business operations.
Design of a Communication Plan
A comprehensive communication plan Artikels the strategies and tactics for keeping stakeholders informed during a cloud migration. This plan should define the target audience, communication frequency, communication channels, and escalation procedures. The goal is to ensure that all stakeholders receive the information they need, when they need it, in a format they can easily understand.
- Define Stakeholders: Identify all stakeholders involved in the cloud migration, including IT staff, business users, executive leadership, vendors, and regulatory bodies. Understanding each stakeholder group’s needs and concerns is crucial for tailoring communication effectively.
- Establish Communication Channels: Select appropriate communication channels based on the audience and the type of information being conveyed. Examples include email, project management software, regular meetings, newsletters, and status reports. Consider using multiple channels to ensure redundancy and reach all stakeholders.
- Determine Communication Frequency: Establish a schedule for communication, varying the frequency based on the project phase and the importance of the information. During critical phases, such as data migration, more frequent updates may be necessary. Regular, scheduled communications, such as weekly status reports, are essential.
- Develop Messaging and Content: Create clear, concise, and easily understandable messaging for each stakeholder group. The content should include project progress, milestones achieved, potential risks and mitigation plans, and any required actions from stakeholders. Tailor the messaging to the specific needs and concerns of each group.
- Implement Escalation Procedures: Define a clear escalation path for reporting and resolving issues. This ensures that critical problems are addressed promptly and that the right people are notified when necessary. Document the escalation process and communicate it to all stakeholders.
- Monitor and Evaluate: Continuously monitor the effectiveness of the communication plan and make adjustments as needed. Gather feedback from stakeholders to identify areas for improvement and ensure that the plan remains relevant and effective throughout the migration process.
Roles and Responsibilities of Key Stakeholders
A well-defined business continuity plan clarifies the roles and responsibilities of key stakeholders during a cloud migration. This table Artikels the responsibilities of each role in ensuring business continuity. This structure facilitates efficient coordination and ensures accountability throughout the migration process.
| Role | Responsibilities | Communication Requirements | Decision-Making Authority |
|---|---|---|---|
| Project Manager | Oversees the entire migration process, ensures tasks are completed on time and within budget, manages risks, and coordinates communication. | Weekly status reports, regular meetings with stakeholders, incident reports, and escalation of critical issues. | Overall project direction, resource allocation, and issue resolution. |
| IT Team | Responsible for the technical aspects of the migration, including data transfer, system configuration, and security implementation. | Daily updates on technical progress, incident reports, and communication with vendors. | Technical decisions, system configurations, and troubleshooting. |
| Business Stakeholders | Provide business requirements, validate the migrated systems, and ensure that the migration meets business needs. | Regular project updates, notification of system outages, and requests for feedback. | Approval of system changes and validation of business processes. |
| Executive Leadership | Provides strategic direction, approves budgets, and oversees the overall project progress. | Monthly progress reports, escalation of critical issues, and updates on project risks. | Strategic decisions, budget approvals, and risk management. |
Testing and Validation
Testing and validation are critical components of a cloud migration business continuity plan (BCP). They ensure the plan functions as intended, providing confidence in the organization’s ability to recover from disruptions. Rigorous testing identifies weaknesses, allowing for proactive remediation and optimization of recovery processes. Validation confirms that the plan meets defined recovery objectives and aligns with business requirements.
Procedures for Testing the Business Continuity Plan
A structured approach to testing the BCP is essential. This involves defining test objectives, selecting appropriate test types, executing tests, and documenting results. Regularly scheduled testing, coupled with periodic plan reviews, is crucial for maintaining BCP effectiveness.
- Test Objectives: Establish clear, measurable objectives for each test. These should align with the Recovery Time Objective (RTO) and Recovery Point Objective (RPO) defined in the BCP. Objectives might include verifying the ability to restore critical applications within a specified timeframe or confirming data integrity after a failover.
- Test Types: Employ various test types to assess different aspects of the BCP. Common test types include:
- Tabletop Exercises: These are discussions involving key personnel to simulate a disaster scenario and assess the plan’s effectiveness. They help identify gaps in understanding and communication.
- Walkthrough Tests: These involve reviewing the BCP step-by-step with the relevant teams, confirming the accuracy and completeness of the procedures.
- Failover Tests: These tests simulate a failure and the subsequent activation of the cloud-based disaster recovery (DR) environment. They verify the functionality of failover mechanisms and recovery processes.
- Full System Tests: These involve a complete simulation of a disaster, including the recovery of all critical systems and data in the DR environment.
- Test Execution: Test execution should follow a predefined schedule, with clear roles and responsibilities. Document all test activities, including the start and end times, the individuals involved, and any observed issues.
- Documentation and Reporting: Comprehensive documentation of test results is essential. This should include a detailed report outlining any issues encountered, the steps taken to resolve them, and the overall effectiveness of the BCP. This documentation forms the basis for continuous improvement.
- Test Frequency: The frequency of testing should be based on the criticality of the systems, the rate of change in the IT environment, and regulatory requirements. At a minimum, the BCP should be tested annually, with more frequent testing for critical systems.
Steps Involved in Validating the Effectiveness of Recovery Processes
Validation ensures that the recovery processes meet the organization’s needs and comply with relevant regulations. This involves comparing test results against predefined criteria and making necessary adjustments to the BCP.
- Define Validation Criteria: Establish specific, measurable, achievable, relevant, and time-bound (SMART) criteria for validating the effectiveness of the recovery processes. These criteria should be based on the RTO and RPO for each critical application or system.
- Analyze Test Results: Analyze the results of all tests to determine whether the recovery processes met the predefined validation criteria. This involves reviewing the test reports and identifying any discrepancies or failures.
- Identify and Remediate Issues: Address any issues or deficiencies identified during testing. This may involve updating the BCP, modifying recovery procedures, or improving the underlying infrastructure.
- Document Remediation Actions: Document all remediation actions taken, including the date, the individuals involved, and the results of the actions. This provides a record of the continuous improvement process.
- Re-test and Validate: After implementing any remediation actions, re-test the affected processes to ensure that the issues have been resolved. This is crucial to validate that the changes have improved the BCP’s effectiveness.
- Regular Review and Updates: The BCP and its validation process should be reviewed and updated regularly to reflect changes in the IT environment, business requirements, and regulatory requirements. This includes periodic reviews of the RTO and RPO.
Test Case Example for a Specific Cloud Migration Scenario and the Expected Results
This example demonstrates a test case for a cloud migration scenario, specifically a migration of a customer relationship management (CRM) application to a cloud-based platform. The example highlights the test scenario, the expected results, and the validation steps.
Scenario: Migration of a CRM application (e.g., Salesforce) to a cloud environment (e.g., AWS, Azure, or Google Cloud Platform). The BCP includes a DR strategy that involves replicating the CRM data and application in a secondary cloud region. The RTO is set to 4 hours, and the RPO is set to 1 hour.
Test Case: A failover test is conducted to simulate a primary region outage. The test involves the following steps:
- Initiate a Simulated Outage: Simulate a failure of the primary region by shutting down the primary CRM application instances.
- Failover to the DR Region: Initiate the failover process, which involves activating the CRM application in the secondary cloud region. This might involve DNS changes, database synchronization, and application startup.
- Verify Application Availability: Verify that the CRM application is accessible and functional in the DR region. This includes checking user access, data integrity, and application performance.
- Monitor the Failover Process: Monitor the entire failover process, including the time taken to complete the failover and the data loss (if any).
- Document the Test Results: Document all test activities, including the start and end times, the individuals involved, any observed issues, and the overall time taken for the failover.
Expected Results:
- The CRM application should become available in the DR region within 4 hours (RTO).
- Data loss should be within the defined RPO of 1 hour.
- Users should be able to access the CRM application with minimal disruption.
- Application performance should be acceptable in the DR region.
- All data replicated to the DR environment should be consistent.
Validation Steps:
- Time to Recovery: Verify that the failover process completed within the 4-hour RTO.
- Data Loss: Verify that data loss did not exceed the 1-hour RPO. This can be done by comparing the data in the DR region with the data in the primary region before the simulated outage.
- Application Functionality: Verify that all CRM application functionalities are working correctly in the DR region.
- User Access: Verify that users can access the CRM application in the DR region using their existing credentials.
- Performance: Verify that the application performance is acceptable in the DR region.
- Documentation Review: Review the test documentation to ensure that all steps were followed and that the results were accurately recorded.
- Remediation: If any issues are identified, such as the failover taking longer than the RTO or data loss exceeding the RPO, the BCP should be updated to address the root cause.
Example Data Table: The following table demonstrates a sample data record for the test.
| Test Step | Description | Start Time | End Time | Duration | Status | Notes/Issues |
|---|---|---|---|---|---|---|
| Simulate Outage | Shutdown primary CRM instances. | 2024-10-27 08:00:00 | 2024-10-27 08:00:05 | 0:00:05 | Completed | N/A |
| Failover Initiation | Initiate failover process in DR region. | 2024-10-27 08:00:10 | 2024-10-27 08:00:15 | 0:00:05 | Completed | DNS changes initiated. |
| DR Region Activation | CRM application activated in DR region. | 2024-10-27 11:55:00 | 2024-10-27 11:59:00 | 3:59:00 | Completed | All systems online, user access tested. |
| Data Verification | Compare data between primary and DR regions. | 2024-10-27 12:00:00 | 2024-10-27 12:00:30 | 0:00:30 | Completed | Data loss < 1 hour, as expected. |
Monitoring and Maintenance

Continuous monitoring and proactive maintenance are critical components of a cloud migration business continuity plan (BCP). They ensure the ongoing health, performance, and security of migrated systems, enabling rapid detection and mitigation of potential issues that could disrupt business operations. Without robust monitoring and maintenance, the benefits of cloud migration, such as scalability and resilience, can be compromised.
Importance of Continuous Monitoring
Continuous monitoring provides real-time visibility into the performance and availability of cloud resources. This allows organizations to identify and address potential problems before they impact business operations. Monitoring also supports proactive maintenance, enabling organizations to optimize resource utilization, improve performance, and enhance security.
Examples of Monitoring Tools and Their Application
Various monitoring tools are available for cloud environments, each with its specific capabilities. The choice of tools depends on the cloud provider, the specific services being used, and the organization’s requirements.
- Cloud Provider Native Tools: Cloud providers like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) offer native monitoring tools. These tools are tightly integrated with the cloud services and provide comprehensive monitoring capabilities.
- AWS CloudWatch: CloudWatch provides monitoring for AWS resources and applications. It collects metrics, logs, and events, enabling users to visualize performance, set alarms, and automate responses to issues.
CloudWatch also integrates with other AWS services, such as Lambda and EC2, to provide detailed insights into resource utilization and application behavior. For example, an organization migrating its e-commerce platform to AWS could use CloudWatch to monitor the latency of API calls, the CPU utilization of EC2 instances, and the number of database connections.
- Azure Monitor: Azure Monitor is a comprehensive monitoring service for Azure resources and applications. It provides a unified view of performance, availability, and security. Azure Monitor collects data from various sources, including application telemetry, operating system logs, and Azure resource logs. It also offers features such as alerting, log analytics, and application performance monitoring. A retail company migrating its point-of-sale system to Azure could use Azure Monitor to track the performance of virtual machines, monitor network traffic, and analyze application logs for errors.
- Google Cloud Monitoring: Google Cloud Monitoring (formerly Stackdriver) provides monitoring, logging, and diagnostics for applications running on Google Cloud Platform. It collects metrics, logs, and traces, allowing users to gain insights into application performance and troubleshoot issues. Google Cloud Monitoring integrates with other GCP services, such as Kubernetes Engine and Cloud Functions, to provide comprehensive monitoring capabilities. A software-as-a-service (SaaS) provider migrating its platform to GCP could use Google Cloud Monitoring to monitor the latency of API requests, the resource utilization of Kubernetes pods, and the error rates of microservices.
- AWS CloudWatch: CloudWatch provides monitoring for AWS resources and applications. It collects metrics, logs, and events, enabling users to visualize performance, set alarms, and automate responses to issues.
- Third-Party Monitoring Tools: Several third-party monitoring tools offer advanced features and integrations with multiple cloud providers and on-premises infrastructure.
- Datadog: Datadog provides a unified monitoring and analytics platform for cloud-scale applications. It collects metrics, logs, and traces from various sources and provides real-time dashboards, alerting, and anomaly detection. Datadog supports integrations with a wide range of cloud providers, application frameworks, and infrastructure components.
- New Relic: New Relic is an application performance monitoring (APM) platform that provides real-time insights into application performance and user experience. It collects data from applications, servers, and networks, allowing users to identify and resolve performance bottlenecks. New Relic supports integrations with various cloud providers and application frameworks.
- Dynatrace: Dynatrace is an AI-powered monitoring platform that automatically discovers and monitors applications and infrastructure. It provides real-time insights into performance, user experience, and security. Dynatrace supports integrations with various cloud providers and application frameworks.
- Application Performance Monitoring (APM) Tools: APM tools are specifically designed to monitor the performance of applications. They provide detailed insights into application code, dependencies, and user interactions. APM tools can help identify performance bottlenecks, troubleshoot errors, and optimize application performance.
- Examples of APM tools: Include but are not limited to, AppDynamics, and SolarWinds.
Schedule for Regularly Reviewing and Updating the Business Continuity Plan
A regularly scheduled review and update process ensures that the BCP remains relevant and effective. This process should include a schedule, responsibilities, and specific activities.
- Frequency of Review: The BCP should be reviewed and updated at least annually, or more frequently if significant changes occur in the business environment, cloud infrastructure, or regulatory requirements.
- Responsibilities: Assign clear responsibilities for reviewing and updating the BCP. This should include individuals or teams responsible for:
- Overseeing the review process.
- Gathering information and data.
- Updating the plan documentation.
- Testing and validating the updated plan.
- Review Activities: The review process should include the following activities:
- Assessment of Current State: Evaluate the current state of the cloud environment, including the performance of migrated systems, security posture, and compliance with regulatory requirements.
- Identification of Changes: Identify any changes that have occurred since the last review, such as new applications, infrastructure changes, or updates to cloud services.
- Impact Analysis: Assess the impact of the identified changes on the BCP, including potential risks and vulnerabilities.
- Plan Updates: Update the BCP documentation to reflect the identified changes. This may include updating contact information, recovery procedures, and testing plans.
- Testing and Validation: Test and validate the updated BCP to ensure it remains effective. This should include simulating various disaster scenarios and verifying that recovery procedures function as expected.
- Documentation: Maintain clear and concise documentation of the review and update process, including:
- Review dates and participants.
- Changes made to the BCP.
- Testing results and validation findings.
- Any identified issues and their resolution.
Technologies and Tools

Cloud migration business continuity relies heavily on a suite of technologies and tools designed to facilitate data protection, rapid recovery, and operational resilience. The choice of these technologies significantly impacts the Recovery Time Objective (RTO) and Recovery Point Objective (RPO), critical metrics for assessing the effectiveness of a business continuity plan. Selection must consider factors such as the cloud provider, the nature of the data, and the organization’s risk tolerance.
Backup and Disaster Recovery Solutions
Selecting the appropriate backup and disaster recovery (DR) solution is crucial for minimizing downtime and data loss during cloud migration. Various solutions are available, each with distinct features and capabilities, often tailored to specific cloud environments or data types. A thorough comparison is necessary to determine the best fit for the organization’s requirements.
| Feature | Backup Solutions | Disaster Recovery Solutions |
|---|---|---|
| Primary Function | Data preservation and restoration from a point in time. | Business continuity and rapid failover to a secondary site. |
| Data Replication | Typically involves creating copies of data at scheduled intervals. | Often employs continuous or near-continuous replication of data to a standby environment. |
| Recovery Time Objective (RTO) | Can range from minutes to hours, depending on the restoration process. | Designed for significantly faster recovery, often within minutes or seconds. |
| Recovery Point Objective (RPO) | Determined by the backup frequency, potentially resulting in data loss up to the backup interval. | Offers lower RPO, minimizing data loss due to continuous replication. |
| Cost | Generally less expensive, as it focuses primarily on data storage and retrieval. | Often more costly, due to the need for a standby environment and continuous replication. |
| Complexity | Relatively straightforward to implement and manage. | Can be more complex, requiring orchestration and automation for failover and failback. |
Specific Tools for Cloud Migration Business Continuity
A comprehensive cloud migration business continuity plan leverages a range of specialized tools to ensure data protection, rapid recovery, and streamlined operations. These tools are categorized by their primary function to facilitate efficient planning and execution.
- Backup Tools: These tools focus on creating and managing data backups, providing a safety net against data loss.
- Veeam Backup & Replication: A popular solution providing backup, replication, and recovery for virtual, physical, and cloud-based workloads. It supports various cloud platforms and offers features such as instant VM recovery and SureBackup verification.
- AWS Backup: Amazon Web Services’ native backup service, offering centralized backup and recovery management for AWS services like EC2, RDS, and DynamoDB. It provides automated backups, retention management, and cross-region copy capabilities.
- Azure Backup: Microsoft Azure’s backup service, designed for backing up on-premises and cloud data. It integrates with Azure services and provides features like long-term retention, data encryption, and restore capabilities.
- Replication Tools: These tools are focused on replicating data to a secondary location, enabling rapid failover in case of a disaster.
- Zerto: Provides continuous data protection and disaster recovery for virtualized environments and cloud platforms. It offers features such as near-synchronous replication, automated failover, and failback capabilities.
- CloudEndure Disaster Recovery: A cloud-based disaster recovery solution that provides block-level replication to minimize downtime and data loss. It supports various cloud platforms and offers features like automated failover and failback testing.
- AWS Elastic Disaster Recovery (DRS): A service that minimizes downtime and data loss with fast, reliable recovery of on-premises and cloud-based applications using continuous block-level replication.
- Orchestration Tools: These tools automate the failover and failback processes, ensuring a streamlined and efficient recovery process.
- AWS CloudFormation: Enables the creation and management of infrastructure as code, facilitating the automation of failover and failback processes in AWS environments.
- Azure Resource Manager (ARM): Similar to CloudFormation, ARM allows for infrastructure as code deployment and management in Azure, supporting automated failover and failback scenarios.
- HashiCorp Terraform: An infrastructure-as-code tool that supports multiple cloud providers, enabling the automation of infrastructure provisioning and management across hybrid and multi-cloud environments, including orchestration of disaster recovery.
- Monitoring and Alerting Tools: These tools provide real-time visibility into the health and performance of the cloud environment, enabling proactive identification and resolution of issues.
- Datadog: A monitoring and analytics platform that provides real-time insights into the performance of cloud applications and infrastructure. It offers features such as automated alerting, custom dashboards, and integration with various cloud services.
- New Relic: An observability platform that provides comprehensive monitoring, analytics, and troubleshooting capabilities for cloud applications. It offers features such as application performance monitoring (APM), infrastructure monitoring, and real-time user monitoring (RUM).
- Prometheus and Grafana: Prometheus is a time-series database and monitoring system, while Grafana is a data visualization and dashboarding tool. They can be used together to monitor cloud environments and create custom dashboards for visualizing key metrics.
Ultimate Conclusion
In conclusion, a well-defined cloud migration business continuity plan is not merely a procedural checklist; it’s a strategic imperative for organizations embracing cloud technologies. By meticulously addressing potential risks, implementing robust recovery strategies, and fostering clear communication, businesses can ensure operational resilience throughout their cloud migration journey. This proactive approach minimizes downtime, protects critical data, and ultimately, safeguards business continuity, allowing organizations to fully leverage the benefits of the cloud without compromising their operational integrity.
FAQ Summary
What is the primary goal of a cloud migration business continuity plan?
The primary goal is to minimize downtime and data loss during a cloud migration, ensuring business operations continue with minimal disruption, even in the face of unexpected events.
How does a cloud migration business continuity plan differ from a standard business continuity plan?
While both aim for business resilience, a cloud migration plan specifically addresses the unique challenges and risks associated with moving to or operating within a cloud environment, such as data replication, cloud-specific disaster recovery models, and vendor dependencies.
What are the key components of a successful cloud migration business continuity plan?
Key components include thorough risk assessment, data backup and recovery strategies, disaster recovery planning, effective communication protocols, comprehensive testing and validation procedures, and continuous monitoring and maintenance.
How often should a cloud migration business continuity plan be reviewed and updated?
The plan should be reviewed and updated regularly, ideally at least annually or whenever significant changes occur in the IT infrastructure, cloud environment, or business operations.
What are the potential consequences of not having a cloud migration business continuity plan?
Without a plan, organizations face the risk of significant downtime, data loss, financial losses, reputational damage, and potential regulatory non-compliance during a cloud migration or in the event of a cloud-related disaster.