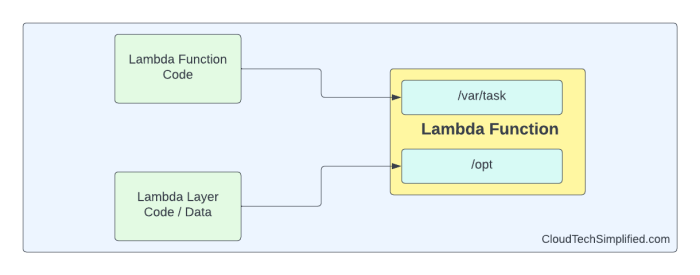
The evolution of data management has brought forth innovative architectures, and at the forefront stands the serverless data lake. This architecture reimagines how data is stored, processed, and analyzed by leveraging the scalability and cost-efficiency of serverless computing. It departs from traditional data warehouses by offering a flexible and agile environment capable of handling vast, varied datasets without the burden of managing underlying infrastructure.
This shift enables organizations to focus on deriving insights rather than the complexities of server administration.
A serverless data lake integrates several key components, including object storage for data persistence, serverless compute services for processing, and various query engines for analysis. This combination provides a powerful and efficient solution for handling the demands of modern data workloads. This framework empowers businesses to ingest data from diverse sources, transform it, and derive actionable insights with unprecedented speed and efficiency.
The benefits are significant, including reduced operational costs, enhanced scalability, and increased agility in responding to evolving business needs.
Introduction to Serverless Data Lake Architecture
Serverless data lake architecture represents a significant evolution in data management, offering a streamlined approach to storing, processing, and analyzing vast amounts of data. It leverages cloud-based services to provide on-demand resource allocation, eliminating the need for manual server provisioning and management. This architecture focuses on scalability, cost-efficiency, and ease of use, making it a compelling solution for modern data-driven organizations.
Defining a Data Lake and its Distinction from Traditional Data Warehouses
A data lake is a centralized repository designed to store structured, semi-structured, and unstructured data at any scale. Unlike traditional data warehouses, which typically enforce a rigid schema-on-write approach, data lakes employ a schema-on-read approach. This allows data to be ingested in its raw format, without requiring upfront transformation or modeling. This flexibility enables the storage of diverse data types, including logs, sensor data, social media feeds, and multimedia files, facilitating a broader range of analytical possibilities.
Data warehouses, on the other hand, are optimized for structured data and pre-defined queries, often involving extensive data transformation and modeling before loading. The key difference lies in the data’s structure at the point of ingestion and the intended use case.
Core Benefits of Adopting a Serverless Approach for Data Lakes
Adopting a serverless approach for data lakes offers several advantages, contributing to enhanced efficiency, reduced costs, and improved agility. These benefits stem from the underlying characteristics of serverless computing, including automated scaling, pay-per-use pricing, and reduced operational overhead.
- Scalability and Elasticity: Serverless data lakes automatically scale resources based on demand. This eliminates the need for manual capacity planning and ensures optimal performance during peak loads. For instance, during a marketing campaign, a serverless data lake can automatically scale up to handle increased data ingestion and query requests, then scale down when the campaign ends, minimizing costs. This dynamic scaling contrasts with traditional infrastructure, which often requires over-provisioning to handle peak loads, resulting in wasted resources during off-peak times.
- Cost Efficiency: Serverless data lakes utilize a pay-per-use pricing model, meaning users only pay for the compute and storage resources they consume. This contrasts with traditional infrastructure, where users often pay for provisioned resources, regardless of actual usage. The cost savings can be significant, especially for workloads with fluctuating demand. For example, a small business using a serverless data lake might only pay a few dollars per month for storage and compute, compared to hundreds or thousands of dollars per month for a traditional data warehouse.
- Reduced Operational Overhead: Serverless data lakes abstract away the complexities of infrastructure management, such as server provisioning, patching, and scaling. This frees up data engineering teams to focus on more strategic tasks, such as data modeling, analysis, and building data pipelines. The underlying infrastructure is managed by the cloud provider, ensuring high availability, security, and reliability. This reduces the operational burden and the need for specialized IT staff.
- Faster Time to Insights: Serverless data lakes enable rapid data ingestion, processing, and analysis. This accelerated time to insights is due to the ease of data ingestion and the ability to quickly spin up and down processing resources. With serverless architectures, data analysts can iterate faster on data exploration and modeling, leading to quicker decision-making.
- Simplified Data Pipeline Development: Serverless architectures simplify the development and deployment of data pipelines. Cloud providers offer a variety of serverless services for data ingestion, transformation, and orchestration. These services can be easily integrated to build end-to-end data pipelines without the need for extensive coding or infrastructure management.
Key Components of a Serverless Data Lake
A serverless data lake architecture leverages cloud-based services to provide a scalable, cost-effective, and manageable platform for storing, processing, and analyzing vast amounts of data. This architecture eliminates the need for managing underlying infrastructure, allowing data engineers and analysts to focus on data-driven insights. The core components work in concert to facilitate a streamlined data lifecycle, from ingestion to consumption.
Object Storage
Object storage serves as the foundational layer for a serverless data lake, providing a durable and scalable repository for all types of data. This component’s role is critical in the overall architecture.Object storage solutions, such as Amazon S3, Azure Blob Storage, and Google Cloud Storage, offer several key advantages:
- Scalability: Object storage can seamlessly scale to accommodate petabytes of data without requiring manual intervention. The underlying infrastructure automatically adjusts to meet the demands of data growth.
- Durability: Data is typically replicated across multiple availability zones or geographic regions, ensuring high data durability and availability, protecting against data loss due to hardware failures or other disruptions. For example, Amazon S3 offers 99.999999999% (11 nines) of durability for objects.
- Cost-Effectiveness: Object storage often employs a pay-as-you-go pricing model, allowing users to pay only for the storage capacity and data transfer they consume. This eliminates the need for upfront investments in hardware and reduces operational expenses.
- Accessibility: Data stored in object storage is accessible via standard APIs, enabling integration with various services and applications.
Object storage is typically the central repository for raw data, processed data, and analytical results. Data is often stored in formats like CSV, JSON, Parquet, and ORC, which are optimized for different processing and analytical workloads.
Serverless Compute Services
Serverless compute services are a critical component of a serverless data lake, providing the processing power required to transform, analyze, and query data without the need to manage servers. They enable efficient data processing.These services, including AWS Lambda, Azure Functions, and Google Cloud Functions, offer several benefits:
- Event-Driven Processing: Serverless functions can be triggered by events, such as new data arriving in object storage, scheduled jobs, or API requests. This enables automated data processing pipelines.
- Automatic Scaling: Serverless functions automatically scale to handle varying workloads, eliminating the need for manual capacity provisioning. This ensures optimal performance and responsiveness.
- Pay-per-Use Pricing: Users pay only for the actual compute time consumed by their functions, reducing costs and improving efficiency.
- Simplified Development and Deployment: Serverless functions are typically easy to develop, deploy, and manage, allowing developers to focus on business logic rather than infrastructure management.
Serverless compute services are used for various data processing tasks, including:
- Data Transformation: Transforming raw data into a usable format for analysis.
- Data Enrichment: Adding context and value to data by integrating with external services.
- Data Validation: Ensuring data quality by validating data against predefined rules.
- Data Aggregation: Performing aggregations and calculations on data to generate insights.
For instance, a Lambda function can be triggered by a new file uploaded to S3, transforming the data from CSV to Parquet format, and then storing the transformed data back into S3.
Data Ingestion Process
Data ingestion is a critical process in any data lake, and a serverless approach streamlines this process. This section explains the approach to data ingestion.A typical serverless data ingestion process involves the following steps:
- Data Source: Data originates from various sources, such as application logs, databases, IoT devices, or external APIs.
- Event Trigger: An event, such as a new file upload to object storage (e.g., S3), a message published to a message queue (e.g., SQS, Azure Event Hubs, Google Pub/Sub), or a scheduled event, triggers the data ingestion pipeline.
- Serverless Function Invocation: The event triggers a serverless function (e.g., Lambda, Azure Function, Google Cloud Function).
- Data Extraction and Transformation: The serverless function extracts data from the source, transforms it as needed (e.g., data cleansing, format conversion), and potentially enriches it.
- Data Loading: The transformed data is loaded into the object storage, often organized into a logical structure (e.g., date-based partitions, topic-based folders).
- Metadata Management: Metadata about the ingested data (e.g., file size, schema, timestamp) is captured and stored in a metadata catalog (e.g., AWS Glue Data Catalog, Azure Data Catalog, Google Cloud Data Catalog).
For example, consider a scenario where application logs are generated and stored in a directory. The ingestion process could work like this:
- New log files are written to an S3 bucket.
- An S3 event notification triggers a Lambda function.
- The Lambda function reads the log file, parses the data, and transforms it into a structured format (e.g., JSON).
- The Lambda function writes the transformed data to another location in S3, possibly partitioned by date.
- The Lambda function updates a metadata catalog to register the new data.
This approach automates the data ingestion process, scales automatically, and minimizes operational overhead.
Benefits
Serverless data lakes offer significant advantages over traditional data lake architectures, primarily in terms of cost efficiency and scalability. These benefits stem from the inherent characteristics of serverless computing, such as pay-per-use pricing and automatic resource scaling. This section will delve into the specifics of these advantages, providing a detailed analysis of cost savings and the ability to handle varying data volumes effectively.
Cost Efficiency
The cost-effectiveness of serverless data lakes is a major driver for their adoption. Traditional data lake infrastructure often involves significant upfront capital expenditure (CAPEX) for hardware, software licensing, and infrastructure management. Serverless architectures, on the other hand, shift the cost model to an operational expenditure (OPEX) model, where users pay only for the resources they consume. This pay-per-use approach, coupled with automatic scaling, leads to substantial cost savings, particularly for workloads with fluctuating demand.To illustrate the cost differences, consider the following comparison table:
| Feature | Traditional Data Lake | Serverless Data Lake | Cost Implications | Scalability |
|---|---|---|---|---|
| Infrastructure Provisioning | Requires upfront purchase and setup of hardware and software. | No upfront infrastructure; resources are provisioned on-demand by the cloud provider. | High initial CAPEX; ongoing costs for maintenance and upgrades. | Limited by pre-provisioned capacity; scaling often requires significant manual effort and downtime. |
| Compute Resources | Dedicated servers or virtual machines, often underutilized. | Pay-per-use compute resources, such as serverless functions or managed services. | Fixed costs regardless of usage; idle resources contribute to wasted expenditure. | Automatic scaling based on demand; resources are allocated only when needed. |
| Storage Costs | Storage solutions, often with fixed pricing tiers and capacity planning. | Object storage with pay-per-GB pricing. | Predictable but potentially over-provisioned storage, leading to wasted resources. | Scales automatically based on data volume; costs align with actual storage consumption. |
| Maintenance & Management | Requires dedicated IT staff for infrastructure management, patching, and upgrades. | Managed services provided by the cloud provider; minimal operational overhead. | High operational costs for staffing and maintenance. | No manual scaling or maintenance required; the cloud provider handles resource management. |
The table highlights that serverless data lakes eliminate the need for upfront infrastructure investments and reduce the ongoing costs associated with server management and maintenance. The pay-per-use model ensures that users only pay for the resources they consume, optimizing resource utilization and minimizing waste.
Scalability
Serverless data lakes are designed to automatically scale to handle varying data volumes and processing demands. This automatic scaling capability is a core advantage, allowing the data lake to adapt to fluctuations in data ingestion, query workloads, and analytical processing requirements. The cloud provider handles the underlying infrastructure management, ensuring that resources are allocated and de-allocated dynamically based on demand.The ability to scale automatically eliminates the need for manual capacity planning and resource provisioning.
For example, consider a retail company using a serverless data lake to analyze sales data. During peak sales periods, such as holiday seasons or promotional events, the data lake can automatically scale up to handle the increased data ingestion and query loads. Conversely, during slower periods, the data lake can scale down, reducing costs.The automatic scaling capabilities are enabled through various mechanisms, including:
- Serverless Compute Engines: Services like AWS Lambda, Azure Functions, and Google Cloud Functions automatically scale compute resources based on the number of incoming requests. This ensures that processing power is available when needed, without the need for manual intervention.
- Managed Storage Services: Object storage services, such as Amazon S3, Azure Blob Storage, and Google Cloud Storage, are designed to scale seamlessly to accommodate large data volumes. The underlying infrastructure automatically adjusts to handle the storage and retrieval of data, eliminating the need for capacity planning.
- Managed Data Processing Services: Services like AWS Glue, Azure Synapse Analytics, and Google BigQuery automatically scale processing resources based on the complexity and volume of data being processed. This ensures that data transformations, queries, and other processing tasks are completed efficiently, regardless of the data volume.
This automatic scaling capability is crucial for organizations dealing with unpredictable data volumes. It ensures that the data lake can handle spikes in demand without performance degradation or the need for manual intervention.
Data Ingestion and Processing
Data ingestion and processing are critical phases in a serverless data lake architecture, responsible for bringing data into the lake and preparing it for analysis. Efficient and reliable data pipelines are essential for the data lake’s success. This section explores various methods for data ingestion, serverless tools for transformation and processing, real-time data streaming, and data quality checks.
Different Data Ingestion Methods Suitable for a Serverless Data Lake
Data ingestion involves bringing data from various sources into the data lake. Serverless architectures provide flexibility in handling different ingestion methods. Several ingestion strategies cater to diverse data sources and formats.
- Batch Ingestion: Suitable for data that arrives in bulk at scheduled intervals.
- File-based ingestion: Data from files stored in various formats (CSV, JSON, Parquet) is ingested, typically using serverless functions triggered by file uploads to object storage (e.g., AWS S3, Azure Blob Storage, Google Cloud Storage).
- Database ingestion: Data from relational databases (e.g., MySQL, PostgreSQL) or NoSQL databases (e.g., MongoDB, Cassandra) is ingested. Tools like AWS Database Migration Service (DMS), Azure Data Factory’s copy activity, or Google Cloud Dataflow can be used to extract, transform, and load (ETL) data.
- Real-time Streaming Ingestion: Designed for continuous data ingestion as it arrives.
- Event-driven ingestion: Serverless functions triggered by events, such as messages from message queues (e.g., AWS SQS, Azure Service Bus, Google Cloud Pub/Sub), or changes in databases (using change data capture (CDC) mechanisms).
- Stream processing: Data streams are processed in real-time using serverless stream processing services (e.g., AWS Kinesis Data Streams, Azure Event Hubs, Google Cloud Pub/Sub) in conjunction with serverless functions or stream processing engines.
- API-based Ingestion: Enables data ingestion through APIs.
- API Gateway: Serverless APIs (e.g., AWS API Gateway, Azure API Management, Google Cloud API Gateway) receive data from external sources, which then triggers serverless functions for processing and storing data in the data lake.
Serverless Tools for Data Transformation and Processing
Data transformation and processing are crucial steps to prepare data for analysis. Serverless tools offer scalability and cost-efficiency for these tasks. Several tools are specifically designed for serverless data transformation and processing.
- AWS Glue: A fully managed ETL service that provides a visual interface for building ETL workflows.
- Data catalog: AWS Glue provides a data catalog to store metadata about data sources and targets, facilitating data discovery and management.
- ETL jobs: AWS Glue jobs can be defined using visual ETL builders or custom code (Python, Scala). These jobs can transform data by cleaning, filtering, aggregating, and enriching data.
- Scheduling and triggering: Jobs can be triggered based on schedules, events, or dependencies.
- Azure Data Factory: A cloud-based ETL service that provides data integration capabilities.
- Data pipelines: Azure Data Factory allows building data pipelines that orchestrate data movement and transformation.
- Connectors: It offers a wide range of connectors to integrate with various data sources and sinks.
- Activities: Activities such as copy, data flow, and custom activities enable data transformation and processing.
- Google Cloud Dataflow: A fully managed, serverless stream and batch data processing service.
- Unified batch and stream processing: Dataflow supports both batch and real-time processing with a unified programming model.
- Apache Beam: Dataflow uses the Apache Beam programming model, allowing developers to define data pipelines using Java or Python.
- Scalability and performance: Dataflow automatically scales resources based on data volume and processing requirements.
Procedures for Real-time Data Streaming and Processing Using Serverless Functions
Real-time data streaming and processing are vital for applications requiring immediate insights. Serverless functions play a key role in processing data streams. This approach allows for the creation of responsive and scalable data pipelines.
- Data ingestion: Data streams from sources (e.g., IoT devices, social media feeds) are ingested into a streaming service.
- Stream processing: Serverless stream processing services (e.g., AWS Kinesis Data Streams, Azure Event Hubs, Google Cloud Pub/Sub) ingest and buffer data streams.
- Serverless function invocation: Serverless functions (e.g., AWS Lambda, Azure Functions, Google Cloud Functions) are triggered by events in the stream, processing data in real-time.
- Data transformation and enrichment: Within the serverless functions, data can be transformed, enriched, and aggregated.
- Data storage: Processed data is stored in the data lake (e.g., object storage, data warehouses).
- Real-time analytics: The processed data is made available for real-time analytics dashboards and alerts.
How to Handle Data Quality Checks and Validation Within the Ingestion Pipeline
Data quality is critical for ensuring the reliability of insights derived from the data lake. Implementing data quality checks and validation steps within the ingestion pipeline is essential. The data quality process can involve several steps.
- Data profiling: Before ingestion, data profiling examines data characteristics (e.g., data types, value ranges, null values) to understand the data’s quality.
- Data validation: During ingestion, data validation rules are applied to check for data quality issues.
- Schema validation: Ensuring data conforms to the expected schema.
- Data type validation: Checking data types of the fields.
- Range validation: Validating values within a specific range.
- Completeness checks: Verifying the presence of required fields.
- Referential integrity: Ensuring that relationships between data are maintained.
- Data cleansing: Data cleansing processes correct data quality issues.
- Missing value imputation: Filling in missing values.
- Outlier detection and handling: Identifying and addressing outliers.
- Data standardization: Converting data to a consistent format.
- Error handling and alerting: When data quality issues are detected, appropriate error handling and alerting mechanisms are implemented.
- Logging: Logging data quality issues for auditing and analysis.
- Alerting: Sending notifications to stakeholders when data quality issues occur.
- Data quarantine: Isolating problematic data for investigation.
- Data quality monitoring: Continuous monitoring of data quality metrics ensures data quality over time.
Data Storage and Management
Efficient data storage and management are critical pillars of a successful serverless data lake architecture. The ability to store and access data cost-effectively, reliably, and in a scalable manner is essential for deriving insights and value from the data. This section delves into the core aspects of data storage and management within a serverless data lake, focusing on object storage, storage tiers, data partitioning, and lifecycle management.
Role of Object Storage in a Serverless Data Lake
Object storage serves as the fundamental storage layer in a serverless data lake. Its characteristics, such as scalability, durability, and cost-effectiveness, make it ideally suited for storing vast amounts of unstructured, semi-structured, and structured data. Unlike traditional file systems, object storage does not have a hierarchical structure, instead, data is stored as objects within buckets. Each object consists of the data itself, along with associated metadata.Object storage offers several advantages within a serverless data lake:
- Scalability: Object storage can seamlessly scale to accommodate petabytes of data, enabling the data lake to grow without performance degradation. This scalability is inherent in the architecture, where the storage system distributes data across multiple servers and automatically manages capacity.
- Durability: Object storage provides high data durability through mechanisms like data replication across multiple availability zones or regions. This redundancy ensures data availability even in the event of hardware failures or other disruptions. For example, Amazon S3, a widely used object storage service, guarantees 99.999999999% (11 nines) of durability for data.
- Cost-Effectiveness: Object storage offers competitive pricing models, often with pay-as-you-go options. These models enable organizations to pay only for the storage they consume, reducing capital expenditure and operational costs. This is particularly beneficial in serverless environments where resources are provisioned and de-provisioned dynamically.
- Accessibility: Data stored in object storage can be accessed via standard APIs (e.g., REST APIs), making it easy to integrate with various data processing and analysis tools. This accessibility enables a wide range of applications, from batch processing to real-time analytics.
- Decoupling: Object storage decouples storage from compute, allowing compute resources to scale independently of storage. This separation enhances flexibility and optimizes resource utilization. For example, compute resources can be scaled up during peak processing periods without affecting the storage capacity.
Comparison of Storage Tiers and Their Cost Implications
Object storage providers offer different storage tiers, each designed for specific access patterns and cost considerations. Choosing the appropriate storage tier is crucial for optimizing costs and performance. The primary storage tiers typically include:
- Hot Storage: Designed for frequently accessed data, hot storage offers the lowest latency and highest performance. This tier is suitable for active datasets that require rapid access. However, it typically has the highest storage costs.
- Standard Storage: This tier offers a balance between performance and cost, suitable for data that is accessed less frequently than hot storage but still requires relatively quick access. It often serves as a default tier for general-purpose data storage.
- Cool Storage: Intended for data accessed less frequently, cool storage provides lower storage costs than standard storage. It might have slightly higher retrieval times compared to hot or standard storage.
- Cold Storage: Designed for archival data that is rarely accessed, cold storage offers the lowest storage costs. It has higher retrieval times and is suitable for long-term data retention.
- Archive Storage: This tier is designed for extremely infrequently accessed data. It has the lowest storage costs but can take hours to retrieve data. It’s appropriate for data archiving and regulatory compliance purposes.
The cost implications of these tiers vary significantly. For example, the cost per gigabyte per month for hot storage is considerably higher than that for cold storage. Organizations should carefully analyze their data access patterns and storage requirements to select the most cost-effective tier. Tools are often provided by cloud providers to analyze access patterns and recommend optimal storage tiering strategies.
Methods for Data Partitioning and Organization Within Object Storage
Effective data partitioning and organization are crucial for optimizing query performance, reducing costs, and simplifying data management within a serverless data lake. Partitioning involves dividing data into smaller, manageable units based on specific criteria, such as date, region, or customer ID.Several methods are employed for data partitioning and organization:
- Time-Based Partitioning: This method partitions data based on time intervals (e.g., daily, weekly, monthly). It’s particularly useful for time-series data and allows for efficient querying of data within specific time ranges. For example, data from a web server can be partitioned by date, enabling quick analysis of daily website traffic.
- Geographic Partitioning: Data is partitioned based on geographic regions or locations. This method is beneficial for analyzing data related to geographical areas, such as sales data by country or sensor data by location.
- Category-Based Partitioning: This approach divides data based on categorical variables, such as product categories, customer segments, or department IDs. It facilitates filtering and analysis of data within specific categories.
- Hash-Based Partitioning: This method uses a hash function to distribute data across partitions. It can be used to balance data across partitions and optimize query performance.
- Prefix-Based Organization: Using prefixes in object keys to create a logical hierarchy, organizing data based on a defined structure. For instance, data can be organized using prefixes such as “year=2023/month=10/day=27/data.csv”.
The choice of partitioning method depends on the specific data and the types of queries that will be performed. The goal is to minimize the amount of data scanned during queries, thereby improving performance and reducing costs. Proper data organization also simplifies data discovery and management.
Data Lifecycle Management Strategies in a Serverless Environment
Data lifecycle management (DLM) is the process of managing data from its creation to its eventual deletion. Implementing DLM strategies is essential for controlling costs, ensuring compliance, and optimizing data storage in a serverless data lake.Several DLM strategies are commonly employed:
- Tiering: Automatically moving data between different storage tiers based on access frequency. This strategy involves moving frequently accessed data to hot storage, less frequently accessed data to cool storage, and archived data to cold or archive storage. Cloud providers often offer automated tiering policies that can be configured to manage this process.
- Data Retention Policies: Defining and enforcing policies for data retention, specifying how long data should be stored before being deleted or archived. These policies can be based on regulatory requirements, business needs, or data value. For example, financial data might need to be retained for several years to comply with regulations.
- Data Archiving: Moving data that is no longer actively used to a lower-cost storage tier, such as cold or archive storage. Archiving helps to reduce storage costs and maintain data for historical analysis or compliance purposes.
- Data Deletion: Removing data that is no longer needed or that has reached its retention period. This strategy helps to reduce storage costs and maintain data privacy.
- Metadata Management: Implementing strategies for managing metadata, such as data catalogs and data lineage tracking. This enables organizations to understand the context and meaning of their data, making it easier to find, use, and govern.
- Automation: Using automation tools and services to streamline data lifecycle management tasks, such as tiering, archiving, and deletion. Automation reduces manual effort and ensures consistent application of DLM policies.
Implementing effective DLM strategies is a continuous process that requires monitoring and adaptation. Organizations should regularly review their DLM policies and adjust them as needed to meet changing business requirements and regulatory mandates.
Querying and Analytics
Serverless data lakes empower organizations to extract valuable insights from their data through robust querying and analytical capabilities. This section explores the diverse querying engines available, provides practical SQL examples, Artikels query optimization strategies, and demonstrates the integration of business intelligence tools for comprehensive data analysis.
Querying Engines for Serverless Data Lakes
Several querying engines are specifically designed to operate seamlessly within serverless data lake architectures, offering scalability, cost-efficiency, and ease of use. These engines typically leverage the underlying object storage (like Amazon S3, Azure Data Lake Storage, or Google Cloud Storage) and provide SQL-based interfaces for querying data.
- AWS Athena: AWS Athena is a serverless query service that allows users to analyze data stored in Amazon S3 using standard SQL. It eliminates the need for setting up or managing infrastructure. Athena automatically handles the scaling and concurrency required to execute queries efficiently. It supports various data formats, including CSV, JSON, Parquet, and ORC. Athena is particularly well-suited for ad-hoc querying, data exploration, and reporting.
- Azure Synapse Analytics (Serverless SQL pool): Azure Synapse Analytics offers a serverless SQL pool that allows users to query data residing in Azure Data Lake Storage Gen2 and other data sources using T-SQL. It provides a pay-per-query model, allowing users to only pay for the compute resources consumed during query execution. Synapse Analytics integrates with other Azure services and supports advanced analytical capabilities.
- Google BigQuery: Google BigQuery is a fully managed, serverless data warehouse that enables fast SQL queries over large datasets. It supports various data formats and provides a highly scalable and cost-effective solution for data analysis. BigQuery’s architecture is optimized for parallel processing, resulting in rapid query execution times. It also offers built-in machine learning capabilities.
SQL Queries for Data Retrieval and Analysis
SQL (Structured Query Language) is the standard language for interacting with data in a relational database or data warehouse. The querying engines mentioned above support standard SQL, enabling users to perform a wide range of data retrieval and analysis tasks.
Here are some examples of SQL queries:
- Basic Data Retrieval: Retrieving all columns and rows from a table.
SELECT
- FROM my_table; - Filtering Data: Retrieving data based on specific criteria using the
WHEREclause.SELECT column1, column2 FROM my_table WHERE column3 = 'value'; - Aggregating Data: Calculating aggregate values such as sums, averages, counts, etc., using functions like
SUM(),AVG(),COUNT(), andGROUP BY.SELECT column1, SUM(column2) FROM my_table GROUP BY column1; - Joining Data: Combining data from multiple tables using
JOINclauses.SELECT t1.column1, t2.column2 FROM table1 t1 JOIN table2 t2 ON t1.join_column = t2.join_column; - Sorting Data: Ordering the result set using the
ORDER BYclause.SELECT
- FROM my_table ORDER BY column1 DESC;
Methods for Optimizing Query Performance
Optimizing query performance is crucial for ensuring efficient data analysis and minimizing costs. Several strategies can be employed to improve query execution times within a serverless data lake environment.
- Data Partitioning: Partitioning data involves organizing data into logical segments based on specific criteria (e.g., date, region). This allows the query engine to read only the relevant data partitions, significantly reducing the amount of data scanned. For example, a dataset containing sales data could be partitioned by year and month.
- Data Format Selection: Choosing the right data format can have a significant impact on query performance. Formats like Parquet and ORC are columnar storage formats optimized for analytical queries. These formats store data in a column-oriented manner, which allows the query engine to read only the necessary columns for a query, reducing I/O operations.
- Query Optimization Techniques: Applying various query optimization techniques can improve efficiency. This includes using appropriate indexes, avoiding unnecessary joins, and optimizing the use of
WHEREclauses. - Data Compression: Compressing data reduces the storage space required and can improve query performance. Compression algorithms, such as GZIP or Snappy, can be applied to data files stored in the data lake.
- Query Engine Specific Optimizations: Each query engine has its own set of optimization techniques. It is important to familiarize oneself with the specific features and best practices of the chosen engine. For instance, BigQuery supports features like clustering and materialized views to optimize query performance.
Integrating Business Intelligence Tools
Integrating business intelligence (BI) tools with a serverless data lake allows users to visualize, analyze, and share data insights effectively. Several BI tools seamlessly integrate with the querying engines mentioned earlier.
- Connecting to Querying Engines: BI tools typically offer connectors to connect to the different querying engines (e.g., Athena, Synapse Analytics, BigQuery). These connectors enable the BI tool to access the data stored in the data lake.
- Data Visualization and Reporting: Once connected, users can create dashboards, reports, and visualizations to explore and analyze data. BI tools provide a wide range of visualization options, including charts, graphs, and tables.
- Data Modeling: BI tools allow users to model the data, creating relationships between tables and defining calculated fields. This simplifies data analysis and enables more complex reporting.
- Scheduling and Automation: Many BI tools offer features for scheduling reports and dashboards, automating data refresh processes, and sending alerts based on data changes.
- Popular BI Tools: Popular BI tools include Tableau, Power BI, Looker, and Qlik Sense. These tools provide a comprehensive set of features for data analysis and reporting.
Security and Access Control
The security posture of a serverless data lake is paramount, safeguarding sensitive data from unauthorized access and breaches. Implementing robust security measures is not merely a technical requirement but a critical aspect of maintaining data integrity, compliance, and trust. The inherent distributed nature of serverless architectures introduces unique security considerations, necessitating a multi-layered approach to protect data at rest, in transit, and during processing.
This section details the crucial aspects of securing a serverless data lake, covering access control, encryption, and compliance requirements.
Security Considerations for a Serverless Data Lake
The serverless paradigm presents distinct security challenges that must be addressed to maintain data confidentiality, integrity, and availability. These challenges stem from the distributed nature of the architecture, the use of third-party services, and the dynamic scaling capabilities of serverless functions. Addressing these concerns requires a proactive and comprehensive approach.
- Identity and Access Management (IAM): Centralized management of identities and permissions is essential. Serverless data lakes often rely on cloud provider IAM services, which enable fine-grained control over access to data lake resources, such as storage buckets, compute functions, and databases. Properly configured IAM policies are crucial to prevent unauthorized access.
- Data Encryption: Encryption is a fundamental security practice. Data should be encrypted both at rest and in transit. Encryption at rest protects data stored in object storage or databases, while encryption in transit secures data during network communication. Serverless platforms typically offer built-in encryption capabilities.
- Network Security: Network security encompasses the protection of the data lake’s network perimeter and internal communications. This includes the use of virtual private clouds (VPCs), firewalls, and network access control lists (ACLs) to restrict access to the data lake resources.
- Vulnerability Management: Regular vulnerability scanning and patching of serverless functions and underlying infrastructure are vital. Serverless environments are often updated automatically by the cloud provider, but it’s essential to stay informed about potential vulnerabilities and take appropriate action.
- Monitoring and Auditing: Continuous monitoring and auditing are necessary to detect and respond to security incidents. This involves collecting logs from all data lake components, analyzing them for suspicious activity, and setting up alerts to notify security teams of potential threats.
- Data Loss Prevention (DLP): Implementing DLP strategies helps prevent sensitive data from leaving the data lake. This involves identifying sensitive data, monitoring its movement, and enforcing policies to prevent unauthorized sharing or access.
Implementing Access Control and Authorization
Effective access control is a cornerstone of a secure serverless data lake. The goal is to ensure that only authorized users and services can access data and perform operations. Implementing access control involves several key steps.
- Identity Management: Establish a robust identity management system. This includes creating and managing user accounts, groups, and roles. Leverage cloud provider’s identity management services (e.g., AWS IAM, Azure Active Directory, Google Cloud IAM).
- Role-Based Access Control (RBAC): Implement RBAC to assign permissions based on user roles. Define roles with specific privileges, such as read-only access, write access, or administrative access. Assign users to appropriate roles to grant them the necessary permissions.
- Fine-Grained Permissions: Utilize fine-grained permissions to restrict access to specific data elements or resources. For example, grant users access to only certain tables, columns, or files within the data lake. This minimizes the impact of a potential security breach.
- Least Privilege Principle: Apply the principle of least privilege, granting users only the minimum permissions necessary to perform their tasks. This limits the potential damage if an account is compromised.
- Multi-Factor Authentication (MFA): Enforce MFA for all user accounts to enhance security. MFA requires users to provide multiple forms of authentication, such as a password and a one-time code from a mobile app.
- Regular Audits: Conduct regular audits of access control configurations to ensure they are up-to-date and effective. Review user permissions, access logs, and security policies periodically.
Best Practices for Data Encryption and Protection
Data encryption is a critical component of a comprehensive security strategy. Encryption protects data from unauthorized access, even if the underlying storage or network is compromised. Several best practices should be followed to ensure data is adequately protected.
- Encryption at Rest: Encrypt all data at rest using encryption keys managed by the cloud provider or a dedicated key management service (KMS). Consider using server-side encryption (SSE) for object storage and database encryption features.
- Encryption in Transit: Encrypt all data in transit using Transport Layer Security (TLS) or Secure Sockets Layer (SSL) protocols. This ensures that data is protected during network communication.
- Key Management: Implement a robust key management strategy. Use a KMS to securely generate, store, and manage encryption keys. Rotate keys regularly to minimize the risk of compromise.
- Data Masking and Tokenization: Implement data masking and tokenization techniques to protect sensitive data. Data masking replaces sensitive data with masked values, while tokenization replaces sensitive data with non-sensitive tokens.
- Data Loss Prevention (DLP): Implement DLP solutions to monitor and control the movement of sensitive data within the data lake. DLP tools can identify and prevent unauthorized data exfiltration.
- Regular Security Audits: Conduct regular security audits to verify the effectiveness of encryption and data protection measures. Review encryption configurations, key management practices, and DLP policies.
Compliance Aspects Related to Data Security
Adhering to relevant compliance regulations is essential for many organizations. Data security measures must align with these regulations to avoid penalties and maintain customer trust.
- GDPR (General Data Protection Regulation): For organizations that handle the personal data of EU citizens, GDPR mandates strict data security requirements. This includes data encryption, access controls, and data minimization.
- CCPA (California Consumer Privacy Act): CCPA grants California residents rights regarding their personal data, including the right to access, delete, and opt-out of the sale of their data. Data security measures must comply with CCPA requirements.
- HIPAA (Health Insurance Portability and Accountability Act): HIPAA regulates the protection of protected health information (PHI). Data lakes storing PHI must implement stringent security measures, including encryption, access controls, and audit trails.
- PCI DSS (Payment Card Industry Data Security Standard): PCI DSS applies to organizations that handle credit card data. Data security measures must comply with PCI DSS requirements, including data encryption, access controls, and network security.
- Industry-Specific Regulations: Organizations may be subject to other industry-specific regulations, such as those related to financial services, healthcare, or government. Data security measures must comply with these regulations.
- Regular Compliance Audits: Conduct regular compliance audits to ensure that data security measures meet the requirements of relevant regulations. Document security policies, procedures, and configurations.
Use Cases and Examples

Serverless data lake architectures are gaining traction across diverse industries, providing scalable, cost-effective, and agile solutions for data storage, processing, and analysis. Their flexibility makes them adaptable to various business needs, from simple data warehousing to complex machine learning applications. The following sections detail specific use cases and examples, illustrating how companies are leveraging this technology to solve real-world problems and gain a competitive edge.
Real-World Use Cases
Many companies are successfully implementing serverless data lakes to address complex business challenges. These implementations often focus on improving data accessibility, reducing operational costs, and accelerating insights.* E-commerce: Analyzing customer behavior, personalizing product recommendations, and optimizing marketing campaigns.
Financial Services
Detecting fraud, managing risk, and improving customer service.
Healthcare
Analyzing patient data, improving clinical outcomes, and accelerating research.
Manufacturing
Optimizing production processes, predicting equipment failures, and improving supply chain efficiency.
Media and Entertainment
Personalizing content recommendations, optimizing advertising revenue, and analyzing audience engagement.
Retail
Optimizing inventory management, personalizing customer experiences, and predicting sales trends.
Telecommunications
Analyzing network performance, improving customer service, and preventing fraud.
Illustrative Examples of Serverless Data Lake Implementations
Companies are utilizing serverless data lakes in diverse ways to achieve specific business goals. These examples highlight the adaptability and versatility of the architecture.* Netflix: Utilizes a serverless data lake for personalized content recommendations. By analyzing user viewing habits, preferences, and interactions, Netflix creates tailored recommendations that drive user engagement and retention. This involves ingesting massive amounts of streaming data, applying machine learning models, and dynamically updating recommendation algorithms.
The scalability of the serverless architecture ensures the system can handle peak loads and evolving data volumes.
“Netflix uses serverless data lakes to power its recommendation engine, driving a significant portion of its subscriber growth.”
* Airbnb: Employs a serverless data lake for fraud detection and prevention. By analyzing transaction data, user behavior, and listing information, Airbnb can identify and prevent fraudulent activities, protecting both hosts and guests. The architecture allows for real-time analysis and rapid response to emerging threats. The cost-effectiveness of serverless infrastructure is crucial for handling the high volume of transactions and the need for continuous monitoring.* Spotify: Leverages a serverless data lake for personalized music recommendations and understanding listener preferences.
By analyzing user listening history, genre preferences, and social connections, Spotify can curate customized playlists and provide targeted music suggestions. This involves processing vast amounts of audio data, user data, and social network information. The serverless architecture allows for efficient scaling to accommodate millions of users and the constant flow of new data.
Industries Benefiting from Serverless Data Lakes
A wide range of industries can benefit from the capabilities of a serverless data lake. The ability to scale resources dynamically, control costs effectively, and integrate with various data sources makes it a compelling solution for businesses of all sizes.
- E-commerce: Optimizing product recommendations, personalizing marketing campaigns, and improving customer experience.
- Financial Services: Detecting fraud, managing risk, and improving customer service.
- Healthcare: Analyzing patient data, improving clinical outcomes, and accelerating research.
- Manufacturing: Optimizing production processes, predicting equipment failures, and improving supply chain efficiency.
- Media and Entertainment: Personalizing content recommendations, optimizing advertising revenue, and analyzing audience engagement.
- Retail: Optimizing inventory management, personalizing customer experiences, and predicting sales trends.
- Telecommunications: Analyzing network performance, improving customer service, and preventing fraud.
- Transportation and Logistics: Optimizing routes, predicting delays, and improving operational efficiency.
- Government: Analyzing public health data, improving citizen services, and detecting fraud.
Scenario: Implementing a Serverless Data Lake for the Retail Industry
A large retail chain wants to leverage its customer data to improve its understanding of customer behavior, personalize shopping experiences, and optimize inventory management. The chain collects data from various sources, including point-of-sale systems, e-commerce platforms, customer relationship management (CRM) systems, and marketing campaigns.
The Challenge:The retail chain faces challenges with traditional data warehousing approaches due to the increasing volume and variety of data, the need for real-time insights, and the desire for cost optimization.
The existing infrastructure is not easily scalable and struggles to handle the dynamic demands of the business.
The Solution:The retail chain implements a serverless data lake architecture using the following components:
- Data Ingestion: Data from various sources is ingested using serverless services like AWS Glue, Azure Data Factory, or Google Cloud Dataflow. These services automatically scale to handle the ingestion of large datasets from diverse sources.
- Data Storage: Data is stored in a cost-effective object storage service such as Amazon S3, Azure Blob Storage, or Google Cloud Storage. The storage is organized into a data lake structure, following a data lakehouse approach to improve data quality and enable governance.
- Data Processing: Serverless compute services such as AWS Lambda, Azure Functions, or Google Cloud Functions are used for data transformation, cleaning, and enrichment. These services are triggered by data ingestion events and scale automatically to handle the processing load.
- Data Querying and Analytics: Serverless query engines such as Amazon Athena, Azure Synapse Analytics, or Google BigQuery are used for ad-hoc analysis and reporting. These services enable business users to query the data lake directly without managing infrastructure.
- Data Visualization and Reporting: Business intelligence tools like Tableau, Power BI, or Looker are used to visualize the data and generate reports. These tools connect to the serverless query engines to access the data in the data lake.
Benefits:
- Scalability: The serverless architecture automatically scales to handle fluctuations in data volume and query load, ensuring consistent performance.
- Cost-Effectiveness: The pay-per-use model reduces operational costs by eliminating the need to provision and manage infrastructure.
- Agility: The architecture enables faster time-to-insights, allowing the retail chain to respond quickly to market changes.
- Improved Customer Experience: Personalized product recommendations, targeted marketing campaigns, and optimized inventory management enhance the customer experience.
- Data-Driven Decision Making: The retail chain can make data-driven decisions based on comprehensive customer insights.
Challenges and Considerations
Implementing a serverless data lake architecture presents numerous advantages, as previously discussed. However, it’s crucial to acknowledge the inherent challenges and complexities associated with this approach. Successfully navigating these considerations is essential for realizing the full potential of a serverless data lake and avoiding common pitfalls. This section details the key hurdles and provides practical strategies for mitigation.
Potential Challenges of Implementation
The transition to a serverless data lake involves several potential challenges that must be addressed proactively. These challenges span various aspects, from architectural design to operational management.
- Vendor Lock-in: Relying heavily on a single cloud provider’s serverless services can create vendor lock-in. This can limit flexibility and potentially increase costs if the provider changes its pricing or service offerings. For example, migrating a large-scale data lake from Amazon Web Services (AWS) to Google Cloud Platform (GCP) would require significant refactoring of code and infrastructure.
- Cold Starts: Serverless functions can experience cold starts, where the function instance needs to be initialized before processing a request. This can lead to increased latency, particularly for infrequently accessed functions. Optimizing function code, pre-warming functions, and utilizing provisioned concurrency can mitigate this.
- Debugging and Monitoring Complexity: Debugging distributed serverless applications can be more complex than debugging traditional monolithic applications. Tracing requests across multiple services and analyzing logs from various sources requires sophisticated monitoring tools and strategies.
- Cost Management: While serverless architectures can offer cost savings through pay-per-use models, inefficient resource utilization or poorly optimized code can lead to unexpected and escalating costs. Careful monitoring, resource allocation, and cost optimization strategies are essential. For instance, an improperly configured data ingestion pipeline could inadvertently trigger excessive function invocations, rapidly increasing costs.
- Security Concerns: Securing a serverless data lake involves managing access control, data encryption, and protecting against various security threats. Misconfigurations or vulnerabilities in serverless functions or underlying infrastructure can expose sensitive data.
- Data Consistency and Transactions: Ensuring data consistency across multiple serverless functions and services can be challenging. Implementing distributed transactions and handling eventual consistency scenarios requires careful design and consideration.
- Scalability Limits: While serverless architectures are designed to scale automatically, they may have limitations on the maximum resources that can be allocated to a single function or service. Understanding these limits is crucial for designing applications that can handle peak loads.
Limitations of Serverless Architectures
Serverless architectures, while offering numerous benefits, are not without limitations. Recognizing these constraints is crucial for making informed architectural decisions and avoiding scenarios where serverless is not the optimal solution.
- Statelessness: Serverless functions are inherently stateless. Maintaining state requires using external services like databases or caches, adding complexity to the architecture. This statelessness can complicate scenarios requiring session management or persistent data storage within a function’s execution environment.
- Execution Time Limits: Serverless functions often have execution time limits, typically ranging from a few minutes to a maximum, which varies by provider. Long-running processes or complex data transformations might exceed these limits, necessitating alternative approaches such as breaking down tasks into smaller units or using containerized solutions.
- Vendor-Specific Implementations: The specific implementations of serverless services vary between cloud providers. This can make it challenging to migrate applications from one provider to another without significant code changes. Using cloud-agnostic tools and libraries can improve portability.
- Monitoring and Observability Challenges: As mentioned previously, monitoring and observability can be complex. The distributed nature of serverless applications makes it difficult to track the flow of data and troubleshoot issues. Effective monitoring and logging strategies are crucial for identifying and resolving performance bottlenecks.
- Debugging Difficulties: Debugging serverless functions can be more difficult than debugging traditional applications. Debugging tools and techniques are often provider-specific, and it can be challenging to reproduce issues locally.
- Dependency Management: Managing dependencies in serverless functions can be complex. Ensuring that all dependencies are properly installed and configured is essential for preventing runtime errors. Using package managers and automated build processes can help simplify dependency management.
Strategies for Troubleshooting and Debugging Serverless Applications
Effective troubleshooting and debugging are essential for maintaining the reliability and performance of a serverless data lake. Several strategies and tools can aid in identifying and resolving issues efficiently.
- Comprehensive Logging: Implement detailed logging within serverless functions and services. Log events, errors, and key performance metrics to facilitate root cause analysis. Structured logging formats (e.g., JSON) make it easier to parse and analyze logs.
- Distributed Tracing: Utilize distributed tracing tools to track requests as they flow through the serverless architecture. This allows for identifying performance bottlenecks and pinpointing the services or functions that are contributing to issues. Tools like AWS X-Ray, Google Cloud Trace, and Jaeger are valuable in this context.
- Local Development and Testing: Use local development environments and testing frameworks to simulate serverless function execution and test code changes before deployment. This can help identify and resolve issues early in the development cycle.
- Error Handling and Retries: Implement robust error handling mechanisms within serverless functions and services. Implement retry logic to handle transient errors and prevent failures. Circuit breakers can prevent cascading failures by stopping calls to failing services.
- Monitoring and Alerting: Set up monitoring and alerting to proactively identify and respond to issues. Monitor key performance indicators (KPIs) such as function invocation times, error rates, and resource utilization. Configure alerts to notify the appropriate teams when thresholds are exceeded.
- Version Control and Rollbacks: Employ version control systems to manage code changes and facilitate rollbacks to previous versions in case of issues. This ensures that any problematic code can be reverted quickly and efficiently.
- Debugging Tools: Utilize cloud provider-specific debugging tools to step through function code, inspect variables, and analyze execution logs. These tools provide valuable insights into the function’s behavior and help identify the source of errors.
Monitoring and Logging Aspects
Monitoring and logging are critical components of a serverless data lake, providing insights into the health, performance, and security of the system. Effective monitoring and logging practices enable proactive issue detection, performance optimization, and security incident response.
- Real-time Monitoring Dashboards: Create real-time dashboards that visualize key performance indicators (KPIs) such as function invocation counts, execution times, error rates, and resource utilization. These dashboards provide a comprehensive view of the system’s health and performance. Examples include Grafana, Kibana, and the monitoring dashboards provided by cloud providers.
- Detailed Log Analysis: Implement detailed logging across all serverless functions and services. Log events, errors, and key performance metrics to facilitate root cause analysis. Use structured logging formats (e.g., JSON) to make logs easily searchable and analyzable.
- Alerting and Notifications: Set up alerts and notifications to proactively identify and respond to issues. Configure alerts to trigger when specific thresholds are exceeded, such as high error rates or excessive execution times. Integrate with notification services (e.g., email, Slack) to ensure timely communication.
- Performance Monitoring: Monitor function execution times, memory usage, and other performance metrics to identify bottlenecks and optimize performance. Analyze performance data to identify slow-running functions or services that require optimization.
- Security Monitoring: Monitor security-related events, such as unauthorized access attempts, data access patterns, and unusual activity. Implement security alerts to detect and respond to potential security threats.
- Cost Monitoring: Monitor resource consumption and associated costs to optimize cost efficiency. Analyze cost data to identify areas where costs can be reduced, such as optimizing function resource allocation or reducing unnecessary function invocations.
- Centralized Logging and Aggregation: Aggregate logs from all serverless functions and services into a centralized logging system. This provides a single pane of glass for viewing and analyzing logs, simplifying troubleshooting and analysis. Tools like the ELK stack (Elasticsearch, Logstash, Kibana) and Splunk are widely used for centralized logging.
Future Trends and Innovations
The evolution of serverless data lake architecture is accelerating, driven by the insatiable demand for real-time data processing, advanced analytics, and the increasing adoption of artificial intelligence. The following section explores the emerging trends, future potential, and innovative architectures shaping the landscape of serverless data lakes.
Emerging Trends in Serverless Data Lake Technologies
The serverless data lake paradigm is constantly evolving, with several key trends influencing its development. These advancements aim to enhance performance, reduce costs, and simplify data management.
- Automated Optimization and Management: The rise of intelligent automation is streamlining data lake operations. This involves the use of machine learning algorithms to automatically optimize resource allocation, query performance, and data storage. For example, systems can dynamically adjust the compute resources assigned to query execution based on real-time workloads and data characteristics, leading to significant cost savings and improved efficiency.
- Enhanced Data Governance and Metadata Management: Robust data governance and metadata management are becoming increasingly crucial. Serverless data lakes are integrating advanced metadata catalogs, lineage tracking, and data quality monitoring tools. These features enable better data discoverability, compliance, and trust. For instance, tools like AWS Glue Data Catalog and Azure Data Catalog are becoming integral parts of serverless data lake architectures.
- Serverless Machine Learning Integration: The seamless integration of serverless machine learning services is a major trend. This allows data scientists to build, train, and deploy machine learning models directly within the data lake environment without the need for complex infrastructure management. Services like Amazon SageMaker and Azure Machine Learning enable this integration, accelerating the development and deployment of AI-powered applications.
- Real-Time Data Streaming and Processing: The demand for real-time insights is driving the adoption of serverless streaming technologies. Serverless data lakes are increasingly integrating with services like AWS Kinesis, Azure Event Hubs, and Google Cloud Pub/Sub to ingest, process, and analyze streaming data in real-time. This enables applications such as fraud detection, personalized recommendations, and predictive maintenance.
- Edge Computing Integration: The integration of edge computing with serverless data lakes is gaining traction. This involves processing data closer to the source, reducing latency and bandwidth costs. For example, data generated by IoT devices at the edge can be pre-processed and aggregated before being sent to the central data lake for further analysis.
Future of Data Lake Architecture
The future of data lake architecture is characterized by greater automation, intelligence, and scalability. The following points Artikel the key aspects of its evolution.
- Self-Managing Data Lakes: Future data lakes will be largely self-managing, with automated provisioning, scaling, and optimization capabilities. Machine learning will play a central role in these systems, continuously monitoring performance, predicting resource needs, and proactively adjusting infrastructure.
- Data Fabric Approach: The data fabric concept, which provides a unified view of data across various sources and storage systems, will become more prevalent. Serverless data lakes will act as a central hub, seamlessly integrating with diverse data sources and providing a consistent access layer for data consumers.
- Decentralized Data Ownership and Governance: Data governance will evolve towards a more decentralized model, with data owners having greater control over their data assets. This will require advanced metadata management and access control mechanisms to ensure data security and compliance.
- Enhanced Data Discovery and Collaboration: Data discovery and collaboration tools will become more sophisticated, enabling data scientists and analysts to easily find, understand, and collaborate on data. This will involve the use of advanced search capabilities, data profiling, and collaborative annotation features.
- Quantum Computing Integration: As quantum computing matures, serverless data lakes will begin to integrate with quantum computing resources to accelerate complex data analysis tasks. This will be particularly relevant for tasks such as optimization, simulations, and machine learning model training.
Potential of Serverless Data Lakes in the Age of Big Data and AI
Serverless data lakes are ideally positioned to thrive in the age of big data and AI, offering several key advantages.
- Scalability and Elasticity: Serverless architectures provide unmatched scalability and elasticity, allowing data lakes to handle massive datasets and fluctuating workloads without manual intervention. This is critical for supporting the ever-growing volume, velocity, and variety of data.
- Cost Efficiency: The pay-per-use model of serverless computing eliminates the need for upfront investments and reduces operational costs. This makes serverless data lakes a cost-effective solution for organizations of all sizes.
- Simplified Operations: Serverless data lakes simplify data management and reduce the operational burden on IT teams. This allows organizations to focus on deriving insights from their data rather than managing infrastructure.
- Accelerated Innovation: Serverless data lakes enable rapid prototyping and experimentation, accelerating the development of AI and machine learning applications. Data scientists can quickly access and analyze data, train models, and deploy them into production.
- Enhanced Agility: Serverless architectures provide the agility needed to adapt to changing business requirements. Organizations can quickly deploy new data pipelines, integrate with new data sources, and scale their data lakes as needed.
Descriptive Illustration of a Future Serverless Data Lake Architecture
Imagine a future serverless data lake architecture. It comprises the following key components and their interactions:
A visual representation would illustrate the following components and their relationships.
- Data Ingestion Layer: The architecture begins with various data sources, including streaming data from IoT devices, social media feeds, and application logs. This data is ingested using serverless services like AWS Kinesis, Azure Event Hubs, and Google Cloud Pub/Sub. These services handle the real-time ingestion and buffering of data.
- Data Storage Layer: The ingested data is stored in a serverless object storage service, such as Amazon S3, Azure Blob Storage, or Google Cloud Storage. Data is stored in various formats (e.g., Parquet, Avro, JSON) based on its structure and intended use. A metadata catalog, such as AWS Glue Data Catalog, Azure Data Catalog, or Google Cloud Data Catalog, is used to manage and organize the data.
- Data Processing Layer: The data is processed using serverless compute services, such as AWS Lambda, Azure Functions, and Google Cloud Functions, or serverless data processing services like AWS Glue, Azure Synapse Analytics, or Google Cloud Dataflow. These services are used for data transformation, cleansing, and enrichment.
- Analytics and Querying Layer: Data analysts and data scientists can query the data using serverless query engines like Amazon Athena, Azure Synapse Serverless SQL pool, or Google BigQuery. These services allow for ad-hoc querying and reporting.
- Machine Learning Layer: The data lake is integrated with serverless machine learning services, such as Amazon SageMaker, Azure Machine Learning, and Google Cloud AI Platform. Data scientists can train and deploy machine learning models directly within the data lake environment.
- Security and Governance Layer: A centralized security and governance layer manages access control, data encryption, and compliance. This layer uses services like AWS IAM, Azure Active Directory, and Google Cloud IAM to enforce security policies.
- Data Catalog and Metadata Management: A central data catalog stores metadata about the data, including data lineage, data quality metrics, and data governance policies.
The architecture would showcase a flow of data from the various sources, through the ingestion layer, into the storage layer, and then to the processing, analytics, machine learning, and security layers. Arrows would indicate the flow of data and the interactions between the components. The overall design emphasizes automation, scalability, and ease of use, allowing for the seamless integration of various data sources and processing services.
The illustration would also highlight the use of machine learning for automated optimization and data governance.
Conclusive Thoughts

In summary, a serverless data lake architecture represents a paradigm shift in data management, offering a dynamic, cost-effective, and scalable solution for handling large datasets. By embracing serverless technologies, organizations can overcome the limitations of traditional data warehouses and unlock the full potential of their data. This architecture is poised to play a crucial role in the future of data analytics, empowering businesses to make data-driven decisions with greater speed and precision.
As the technology matures, serverless data lakes will continue to evolve, providing even more powerful and efficient tools for data management and analysis.
FAQs
What is the primary advantage of a serverless data lake over a traditional data warehouse?
The primary advantage lies in its cost-effectiveness and scalability. Serverless data lakes eliminate the need for infrastructure management, leading to reduced operational costs and automatic scaling to handle fluctuating data volumes.
How does data ingestion work in a serverless data lake?
Data ingestion in a serverless data lake typically involves using serverless functions (e.g., AWS Lambda) to process data streams from various sources. These functions can perform data transformation, validation, and routing to object storage.
What are the key security considerations for a serverless data lake?
Security considerations include implementing access control and authorization, data encryption (both in transit and at rest), and adhering to compliance regulations. Proper configuration of identity and access management (IAM) is crucial.
How can query performance be optimized in a serverless data lake?
Query performance can be optimized through data partitioning, efficient query design, and the use of optimized query engines (e.g., AWS Athena). Utilizing appropriate data formats and indexing strategies is also essential.
What are some real-world use cases for serverless data lakes?
Real-world use cases include analyzing IoT sensor data, processing clickstream data for web analytics, and building data-driven applications for financial modeling and fraud detection. Any scenario that involves large, rapidly changing datasets can benefit.