The serverless execution context represents a fundamental shift in how we approach software deployment and resource management. It allows developers to focus on writing code without the burden of managing servers, leading to increased efficiency and scalability. This paradigm leverages a pay-per-use model, where resources are allocated only when code is actively running, offering significant cost savings and operational flexibility.
This exploration will dissect the core principles, architecture, and practical applications of serverless execution contexts. We will investigate their ephemeral nature, contrasting them with traditional server environments and container-based deployments. Furthermore, the analysis will encompass the nuances of cloud provider implementations, security considerations, monitoring techniques, and the integration of serverless functions within event-driven architectures. Ultimately, we aim to provide a comprehensive understanding of how serverless execution contexts are shaping the future of software development.
Introduction to Serverless Execution Context

The serverless execution context represents a fundamental shift in how applications are deployed and managed. It abstracts away the underlying infrastructure, allowing developers to focus solely on their code and its functionality. This approach is particularly beneficial in scenarios demanding dynamic scaling and efficient resource utilization.
Fundamental Concept of Serverless Execution Context
A serverless execution context provides a runtime environment where code is executed without the need for managing servers. It allows developers to upload code (functions) that are triggered by specific events, such as HTTP requests, database updates, or scheduled tasks. The cloud provider handles all aspects of server management, including provisioning, scaling, and maintenance. The core idea is that the developer only pays for the actual compute time used by the function, leading to cost optimization.
Scenario: Scalability Benefits
Consider an e-commerce platform that experiences significant traffic spikes during promotional events. A traditional server-based architecture would require provisioning enough resources to handle peak loads, which often leads to underutilized resources during off-peak hours. A serverless execution context offers a solution for such scenarios.The platform’s checkout process, for example, could be implemented as a serverless function. During a promotional event, the function automatically scales up to handle the increased volume of checkout requests.
The cloud provider dynamically allocates more resources (CPU, memory) to the function instances as needed. Once the event concludes and traffic subsides, the function automatically scales down, reducing resource consumption and associated costs. This dynamic scaling capability ensures that the platform can handle traffic fluctuations efficiently without manual intervention, leading to improved user experience and cost savings.
Core Components Involved in Creation
Creating a serverless execution context involves several key components working together. These components are typically managed by the cloud provider.
- Event Sources: These are the triggers that initiate the execution of the serverless function. Examples include HTTP requests, database changes, scheduled events (e.g., cron jobs), and message queue events.
- Function Code: This is the developer-written code that performs the desired task. It is packaged and uploaded to the cloud provider’s platform. The code is typically written in a supported programming language, such as Python, Node.js, Java, or Go.
- Runtime Environment: This provides the necessary environment for executing the function code. It includes the operating system, language runtime, and any required libraries or dependencies. The runtime environment is managed by the cloud provider.
- Execution Engine: The execution engine is responsible for running the function code. It receives the event, invokes the function, and manages the execution process. The engine handles the scaling and resource allocation based on the incoming workload.
- Invocation Service: This service receives requests and directs them to the execution engine. It manages the function invocations and monitors the overall system performance.
- Monitoring and Logging: The serverless platform provides monitoring and logging capabilities to track function execution, errors, and performance metrics. This data is crucial for debugging, optimization, and capacity planning.
- API Gateway: (Optional) An API gateway can be used to expose serverless functions as APIs, providing a way for clients to interact with the functions via HTTP requests. It handles tasks such as routing, authentication, and rate limiting.
Key Characteristics of Serverless Execution Contexts
Serverless execution contexts are fundamentally different from traditional computing environments. Their characteristics are designed to provide developers with an environment focused on code execution rather than infrastructure management. This section explores the defining features of these contexts, emphasizing their transient nature, resource management strategies, and the benefits of automated scaling.
Ephemeral Nature of Serverless Execution Contexts
The ephemeral nature of serverless execution contexts is a core principle. This transient behavior contrasts sharply with the persistent nature of traditional servers. These contexts are created, utilized, and destroyed with each function invocation, leading to significant implications for application design and operational practices.Serverless functions, for example, are designed to be stateless. This means they should not rely on local storage or retain any state information between invocations.
Instead, data persistence is typically handled by external services such as databases or object storage. The function’s execution environment, including its memory space and allocated resources, is ephemeral and discarded after the function completes its task.The short-lived nature of these contexts has several ramifications:
- Cold Starts: A cold start occurs when a serverless function is invoked and the execution environment needs to be initialized. This can introduce latency, as the system must provision resources and load the function’s code. The severity of cold starts varies based on factors like the programming language, function size, and platform implementation. For example, a function written in Python might experience a slower cold start compared to a function written in Go.
- Statelessness: As mentioned, the emphasis on statelessness necessitates careful consideration of data management. Functions must interact with external data stores to persist information.
- Rapid Deployment: The ephemeral nature facilitates rapid deployment and updates. Because there’s no persistent infrastructure to manage, changes can be rolled out quickly, enabling agile development practices.
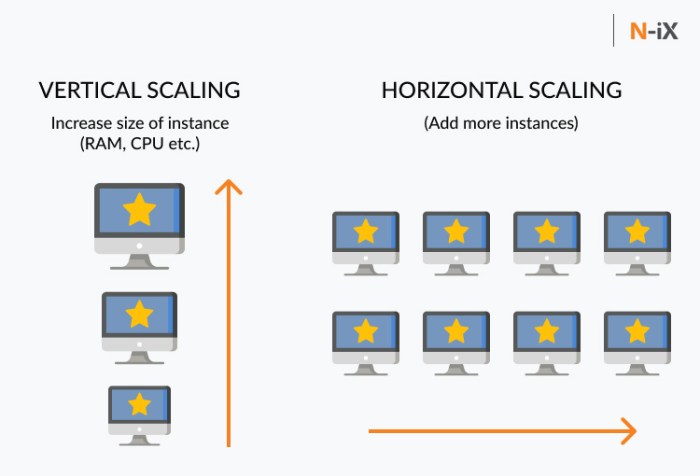
Comparison of Serverless Execution Contexts with Traditional Environments for Resource Management
Resource management in serverless contexts differs significantly from traditional server environments. Traditional servers require manual provisioning, scaling, and ongoing monitoring of resources like CPU, memory, and storage. In contrast, serverless platforms abstract away these complexities, providing a pay-per-use model where resources are dynamically allocated and deallocated based on demand.The key differences can be summarized as follows:
| Aspect | Traditional Server Environments | Serverless Execution Contexts |
|---|---|---|
| Resource Provisioning | Manual; requires estimating peak load and provisioning accordingly. | Automatic; resources are provisioned on-demand by the platform. |
| Scaling | Manual or automated (e.g., using auto-scaling groups); requires pre-configured scaling rules. | Automatic; scales up and down based on incoming requests. |
| Cost Model | Fixed cost (for the server) plus variable costs (e.g., bandwidth). | Pay-per-use; costs are based on the actual execution time and resource consumption. |
| Management Overhead | High; requires managing servers, operating systems, and related infrastructure. | Low; the platform manages the underlying infrastructure. |
The resource management in serverless environments offers substantial advantages:
- Reduced Operational Overhead: Developers can focus on writing code rather than managing servers.
- Cost Optimization: Pay-per-use pricing ensures that you only pay for the resources you consume.
- Increased Scalability: The platform automatically scales resources to meet demand.
Benefits of Automatic Scaling Within a Serverless Execution Context
Automatic scaling is a pivotal advantage of serverless execution contexts. The platform automatically adjusts the resources allocated to a function based on the incoming workload. This dynamic allocation ensures optimal performance and cost efficiency. The scaling mechanism is typically triggered by metrics like the number of concurrent function invocations or the duration of function execution.The benefits of automatic scaling are numerous:
- High Availability: The platform can automatically scale up to handle traffic spikes, ensuring that functions remain available even under heavy load. For example, if a popular e-commerce website experiences a sudden surge in traffic during a flash sale, the serverless platform can automatically provision additional resources to handle the increased number of requests, preventing service degradation.
- Cost Efficiency: Resources are allocated only when needed. When the workload decreases, the platform automatically scales down, reducing costs. If an application experiences low traffic during off-peak hours, the platform reduces the number of allocated resources, minimizing the associated expenses.
- Simplified Management: Developers do not need to manually configure or manage scaling rules. The platform handles the scaling process automatically, simplifying the development and operational workflow.
- Improved Performance: Automatic scaling ensures that sufficient resources are available to meet the performance demands of the application. By dynamically allocating resources based on real-time demand, serverless platforms can provide a consistent and responsive user experience, even during peak loads.
How Serverless Execution Contexts Work
Serverless execution contexts provide a managed environment for executing code without the need to provision or manage servers. This architecture shifts the operational burden from the developer to the cloud provider, enabling developers to focus on writing code and building applications. The execution process involves several key stages, from code deployment to function invocation and resource management.
Lifecycle of a Function within a Serverless Execution Context
The lifecycle of a function within a serverless execution context is a carefully orchestrated process, beginning with the function’s deployment and culminating in its execution and eventual removal. This lifecycle ensures efficient resource utilization and scalability.The function lifecycle typically includes the following phases:
- Deployment: The developer uploads the function code (and any dependencies) to the serverless platform. This usually involves packaging the code into a deployment package (e.g., a ZIP file) and uploading it to the platform’s storage. The platform then validates the package and prepares it for execution.
- Initialization: Upon the first invocation or when the platform determines it’s needed, the platform initializes the execution environment. This includes provisioning resources (like memory and CPU) and preparing the runtime environment (e.g., installing dependencies, setting up the execution context).
- Invocation: When a trigger event (e.g., an HTTP request, a scheduled event, a message from a queue) occurs, the platform invokes the function. The platform creates a new instance of the execution environment or reuses an existing one. The platform then passes the event data to the function.
- Execution: The function code executes within the provisioned environment. The function processes the event data, performs its intended tasks (e.g., data transformation, business logic execution), and may interact with other cloud services (e.g., databases, storage).
- Termination: After the function completes its execution, the execution environment is either kept alive (warm start) for subsequent invocations or terminated (cold start). The platform manages the resources used by the function and may automatically scale the number of execution environments based on the demand.
Process of Code Deployment and Execution within this Context
The process of deploying and executing code in a serverless context is streamlined to minimize operational overhead. It leverages automation and abstraction to provide a seamless experience for developers.The deployment and execution process can be broken down into the following steps:
- Code Packaging: The developer prepares the function code and its dependencies into a deployable package. This might involve using a build tool to create a ZIP archive or a container image.
- Upload: The developer uploads the deployment package to the serverless platform’s storage. This is typically done through a command-line interface (CLI), a web console, or an API.
- Platform Processing: The serverless platform receives the package and processes it. This may include tasks such as:
- Code Validation: Checking the code for syntax errors and ensuring it meets the platform’s requirements.
- Dependency Management: Resolving and installing dependencies specified in the deployment package.
- Environment Setup: Configuring the execution environment with the necessary resources (e.g., memory, CPU) and runtime (e.g., Node.js, Python).
- Trigger Configuration: The developer configures the triggers that will invoke the function. This might involve specifying an HTTP endpoint, a scheduled event, or a message queue.
- Invocation: When a trigger event occurs, the platform invokes the function. The platform creates or reuses an execution environment, provides the event data to the function, and starts the execution.
- Execution and Resource Allocation: The function code executes within the environment. The serverless platform dynamically allocates resources (e.g., CPU, memory) based on the function’s needs.
- Result Delivery: The function’s output (e.g., a response to an HTTP request, a message to a queue) is delivered to the appropriate destination.
- Monitoring and Logging: The platform automatically monitors the function’s execution and logs events and metrics (e.g., execution time, memory usage, error rates).
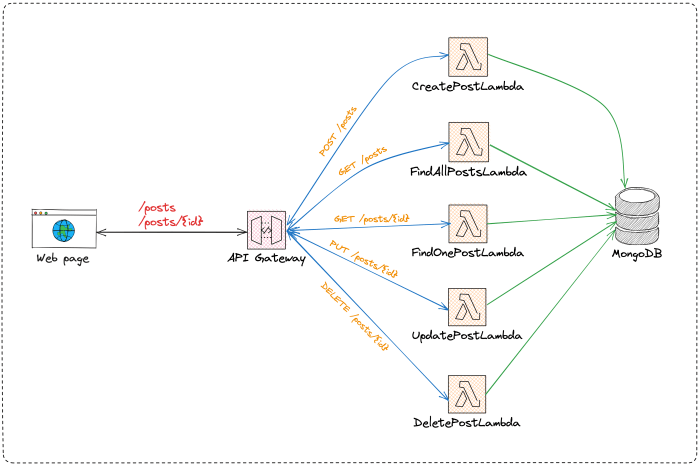
Design of a Simple Diagram Illustrating the Flow of Requests and Responses
A diagram can effectively illustrate the flow of requests and responses within a serverless execution context. The diagram depicts the path a request takes from its origin to the serverless function and back, highlighting key components.The diagram illustrates the following components and their interaction:
+-------------------+ +-----------------------+ +---------------------+ +-------------------+ | Client (e.g., |----->| API Gateway/Trigger |----->| Serverless Function |----->| Cloud Services | | Web Browser) | | (e.g., HTTP Endpoint) | | (Code Execution) | | (e.g., Database) | +-------------------+ +-----------------------+ +---------------------+ +-------------------+ | | | | Request | | Interaction | | | | | | <---------------------------------------------------------|-------------------------| | | | | Response | | | | | +-------------------+ +-----------------------+ +---------------------+ +-------------------+ | Client (e.g., | | API Gateway/Trigger | | Serverless Function | | Cloud Services | | Web Browser) | | (e.g., HTTP Endpoint) | | (Code Execution) | | (e.g., Database) | +-------------------+ +-----------------------+ +---------------------+ +-------------------+
- Client: Represents the origin of the request, such as a web browser, a mobile app, or another service.
- API Gateway/Trigger: This component acts as the entry point for the request. It receives the request, performs authentication and authorization, and routes the request to the appropriate serverless function. Common triggers include HTTP endpoints, message queues, and scheduled events.
- Serverless Function: This is where the function code is executed. The function receives the request, processes it, and interacts with other cloud services.
- Cloud Services: These services provide additional functionality, such as databases, storage, and other cloud resources. The serverless function may interact with these services to perform its tasks.
- Request Flow: The client sends a request to the API Gateway/Trigger. The gateway then invokes the serverless function. The function interacts with cloud services as needed.
- Response Flow: The serverless function returns a response to the API Gateway/Trigger. The gateway then returns the response to the client.
Differences Between Serverless Execution Contexts and Containers
Serverless execution contexts and container-based deployments represent distinct approaches to application deployment and management, each with its own set of characteristics, advantages, and disadvantages. Understanding the key differences between these two paradigms is crucial for making informed decisions about the most suitable technology for a given workload.
Comparison of Serverless Execution Contexts and Container-Based Deployments
The fundamental difference lies in the level of control and management responsibility. Serverless platforms abstract away much of the underlying infrastructure, allowing developers to focus primarily on code. Container-based deployments, on the other hand, provide greater control over the operating environment but require more operational overhead.
| Feature | Serverless Execution Contexts | Container-Based Deployments |
|---|---|---|
| Infrastructure Management | Fully managed by the provider. No server provisioning or maintenance required. | Requires manual or automated infrastructure provisioning and management. |
| Scaling | Automatic and elastic scaling based on demand. Pay-per-use pricing model. | Scaling requires manual configuration and management. More complex pricing models. |
| Resource Allocation | Resources are allocated dynamically as needed. Developers typically do not specify resource limits. | Developers define resource limits (CPU, memory) for each container. |
| Deployment | Simplified deployment process. Code is uploaded and executed. | Requires container image creation, deployment, and orchestration (e.g., Kubernetes). |
| Portability | Highly portable across serverless providers, but may require code changes. | Container images are highly portable across different environments (on-premise, cloud). |
| Cost | Pay-per-execution, often with a fine-grained pricing model. | Can be more cost-effective for long-running workloads; costs are often based on resource usage. |
| Control | Limited control over the underlying infrastructure and operating system. | Provides granular control over the operating environment and application dependencies. |
| Complexity | Reduced operational complexity. Focus on code development. | Increased operational complexity. Requires expertise in containerization and orchestration. |
Use Cases for Serverless Execution Contexts
Serverless execution contexts excel in scenarios where rapid development, automatic scaling, and cost-effectiveness are paramount. They are particularly well-suited for event-driven applications and workloads with unpredictable traffic patterns.
- Web Applications and APIs: Serverless functions can be used to handle API requests, process user input, and serve dynamic content. For example, a simple e-commerce site could use serverless functions for product catalog management, user authentication, and order processing.
- Data Processing and Transformation: Serverless functions can be triggered by events such as file uploads or database updates to perform data processing tasks. This includes tasks such as image resizing, video encoding, and data validation. Consider a social media platform that uses serverless functions to automatically resize images uploaded by users, optimizing them for different devices.
- Backend Services: Serverless functions can be used to build backend services, such as user authentication, data storage, and notification systems. This allows developers to build complex applications without managing servers. For instance, a mobile application could use serverless functions to handle push notifications to users.
- IoT Applications: Serverless functions can be used to process data from IoT devices, perform real-time analytics, and trigger actions based on sensor readings. For example, a smart agriculture system could use serverless functions to analyze data from soil sensors and automatically adjust irrigation levels.
- Scheduled Tasks: Serverless platforms offer capabilities to schedule the execution of functions at specific times or intervals, useful for tasks such as generating reports or sending emails.
Use Cases for Container-Based Deployments
Container-based deployments are favored when applications require a high degree of control over the environment, consistent performance, or the need to manage complex dependencies. They are also ideal for applications that are already containerized.
- Microservices Architectures: Containerization is a natural fit for microservices, enabling independent deployment and scaling of individual services. This facilitates agility and faster release cycles. Consider a large e-commerce platform where different microservices manage product catalogs, shopping carts, and payment processing.
- Stateful Applications: Containers can be used to deploy stateful applications, such as databases and message queues, that require persistent storage and specific configurations. For example, deploying a database like PostgreSQL within a container, ensuring consistent data storage and management.
- Legacy Applications: Containerization provides a way to modernize and migrate legacy applications without significant code changes. This enables organizations to leverage the benefits of cloud infrastructure without rewriting their existing codebases.
- Batch Processing: Containers can be used to run batch processing jobs, such as data analysis and report generation, that require dedicated resources and predictable performance.
- DevOps and CI/CD Pipelines: Containers are used extensively in DevOps and CI/CD pipelines to create consistent and reproducible build and deployment environments. This ensures that applications are built and deployed consistently across different environments.
Serverless Execution Contexts in Various Cloud Providers
The implementation of serverless execution contexts varies significantly across major cloud providers. Each platform, including Amazon Web Services (AWS), Microsoft Azure, and Google Cloud, offers unique features, pricing models, and programming paradigms. Understanding these differences is crucial for developers choosing the most suitable serverless environment for their applications. This section explores the specific implementations of serverless execution contexts within these three cloud giants, focusing on their function invocation costs and supported programming models.
Implementation Across Platforms
Each cloud provider leverages distinct architectural approaches to manage serverless execution contexts. AWS, with its AWS Lambda service, utilizes a container-based model under the hood, though the user experience abstracts away the complexities of container management. Azure Functions, provided by Microsoft, also employs a container-based architecture, offering various hosting plans including consumption plans for pay-per-use billing. Google Cloud Functions, from Google, follows a similar pattern, abstracting the underlying infrastructure.
Comparative Analysis of Function Invocation Costs
Function invocation costs represent a critical factor when choosing a serverless platform. These costs typically encompass resource consumption, such as memory and CPU time, and are usually calculated based on factors like the duration of function execution, the amount of memory allocated, and the number of invocations.
The pricing models differ across the three providers.
- AWS Lambda: Pricing is based on the duration of function execution (in milliseconds), the amount of memory allocated (in GB), and the number of requests. There is a free tier that offers a certain amount of compute time and requests per month. AWS Lambda's pricing structure provides a granular approach, allowing for cost optimization based on specific function requirements. For instance, a function that runs for 100ms and consumes 128MB of memory will be charged differently than a function that runs for 1 second and consumes 512MB.
The pricing is subject to change and depends on the region where the function is deployed.
- Azure Functions: Azure offers a consumption plan, similar to AWS Lambda, where users pay only for the compute resources consumed. The cost is determined by the number of executions, execution time, and memory consumption. The pricing varies depending on the selected region. Azure also offers premium and dedicated plans that provide more control over the infrastructure and can be beneficial for applications with specific performance requirements.
- Google Cloud Functions: Google's pricing model is also based on execution time, memory allocation, and the number of invocations. It includes a free tier, and pricing is region-specific. Google Cloud Functions also provides a "Cloud Functions (2nd gen)" with improved performance and features, with slightly different pricing.
The specific pricing details are subject to change by each cloud provider. The most up-to-date pricing information should be consulted directly from the respective cloud provider's website. Cost comparisons require careful consideration of factors such as expected traffic, function execution times, and memory requirements. For example, a low-traffic application with short-running functions might benefit from the free tier offered by all three providers, while a high-traffic application with longer execution times might require careful optimization and cost analysis to choose the most cost-effective platform.
Differences in Supported Programming Models
The programming models supported by each provider influence the development experience and the types of applications that can be easily built. Each platform supports a range of programming languages and provides specific features and tooling.
- AWS Lambda: Supports a wide array of languages, including Node.js, Python, Java, Go, C#, Ruby, and custom runtimes. AWS Lambda offers a robust ecosystem of integrations with other AWS services, enabling developers to build complex applications that leverage services like S3, DynamoDB, and API Gateway. The Serverless Application Model (SAM) simplifies the deployment and management of serverless applications on AWS.
- Azure Functions: Supports languages like C#, JavaScript, Python, Java, and PowerShell. Azure Functions integrates seamlessly with other Azure services, such as Azure Storage, Azure Cosmos DB, and Azure Event Hubs. It provides a comprehensive set of tools and features for monitoring, debugging, and deployment, including integration with Visual Studio and Azure DevOps.
- Google Cloud Functions: Supports Node.js, Python, Go, Java, .NET, and Ruby. Google Cloud Functions integrates with other Google Cloud services, such as Cloud Storage, Cloud Firestore, and Cloud Pub/Sub. The Google Cloud SDK provides tools for local development, testing, and deployment. The use of Cloud Build simplifies the continuous integration and continuous deployment (CI/CD) process.
The choice of programming model can influence factors such as development speed, maintainability, and performance. For instance, a team familiar with Python might find Google Cloud Functions or AWS Lambda to be a natural fit, while a team experienced with C# might prefer Azure Functions. The available integrations with other cloud services also play a significant role in selecting the most appropriate platform, as they determine how easily serverless functions can interact with other components of the application architecture.
Common Use Cases for Serverless Execution Contexts

Serverless execution contexts offer a versatile solution for various computational tasks, eliminating the need for server management. This paradigm shift enables developers to focus on code rather than infrastructure, leading to increased efficiency and scalability. The following sections Artikel common use cases where serverless execution contexts provide significant advantages.
Common Use Cases
Serverless execution contexts are deployed across a wide range of applications, demonstrating their adaptability. The following list presents some prominent use cases, highlighting their benefits and applicability.
- Web Applications and APIs: Serverless functions can handle backend logic for web applications, APIs, and microservices. They can be triggered by HTTP requests, enabling scalable and cost-effective API deployments.
- Data Processing and Transformation: Tasks such as data cleansing, format conversion, and real-time data analysis are well-suited for serverless execution. These contexts can process data streams from various sources, offering flexibility and responsiveness.
- Event-Driven Architectures: Serverless functions excel in event-driven systems, responding to events from services like databases, message queues, and object storage. This enables building highly reactive and scalable applications.
- IoT Backend: Processing data from IoT devices, managing device interactions, and handling data storage are ideal applications for serverless execution. Serverless functions can scale to accommodate the fluctuating demands of IoT environments.
- Chatbots and Conversational Interfaces: Serverless functions can power the backend logic for chatbots and conversational interfaces, handling user input, processing natural language, and integrating with external services.
- Scheduled Tasks and Automation: Automated tasks, such as data backups, report generation, and periodic data synchronization, can be efficiently managed using serverless functions triggered by scheduled events.
- Mobile Backend: Serverless functions can provide backend services for mobile applications, handling user authentication, data storage, and push notifications, streamlining mobile app development.
API Gateway Integrations
API gateway integrations are a crucial application of serverless execution contexts. This integration provides several benefits.
The integration of serverless execution contexts with API gateways creates a powerful combination for building and managing APIs. API gateways act as a central point of entry for API requests, providing functionalities such as authentication, authorization, rate limiting, and request routing. Serverless functions, in turn, handle the backend logic of the API, processing requests and returning responses. This architecture offers significant advantages in terms of scalability, cost-effectiveness, and developer productivity.
The advantages of serverless execution contexts for API gateway integrations are multifaceted:
- Scalability: Serverless functions automatically scale based on demand, ensuring that APIs can handle fluctuating traffic without manual intervention. API gateways can route incoming requests to multiple instances of serverless functions, distributing the workload efficiently.
- Cost-Effectiveness: With serverless functions, users only pay for the compute time consumed. This pay-per-use model can significantly reduce costs, especially for APIs with unpredictable traffic patterns. API gateways can also provide cost optimization features such as caching and request aggregation.
- Reduced Operational Overhead: Serverless execution contexts eliminate the need for server management, reducing the operational overhead associated with API deployments. Developers can focus on writing code rather than managing infrastructure.
- Faster Development Cycles: Serverless functions can be developed and deployed quickly, accelerating the development cycles for APIs. API gateways can streamline the API management process, providing features such as API versioning, monitoring, and analytics.
- Increased Flexibility: Serverless functions can be written in various programming languages and frameworks, providing flexibility in the choice of technology stack. API gateways can support multiple API protocols, such as HTTP, gRPC, and WebSockets.
Security Considerations within Serverless Execution Contexts
Serverless execution contexts, while offering significant advantages in terms of scalability and operational efficiency, introduce unique security challenges. The ephemeral nature of serverless functions, the distributed architecture, and the shared responsibility model necessitate a different approach to security compared to traditional infrastructure. Understanding these challenges and implementing robust security practices is crucial for protecting data and applications within serverless environments.
Security Challenges Unique to Serverless Execution Contexts
Serverless environments present several security challenges that must be addressed. These challenges arise from the architecture and operational model of serverless computing.
- Shared Responsibility Model Complexity: The shared responsibility model in serverless environments can be more complex than in traditional models. The cloud provider is responsible for the security
-of* the infrastructure (e.g., physical security, underlying operating systems), while the user is responsible for the security
-in* the cloud (e.g., application code, data, IAM roles). Misunderstanding or neglecting aspects of this shared responsibility can lead to vulnerabilities. - Ephemeral Nature of Functions: Serverless functions are typically short-lived, executing only when triggered. This ephemeral nature makes it difficult to apply traditional security controls like persistent monitoring and logging. Security measures must be designed to operate within the function's execution lifecycle.
- Dependency Management: Serverless functions often rely on numerous dependencies (libraries, packages). Managing and securing these dependencies can be challenging, as vulnerabilities in a single dependency can compromise the entire function.
- Attack Surface Expansion: The distributed nature of serverless applications expands the attack surface. Each function, API gateway, and data store represents a potential entry point for attackers. Security must be implemented across all components.
- Limited Visibility and Control: The underlying infrastructure of serverless environments is often abstracted away from the user. This limited visibility and control can make it challenging to monitor and audit security events effectively.
- Event-Driven Architecture Vulnerabilities: Serverless applications are often event-driven, relying on triggers (e.g., HTTP requests, database changes, scheduled events). Exploiting vulnerabilities in these triggers or event handling mechanisms can lead to security breaches.
Best Practices for Securing Code and Data within Serverless Environments
Securing serverless code and data requires a proactive and multi-layered approach. Implementing these best practices can significantly improve the security posture of serverless applications.
- Least Privilege Principle: Grant functions only the necessary permissions to access resources. Avoid granting overly permissive roles that could allow an attacker to escalate privileges.
- Input Validation and Sanitization: Validate and sanitize all input data to prevent injection attacks (e.g., SQL injection, cross-site scripting). Treat all user input as potentially malicious.
- Dependency Management and Vulnerability Scanning: Regularly scan dependencies for known vulnerabilities. Update dependencies promptly to patch security flaws. Use tools to automate dependency management and vulnerability detection.
- Secure Code Practices: Follow secure coding practices to prevent common vulnerabilities. This includes using secure coding standards, conducting code reviews, and performing static and dynamic analysis.
- Encryption: Encrypt data at rest and in transit. Use encryption keys managed by a secure key management service.
- Logging and Monitoring: Implement comprehensive logging and monitoring to detect and respond to security events. Monitor function invocations, API calls, and resource access. Use security information and event management (SIEM) tools to analyze logs and identify anomalies.
- Authentication and Authorization: Implement robust authentication and authorization mechanisms to control access to functions and resources. Use multi-factor authentication (MFA) whenever possible.
- Network Security: Configure network security controls, such as firewalls and virtual private clouds (VPCs), to restrict access to serverless functions and other resources.
- Regular Security Audits and Penetration Testing: Conduct regular security audits and penetration testing to identify and address vulnerabilities. Simulate real-world attacks to assess the effectiveness of security controls.
- Infrastructure as Code (IaC) and Security Automation: Utilize IaC tools to automate the deployment and configuration of infrastructure, including security controls. Automate security checks and vulnerability scans as part of the CI/CD pipeline.
Scenario: Managing Access Control and Permissions
Consider a scenario involving a serverless application that processes customer orders. The application consists of several functions: a function to receive order requests, a function to validate order details, a function to update the inventory, and a function to notify the customer. The application needs to securely manage access control and permissions to protect sensitive data and prevent unauthorized actions.
The access control strategy can be designed as follows:
- IAM Roles: Create specific IAM roles for each function, granting them only the necessary permissions. For example:
- The "OrderRequestFunction" role would have permissions to receive requests from the API gateway and write logs to CloudWatch.
- The "OrderValidationFunction" role would have permissions to read from a database containing product information and write logs to CloudWatch.
- The "InventoryUpdateFunction" role would have permissions to read and write to the inventory database and write logs to CloudWatch.
- The "CustomerNotificationFunction" role would have permissions to send emails using a notification service and write logs to CloudWatch.
- Principle of Least Privilege: Each function's role would only have the permissions required for its specific task. For example, the "OrderValidationFunction" would
not* have permissions to update the inventory.
- API Gateway Authentication: Configure the API gateway to authenticate incoming requests using API keys or other authentication mechanisms. This would ensure that only authorized users or systems can trigger the functions.
- Input Validation and Sanitization: Implement input validation within each function to prevent malicious data from being processed. For example, the "OrderValidationFunction" would validate the order details against a set of predefined rules.
- Data Encryption: Encrypt sensitive data, such as customer information and order details, both at rest and in transit. Use encryption keys managed by a key management service.
- Monitoring and Logging: Implement comprehensive logging and monitoring to track function invocations, API calls, and resource access. Use CloudWatch Logs to store and analyze logs.
- Regular Audits: Conduct regular security audits to review IAM roles, permissions, and security configurations. Identify and remediate any potential vulnerabilities.
By implementing this access control strategy, the application would be able to:
- Restrict access to sensitive data and resources.
- Prevent unauthorized actions.
- Detect and respond to security events.
- Maintain a secure and compliant environment.
Monitoring and Debugging Serverless Execution Contexts
Effectively monitoring and debugging serverless execution contexts is critical for ensuring application performance, identifying and resolving issues, and maintaining overall system health. Serverless environments, by their nature, present unique challenges due to their distributed and ephemeral nature. This section details the tools, techniques, and best practices for gaining visibility into and troubleshooting these complex environments.
Monitoring Serverless Function Performance
Monitoring serverless function performance involves tracking various metrics to assess the health and efficiency of the functions. This data is essential for identifying bottlenecks, optimizing resource utilization, and ensuring that the application meets its performance goals.
- Key Metrics: Several key metrics are essential for effective performance monitoring. These metrics provide insights into various aspects of function execution.
- Invocation Count: The number of times a function is executed. This metric reflects the workload handled by the function.
- Duration: The time taken for a function to complete its execution, from invocation to completion. Analyzing the duration helps identify performance bottlenecks and inefficiencies.
- Cold Start Time: The time taken for a function to initialize a new execution environment (container or instance). This is particularly relevant in serverless environments where functions are often scaled up or down dynamically.
- Errors: The number of times a function fails to execute successfully. Error tracking is essential for identifying and addressing code issues or environmental problems.
- Throttles: The number of times the function execution is throttled due to resource constraints or service limits. Monitoring throttles helps in understanding the capacity limitations and resource allocation issues.
- Concurrency: The number of function instances running concurrently. This metric helps to evaluate the scalability and the load handling capabilities of the function.
- Memory Usage: The amount of memory used by a function during execution. Tracking memory usage helps in optimizing the function's resource consumption.
- CPU Utilization: The amount of CPU resources consumed by a function. This metric is crucial for optimizing performance and identifying CPU-bound bottlenecks.
- Monitoring Tools: Various tools are available for monitoring serverless functions.
- Cloud Provider Native Tools: Most cloud providers offer built-in monitoring services specifically designed for serverless applications. These services typically provide dashboards, metrics, and alerts. For example, AWS CloudWatch, Google Cloud Monitoring, and Azure Monitor provide comprehensive monitoring capabilities for serverless functions.
- Third-Party Monitoring Services: Several third-party monitoring services offer advanced features such as distributed tracing, anomaly detection, and custom dashboards. These services can integrate with various cloud providers and provide a unified view of the application's performance. Examples include Datadog, New Relic, and Dynatrace.
- Custom Monitoring Solutions: Developers can create custom monitoring solutions using their own tools and scripts. This approach offers greater flexibility and control but requires more effort to implement and maintain. This involves collecting metrics from function logs and integrating them into a custom monitoring dashboard.
- Alerting and Notifications: Setting up alerts and notifications is crucial for proactive monitoring.
- Threshold-Based Alerts: Configure alerts based on predefined thresholds for key metrics such as duration, error rate, and memory usage. For example, an alert can be triggered if a function's average duration exceeds a certain threshold.
- Anomaly Detection: Implement anomaly detection to identify unusual patterns in the function's behavior. This helps to detect issues that might not be immediately apparent.
- Notification Channels: Configure notification channels such as email, Slack, or PagerDuty to receive alerts when issues occur. This enables quick response and resolution.
Debugging Issues within a Serverless Environment
Debugging in serverless environments requires a different approach than traditional application debugging. The ephemeral nature of serverless functions, coupled with the distributed architecture, necessitates specialized techniques and tools.
- Logging: Comprehensive logging is essential for debugging serverless functions.
- Structured Logging: Use structured logging formats such as JSON to facilitate parsing and analysis of logs. This makes it easier to search and filter logs.
- Contextual Logging: Include relevant context in logs, such as function name, request ID, and timestamps. This information helps to correlate logs across different function invocations.
- Log Levels: Utilize different log levels (e.g., DEBUG, INFO, WARN, ERROR) to categorize log messages based on their severity. This helps to filter logs and focus on the most relevant information.
- Tracing: Distributed tracing provides visibility into the execution flow across multiple functions and services.
- Tracing Tools: Implement tracing using tools like AWS X-Ray, Google Cloud Trace, or Jaeger. These tools automatically instrument function invocations and generate traces that show the flow of requests through the application.
- Span Context: Propagate span context (trace ID and span ID) across function invocations to correlate traces. This ensures that related events are grouped together in the trace.
- Tracing Analysis: Analyze traces to identify performance bottlenecks, errors, and dependencies between functions. This helps to pinpoint the root cause of issues.
- Local Development and Testing: Local development and testing are essential for debugging code before deploying it to a serverless environment.
- Local Emulators: Use local emulators or mocks to simulate the serverless environment. This allows you to test functions locally without deploying them to the cloud. For example, the AWS SAM CLI can be used to emulate AWS Lambda.
- Unit Tests: Write unit tests to verify the functionality of individual functions. This helps to catch errors early in the development process.
- Integration Tests: Perform integration tests to verify the interaction between functions and other services. This ensures that the functions work together as expected.
- Remote Debugging: Remote debugging allows you to connect to a running function and debug it in real-time.
- Cloud Provider Debugging Tools: Utilize cloud provider-specific debugging tools, such as AWS Lambda debugger or Azure Functions debugger. These tools allow you to set breakpoints, inspect variables, and step through the code.
- Third-Party Debugging Tools: Use third-party debugging tools that integrate with serverless environments. These tools often provide advanced features such as live debugging and performance profiling.
Methods for Logging and Tracing Function Executions
Effective logging and tracing are fundamental for understanding the behavior of serverless functions. Proper implementation ensures that the necessary information is captured and easily accessible for analysis.
- Logging Strategies: Implement comprehensive logging strategies to capture relevant information about function executions.
- Log Levels: Utilize appropriate log levels to categorize log messages based on their severity. For example, use DEBUG for detailed information, INFO for general events, WARN for potential issues, and ERROR for critical errors.
- Contextual Information: Include relevant context in logs, such as function name, request ID, timestamps, and user information. This allows you to correlate logs across multiple function invocations.
- Input and Output Logging: Log function input and output to understand the data flow and identify potential issues. Be cautious about logging sensitive data.
- Error Handling: Implement robust error handling and logging to capture error messages, stack traces, and other relevant information. This is crucial for identifying and resolving issues.
- Tracing Implementation: Integrate tracing into your serverless functions to visualize the execution flow across multiple functions and services.
- Tracing Libraries: Use tracing libraries such as AWS X-Ray SDK, Google Cloud Trace SDK, or OpenTelemetry to instrument your functions. These libraries automatically inject tracing information into function invocations.
- Span Creation: Create spans to represent individual operations or tasks within a function. Each span should include information about the operation, such as the start and end times, and any relevant metadata.
- Propagation of Trace Context: Propagate the trace context (trace ID and span ID) across function invocations to correlate traces. This ensures that related events are grouped together in the trace.
- Data Enrichment: Enrich traces with additional information, such as user IDs, request IDs, and service names. This makes it easier to analyze and understand the traces.
- Log Aggregation and Analysis: Aggregate and analyze logs to gain insights into function behavior and performance.
- Log Aggregation Services: Use log aggregation services such as AWS CloudWatch Logs, Google Cloud Logging, or third-party services like Splunk or ELK stack to collect and store logs.
- Log Search and Filtering: Implement log search and filtering to quickly find specific log messages and identify issues.
- Log Analysis Tools: Utilize log analysis tools to visualize log data and identify trends, anomalies, and performance bottlenecks.
- Log Retention Policies: Define log retention policies to manage log storage costs and ensure that logs are available for the required period.
Serverless Execution Contexts and Event-Driven Architectures
Serverless execution contexts are a natural fit for event-driven architectures, offering a scalable and cost-effective way to react to events in real-time. This integration allows developers to build highly responsive and resilient applications that can handle fluctuating workloads efficiently. The event-driven approach leverages the inherent scalability and pay-per-use model of serverless functions to process events as they occur, eliminating the need for constantly running servers.
Role of Serverless Execution Contexts in Event-Driven Systems
Serverless functions act as the processing units in event-driven architectures, triggered by events from various sources. These sources can include database changes, file uploads, scheduled tasks, or messages from message queues. The serverless execution context provides the environment in which these functions run, handling the underlying infrastructure management, scaling, and resource allocation. This allows developers to focus on the application logic rather than the operational overhead.
Integrating Serverless Functions with Message Queues
Message queues, such as Amazon SQS, Azure Service Bus, and Google Cloud Pub/Sub, serve as intermediaries for asynchronous communication in event-driven systems. Serverless functions can be easily integrated with these queues to process messages. This approach decouples the event producers from the event consumers, improving system resilience and scalability.
- SQS Integration Example: A serverless function can be configured to be triggered whenever a new message arrives in an Amazon SQS queue. The function receives the message as an input and processes it accordingly. For example, a message containing order details could trigger a function to update a customer database, send a confirmation email, and initiate the fulfillment process. The function’s execution context handles the necessary resources for processing the message, such as memory and CPU, based on the function’s configuration and the message’s complexity.
- Service Bus Integration Example: Azure Service Bus offers similar functionality. A serverless function can be subscribed to a Service Bus queue or topic. When a message is published to the queue or topic, the function is triggered. This is commonly used for handling tasks like processing financial transactions, where messages represent individual transactions. The function’s execution environment ensures that the transaction processing is isolated and scalable.
- Pub/Sub Integration Example: Google Cloud Pub/Sub enables real-time event streaming. Serverless functions can be subscribed to Pub/Sub topics. When a message is published to a topic, the function is triggered. This is beneficial for applications like real-time analytics, where events are generated from various sources and need to be processed in real-time. The function's execution context automatically scales to handle the volume of incoming events.
Benefits of Using Serverless Functions for Handling Events
Utilizing serverless functions for event handling provides numerous advantages, contributing to a more efficient and cost-effective architecture.
- Scalability: Serverless platforms automatically scale the number of function instances based on the volume of events, ensuring that the system can handle peak loads without manual intervention. This dynamic scaling contrasts with traditional architectures, where scaling requires proactive planning and resource allocation.
- Cost-Effectiveness: Serverless functions are priced based on the actual execution time and resources consumed. This pay-per-use model eliminates the need to pay for idle resources, leading to significant cost savings compared to traditional server deployments. For example, a system that processes a small number of events during off-peak hours will incur minimal costs, whereas a traditional server would incur costs regardless of usage.
- Reduced Operational Overhead: The serverless platform manages the underlying infrastructure, including server provisioning, patching, and scaling. This allows developers to focus on writing code and building application logic, reducing the operational burden and freeing up resources. This simplifies the development lifecycle and accelerates time-to-market.
- Improved Resilience: Serverless platforms provide built-in fault tolerance and automatic retries. If a function execution fails, the platform automatically retries the execution, ensuring that events are processed even in the event of transient errors. This enhances the reliability and resilience of event-driven systems.
- Faster Development Cycles: The ease of deployment and management of serverless functions allows developers to iterate quickly and deploy new features with minimal effort. This accelerated development cycle leads to faster innovation and quicker responses to changing business requirements.
Future Trends and Innovations in Serverless Execution Contexts
The serverless landscape is dynamic, characterized by continuous innovation driven by the pursuit of enhanced efficiency, scalability, and developer experience. These advancements are significantly impacting serverless execution contexts, reshaping how applications are built, deployed, and managed. Understanding these trends is crucial for anticipating the evolution of serverless computing and leveraging its full potential.
Emerging Trends and Their Impact on Execution Contexts
Several key trends are poised to reshape serverless execution contexts. These advancements necessitate adjustments to how execution environments are provisioned, managed, and optimized.
- Increased Focus on Developer Experience (DX): Serverless platforms are increasingly prioritizing developer productivity. This includes improved tooling, such as enhanced Integrated Development Environments (IDEs), more sophisticated debugging capabilities, and streamlined deployment pipelines. These enhancements translate to more efficient execution contexts, allowing developers to iterate faster and spend less time on infrastructure management. For instance, cloud providers are integrating features like "live code" editing directly within their function consoles, enabling immediate feedback and faster debugging cycles.
- Advanced Observability and Monitoring: The complexity of serverless applications demands sophisticated monitoring and observability solutions. This includes advanced tracing capabilities, improved logging aggregation, and real-time performance analytics. These advancements provide deeper insights into execution context behavior, enabling faster identification and resolution of performance bottlenecks and security vulnerabilities. For example, the integration of distributed tracing tools allows for tracing requests across multiple function invocations and services, facilitating a comprehensive understanding of application performance.
- Specialized Hardware and Acceleration: Serverless platforms are increasingly offering access to specialized hardware, such as GPUs and FPGAs, to accelerate computationally intensive tasks like machine learning and data processing. This requires adapting execution contexts to effectively manage these resources, ensuring efficient allocation and utilization. Consider the example of a serverless image processing function leveraging a GPU for faster image resizing and enhancement, leading to improved performance compared to CPU-bound execution.
- Rise of Serverless Databases and Data Stores: The integration of serverless databases and data stores directly within the execution context simplifies data access and management. These services often offer automatic scaling and pay-per-use pricing models, aligning with the serverless paradigm. An example is the use of a serverless database for storing user profiles, where the database automatically scales based on the number of users and the frequency of data access, eliminating the need for manual database management.
- Edge Computing Integration: Serverless functions are increasingly deployed at the edge, closer to the end-user, to reduce latency and improve responsiveness. This necessitates execution contexts that can efficiently operate in distributed environments with limited resources. For instance, deploying serverless functions at edge locations for content delivery or API gateway functionalities improves response times for users geographically distant from the central data center.
Serverless Execution Contexts in Edge Computing
Edge computing presents unique challenges and opportunities for serverless execution contexts. Deploying serverless functions at the edge brings computation closer to the data source and end-users, reducing latency and improving application responsiveness. However, edge environments often have resource constraints, requiring optimized execution contexts.
- Resource Constraints: Edge devices, such as IoT gateways and edge servers, typically have limited compute power, memory, and storage compared to cloud data centers. Serverless execution contexts must be designed to operate efficiently within these constraints, minimizing resource consumption.
- Network Latency: Edge deployments are often characterized by unreliable network connections and high latency. Serverless functions must be optimized to minimize the impact of network latency, such as by caching data locally or pre-fetching data.
- Data Proximity: Edge computing allows for processing data closer to its source, reducing the need to transfer large volumes of data to the cloud. Serverless execution contexts can be used to perform real-time data analysis and filtering at the edge, reducing the bandwidth requirements.
- Security Considerations: Edge environments can be vulnerable to security threats. Serverless execution contexts must be secured to protect against attacks. This includes implementing robust authentication and authorization mechanisms, as well as regularly updating the execution environment with security patches.
- Examples of Edge Computing Use Cases:
- Content Delivery Networks (CDNs): Serverless functions can be used to cache content at the edge, reducing latency for users.
- IoT Device Management: Serverless functions can be used to process data from IoT devices, enabling real-time monitoring and control.
- Video Streaming: Serverless functions can be used to transcode video streams at the edge, optimizing them for different devices and network conditions.
Predictions for the Evolution of Serverless Execution Contexts Over the Next Five Years
Predicting the future is inherently complex, but several trends suggest how serverless execution contexts will evolve over the next five years. These predictions are based on current trends, technological advancements, and the evolving needs of developers and businesses.
- Increased Automation and Abstraction: Serverless platforms will continue to abstract away infrastructure management, making it even easier for developers to build and deploy applications. This will include automated scaling, self-healing capabilities, and intelligent resource allocation. We will likely see the emergence of "serverless-as-a-service" offerings, where even the underlying execution context is managed by the cloud provider, removing the need for developers to configure or manage any infrastructure components.
- Enhanced Support for Stateful Applications: While serverless has traditionally been associated with stateless functions, there will be increased support for stateful applications. This includes improved mechanisms for managing state, such as durable queues, managed databases, and distributed caching. We can anticipate serverless frameworks that seamlessly integrate with stateful services, allowing developers to build complex applications that require persistent data storage and session management.
- Serverless-First Development: Serverless will become the default approach for building new applications, with serverless platforms offering a comprehensive suite of services, including compute, storage, databases, and networking. We will see the emergence of new programming models and frameworks specifically designed for serverless development, streamlining the development process and maximizing developer productivity.
- Improved Security and Compliance: Security will remain a top priority, with serverless platforms incorporating advanced security features, such as automated vulnerability scanning, intrusion detection, and compliance certifications. We will see a greater focus on security best practices and automated security configurations, ensuring that serverless applications are secure by default.
- Wider Adoption of Edge Computing: Edge computing will become increasingly prevalent, with serverless functions playing a crucial role in enabling low-latency applications and distributed data processing. We will see the development of specialized serverless platforms optimized for edge deployments, enabling developers to build and deploy applications at the edge with ease.
- Greater Focus on Sustainability: As environmental concerns grow, serverless platforms will focus on energy efficiency and sustainable computing practices. This will involve optimizing resource utilization, reducing energy consumption, and promoting the use of renewable energy sources. We might observe serverless platforms offering carbon footprint tracking and reporting tools, empowering developers to build environmentally friendly applications.
Wrap-Up

In conclusion, the serverless execution context provides a compelling solution for modern application development, offering unparalleled scalability, cost efficiency, and developer productivity. By understanding the intricacies of its operation, security considerations, and integration with various cloud platforms, developers can harness its power to build robust, scalable, and event-driven applications. As the industry continues to evolve, serverless computing will undoubtedly play a pivotal role, driving innovation and shaping the future of software development.
This exploration highlights the importance of understanding and leveraging serverless execution contexts to build efficient and scalable applications.
Essential FAQs
What is the primary advantage of using a serverless execution context?
The primary advantage is the elimination of server management, leading to reduced operational overhead, automatic scaling, and cost optimization through pay-per-use pricing.
How does a serverless execution context handle scaling?
Serverless platforms automatically scale resources based on demand, dynamically allocating more instances of the function to handle incoming requests without requiring manual intervention.
What are the potential drawbacks of serverless execution contexts?
Potential drawbacks include vendor lock-in, limitations on execution time and memory, cold starts (initial latency), and debugging complexities.
Are serverless execution contexts suitable for all types of applications?
While serverless is ideal for many use cases, it might not be the best fit for applications with extremely high computational requirements, real-time processing needs, or those requiring persistent connections.